 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMegaScience: Pushing the Frontiers of Post-Training Datasets for Science Reasoning
Jul 22, 2025



Scientific reasoning is critical for developing AI scientists and supporting human researchers in advancing the frontiers of natural science discovery. However, the open-source community has primarily focused on mathematics and coding while neglecting the scientific domain, largely due to the absence of open, large-scale, high-quality, verifiable scientific reasoning datasets. To bridge this gap, we first present TextbookReasoning, an open dataset featuring truthful reference answers extracted from 12k university-level scientific textbooks, comprising 650k reasoning questions spanning 7 scientific disciplines. We further introduce MegaScience, a large-scale mixture of high-quality open-source datasets totaling 1.25 million instances, developed through systematic ablation studies that evaluate various data selection methodologies to identify the optimal subset for each publicly available scientific dataset. Meanwhile, we build a comprehensive evaluation system covering diverse subjects and question types across 15 benchmarks, incorporating comprehensive answer extraction strategies to ensure accurate evaluation metrics. Our experiments demonstrate that our datasets achieve superior performance and training efficiency with more concise response lengths compared to existing open-source scientific datasets. Furthermore, we train Llama3.1, Qwen2.5, and Qwen3 series base models on MegaScience, which significantly outperform the corresponding official instruct models in average performance. In addition, MegaScience exhibits greater effectiveness for larger and stronger models, suggesting a scaling benefit for scientific tuning. We release our data curation pipeline, evaluation system, datasets, and seven trained models to the community to advance scientific reasoning research.
Generative AI Act II: Test Time Scaling Drives Cognition Engineering
Apr 21, 2025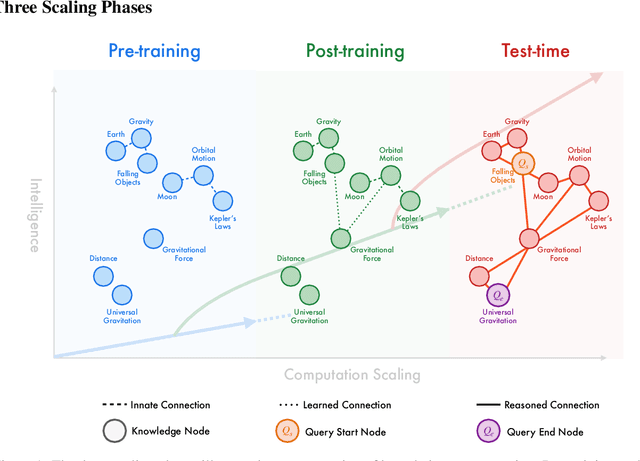
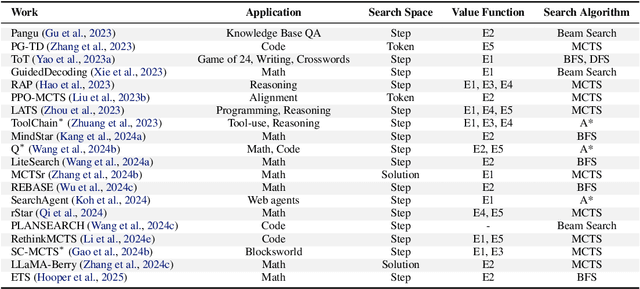
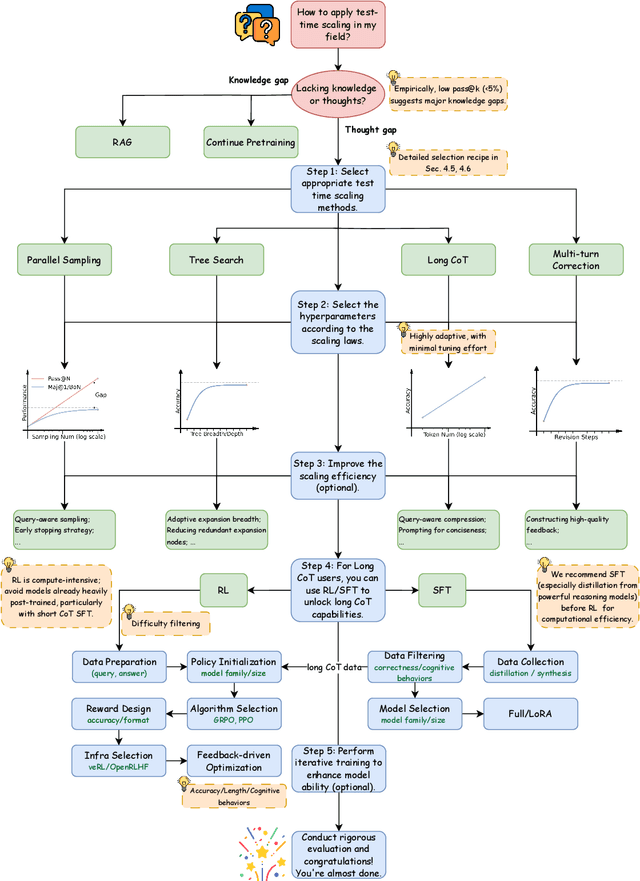
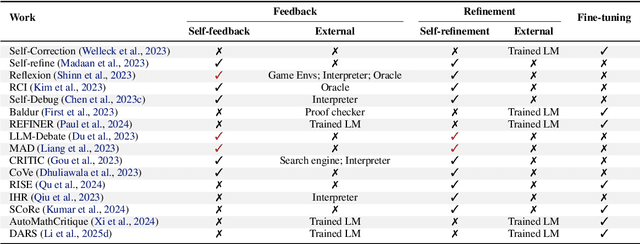
The first generation of Large Language Models - what might be called "Act I" of generative AI (2020-2023) - achieved remarkable success through massive parameter and data scaling, yet exhibited fundamental limitations such as knowledge latency, shallow reasoning, and constrained cognitive processes. During this era, prompt engineering emerged as our primary interface with AI, enabling dialogue-level communication through natural language. We now witness the emergence of "Act II" (2024-present), where models are transitioning from knowledge-retrieval systems (in latent space) to thought-construction engines through test-time scaling techniques. This new paradigm establishes a mind-level connection with AI through language-based thoughts. In this paper, we clarify the conceptual foundations of cognition engineering and explain why this moment is critical for its development. We systematically break down these advanced approaches through comprehensive tutorials and optimized implementations, democratizing