 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI Act II: Test Time Scaling Drives Cognition Engineering
Apr 21, 2025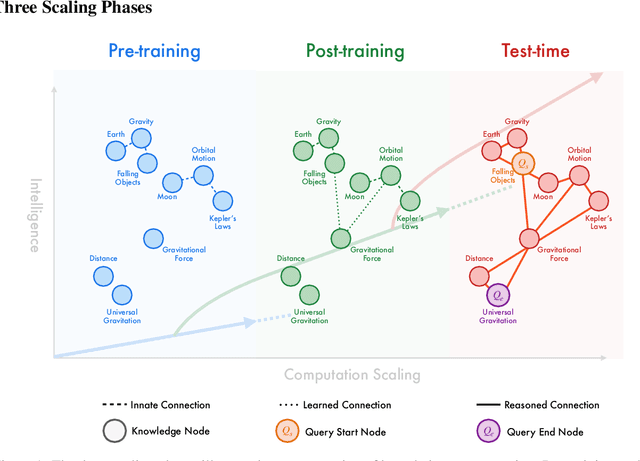
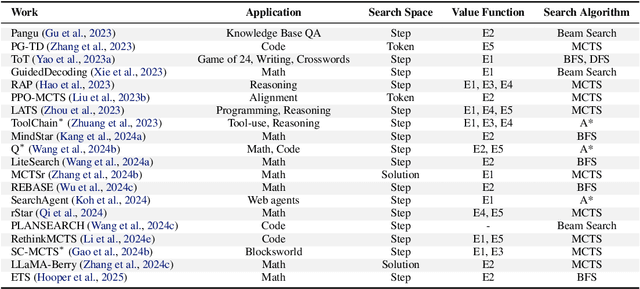