access to cognition engineering and enabling every practitioner to participate in AI's second act. We provide a regularly updated collection of papers on test-time scaling in the GitHub Repository: https://github.com/GAIR-NLP/cognition-engineering
Data Contamination Report from the 2024 CONDA Shared Task
Jul 31, 2024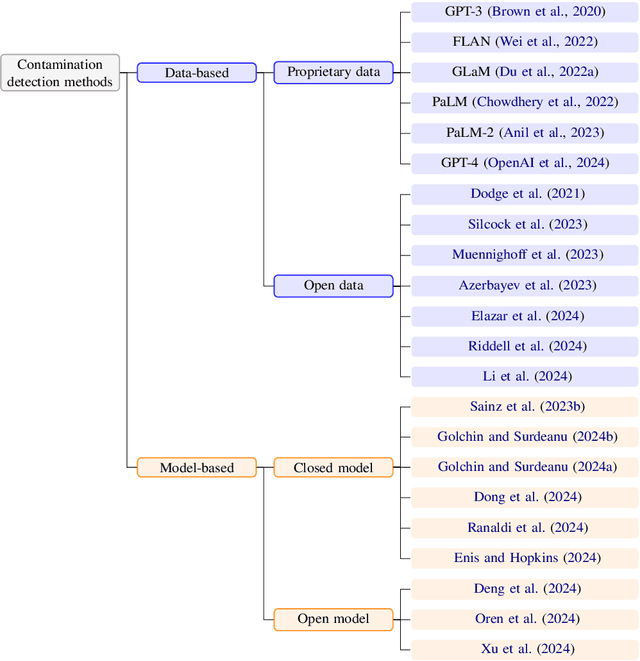
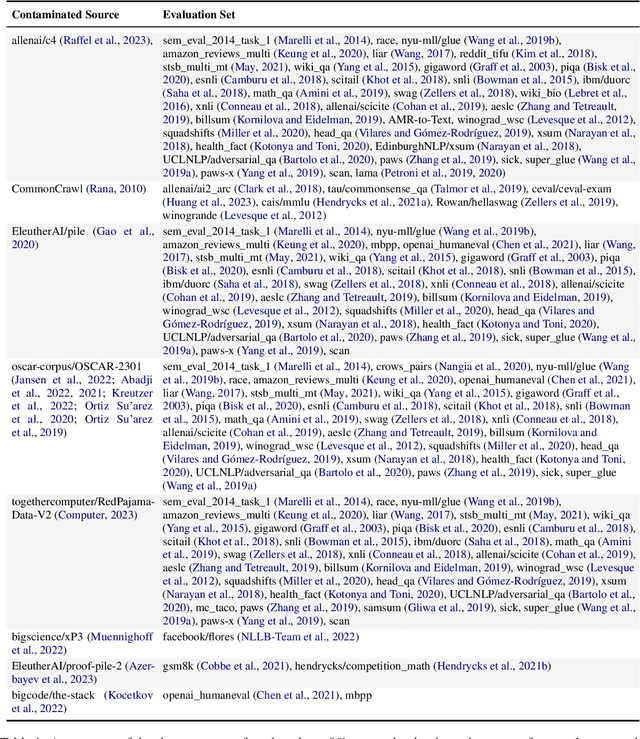
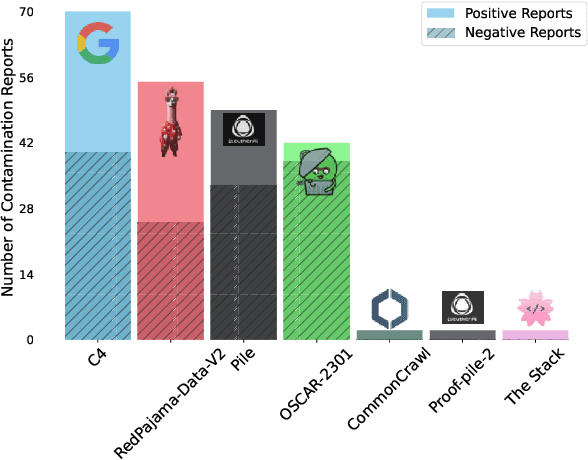
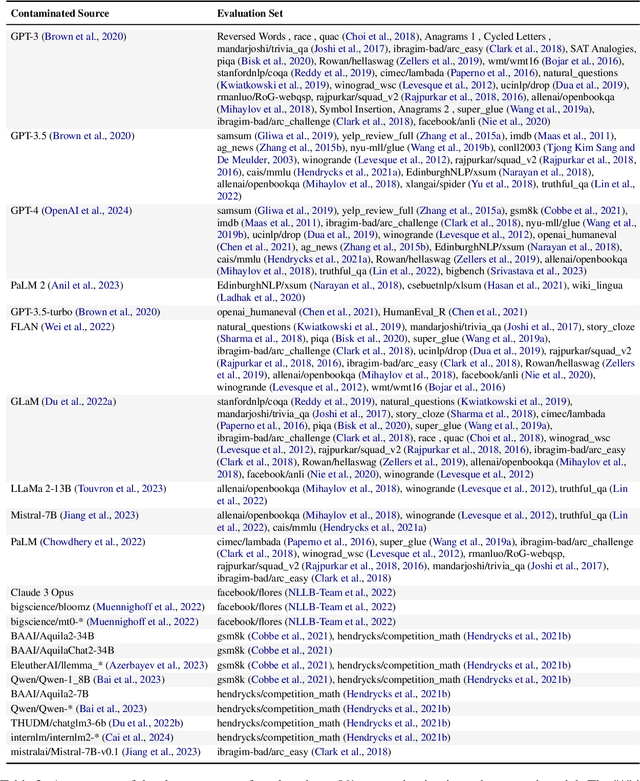
The 1st Workshop on Data Contamination (CONDA 2024) focuses on all relevant aspects of data contamination in natural language processing, where data contamination is understood as situations where evaluation data is included in pre-training corpora used to train large scale models, compromising evaluation results. The workshop fostered a shared task to collect evidence on data contamination in current available datasets and models. The goal of the shared task and associated database is to assist the community in understanding the extent of the problem and to assist researchers in avoiding reporting evaluation results on known contaminated resources. The shared task provides a structured, centralized public database for the collection of contamination evidence, open to contributions from the community via GitHub pool requests. This first compilation paper is based on 566 reported entries over 91 contaminated sources from a total of 23 contributors. The details of the individual contamination events are available in the platform. The platform continues to be online, open to contributions from the community.
OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent AI
Jun 18, 2024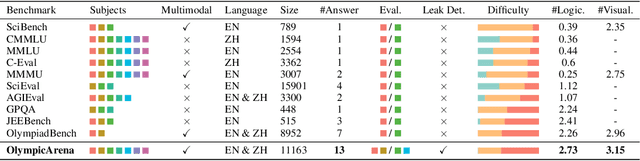
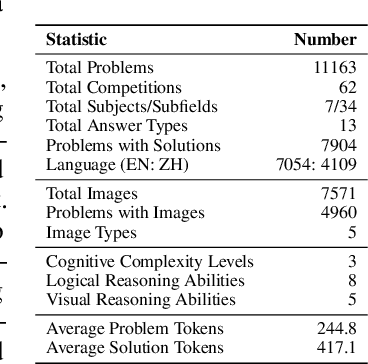
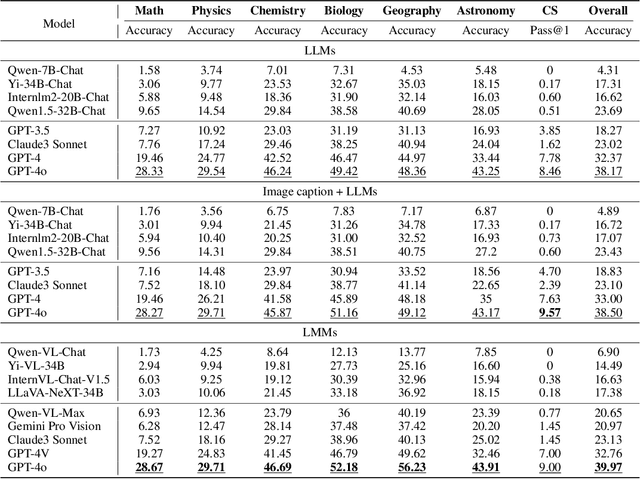
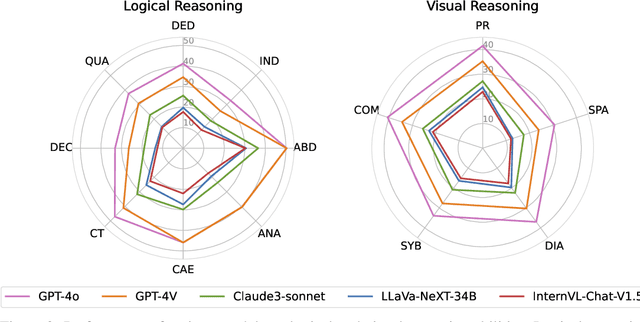
The evolution of Artificial Intelligence (AI) has been significantly accelerated by advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), gradually showcasing potential cognitive reasoning abilities in problem-solving and scientific discovery (i.e., AI4Science) once exclusive to human intellect. To comprehensively evaluate current models' performance in cognitive reasoning abilities, we introduce OlympicArena, which includes 11,163 bilingual problems across both text-only and interleaved text-image modalities. These challenges encompass a wide range of disciplines spanning seven fields and 62 international Olympic competitions, rigorously examined for data leakage. We argue that the challenges in Olympic competition problems are ideal for evaluating AI's cognitive reasoning due to their complexity and interdisciplinary nature, which are essential for tackling complex scientific challenges and facilitating discoveries. Beyond evaluating performance across various disciplines using answer-only criteria, we conduct detailed experiments and analyses from multiple perspectives. We delve into the models' cognitive reasoning abilities, their performance across different modalities, and their outcomes in process-level evaluations, which are vital for tasks requiring complex reasoning with lengthy solutions. Our extensive evaluations reveal that even advanced models like GPT-4o only achieve a 39.97% overall accuracy, illustrating current AI limitations in complex reasoning and multimodal integration. Through the OlympicArena, we aim to advance AI towards superintelligence, equipping it to address more complex challenges in science and beyond. We also provide a comprehensive set of resources to support AI research, including a benchmark dataset, an open-source annotation platform, a detailed evaluation tool, and a leaderboard with automatic submission features.
Benchmarking Benchmark Leakage in Large Language Models
Apr 29, 2024



Amid the expanding use of pre-training data, the phenomenon of benchmark dataset leakage has become increasingly prominent, exacerbated by opaque training processes and the often undisclosed inclusion of supervised data in contemporary Large Language Models (LLMs). This issue skews benchmark effectiveness and fosters potentially unfair comparisons, impeding the field's healthy development. To address this, we introduce a detection pipeline utilizing Perplexity and N-gram accuracy, two simple and scalable metrics that gauge a model's prediction precision on benchmark, to identify potential data leakages. By analyzing 31 LLMs under the context of mathematical reasoning, we reveal substantial instances of training even test set misuse, resulting in potentially unfair comparisons. These findings prompt us to offer several recommendations regarding model documentation, benchmark setup, and future evaluations. Notably, we propose the "Benchmark Transparency Card" to encourage clear documentation of benchmark utilization, promoting transparency and healthy developments of LLMs. we have made our leaderboard, pipeline implementation, and model predictions publicly available, fostering future research.
Reformatted Alignment
Feb 19, 2024The quality of finetuning data is crucial for aligning large language models (LLMs) with human values. Current methods to improve data quality are either labor-intensive or prone to factual errors caused by LLM hallucinations. This paper explores elevating the quality of existing instruction data to better align with human values, introducing a simple and effective approach named ReAlign, which reformats the responses of instruction data into a format that better aligns with pre-established criteria and the collated evidence. This approach minimizes human annotation, hallucination, and the difficulty in scaling, remaining orthogonal to existing alignment techniques. Experimentally, ReAlign significantly boosts the general alignment ability, math reasoning, factuality, and readability of the LLMs. Encouragingly, without introducing any additional data or advanced training techniques, and merely by reformatting the response, LLaMA-2-13B's mathematical reasoning ability on GSM8K can be improved from 46.77% to 56.63% in accuracy. Additionally, a mere 5% of ReAlign data yields a 67% boost in general alignment ability measured by the Alpaca dataset. This work highlights the need for further research into the science and mechanistic interpretability of LLMs. We have made the associated code and data publicly accessible to support future studies at https://github.com/GAIR-NLP/ReAlign.
RIGHT: Retrieval-augmented Generation for Mainstream Hashtag Recommendation
Dec 16, 2023



Automatic mainstream hashtag recommendation aims to accurately provide users with concise and popular topical hashtags before publication. Generally, mainstream hashtag recommendation faces challenges in the comprehensive difficulty of newly posted tweets in response to new topics, and the accurate identification of mainstream hashtags beyond semantic correctness. However, previous retrieval-based methods based on a fixed predefined mainstream hashtag list excel in producing mainstream hashtags, but fail to understand the constant flow of up-to-date information. Conversely, generation-based methods demonstrate a superior ability to comprehend newly posted tweets, but their capacity is constrained to identifying mainstream hashtags without additional features. Inspired by the recent success of the retrieval-augmented technique, in this work, we attempt to adopt this framework to combine the advantages of both approaches. Meantime, with the help of the generator component, we could rethink how to further improve the quality of the retriever component at a low cost. Therefore, we propose RetrIeval-augmented Generative Mainstream HashTag Recommender (RIGHT), which consists of three components: 1) a retriever seeks relevant hashtags from the entire tweet-hashtags set; 2) a selector enhances mainstream identification by introducing global signals; and 3) a generator incorporates input tweets and selected hashtags to directly generate the desired hashtags. The experimental results show that our method achieves significant improvements over state-of-the-art baselines. Moreover, RIGHT can be easily integrated into large language models, improving the performance of ChatGPT by more than 10%.
Merging Experts into One: Improving Computational Efficiency of Mixture of Experts
Oct 22, 2023Scaling the size of language models usually leads to remarkable advancements in NLP tasks. But it often comes with a price of growing computational cost. Although a sparse Mixture of Experts (MoE) can reduce the cost by activating a small subset of parameters (e.g., one expert) for each input, its computation escalates significantly if increasing the number of activated experts, limiting its practical utility. Can we retain the advantages of adding more experts without substantially increasing the computational costs? In this paper, we first demonstrate the superiority of selecting multiple experts and then propose a computation-efficient approach called \textbf{\texttt{Merging Experts into One}} (MEO), which reduces the computation cost to that of a single expert. Extensive experiments show that MEO significantly improves computational efficiency, e.g., FLOPS drops from 72.0G of vanilla MoE to 28.6G (MEO). Moreover, we propose a token-level attention block that further enhances the efficiency and performance of token-level MEO, e.g., 83.3\% (MEO) vs. 82.6\% (vanilla MoE) average score on the GLUE benchmark. Our code will be released upon acceptance. Code will be released at: \url{https://github.com/Shwai-He/MEO}.
Generative Judge for Evaluating Alignment
Oct 09, 2023



The rapid development of Large Language Models (LLMs) has substantially expanded the range of tasks they can address. In the field of Natural Language Processing (NLP), researchers have shifted their focus from conventional NLP tasks (e.g., sequence tagging and parsing) towards tasks that revolve around aligning with human needs (e.g., brainstorming and email writing). This shift in task distribution imposes new requirements on evaluating these aligned models regarding generality (i.e., assessing performance across diverse scenarios), flexibility (i.e., examining under different protocols), and interpretability (i.e., scrutinizing models with explanations). In this paper, we propose a generative judge with 13B parameters, Auto-J, designed to address these challenges. Our model is trained on user queries and LLM-generated responses under massive real-world scenarios and accommodates diverse evaluation protocols (e.g., pairwise response comparison and single-response evaluation) with well-structured natural language critiques. To demonstrate the efficacy of our approach, we construct a new testbed covering 58 different scenarios. Experimentally, Auto-J outperforms a series of strong competitors, including both open-source and closed-source models, by a large margin. We also provide detailed analysis and case studies to further reveal the potential of our method and make a variety of resources public at https://github.com/GAIR-NLP/auto-j.
MerA: Merging Pretrained Adapters For Few-Shot Learning
Aug 30, 2023Adapter tuning, which updates only a few parameters, has become a mainstream method for fine-tuning pretrained language models to downstream tasks. However, it often yields subpar results in few-shot learning. AdapterFusion, which assembles pretrained adapters using composition layers tailored to specific tasks, is a possible solution but significantly increases trainable parameters and deployment costs. Despite this, our preliminary study reveals that even single adapters can outperform Adapterfusion in few-shot learning, urging us to propose \textbf{\texttt{Merging Pretrained Adapters}} (MerA) that efficiently incorporates pretrained adapters to a single model through model fusion. Extensive experiments on two PLMs demonstrate that MerA achieves substantial improvements compared to both single adapters and AdapterFusion. To further enhance the capacity of MerA, we also introduce a simple yet effective technique, referred to as the "\textit{same-track}" setting, that merges adapters from the same track of pretraining tasks. With the implementation of the "\textit{same-track}" setting, we observe even more impressive gains, surpassing the performance of both full fine-tuning and adapter tuning by a substantial margin, e.g., 3.5\% in MRPC and 5.0\% in MNLI.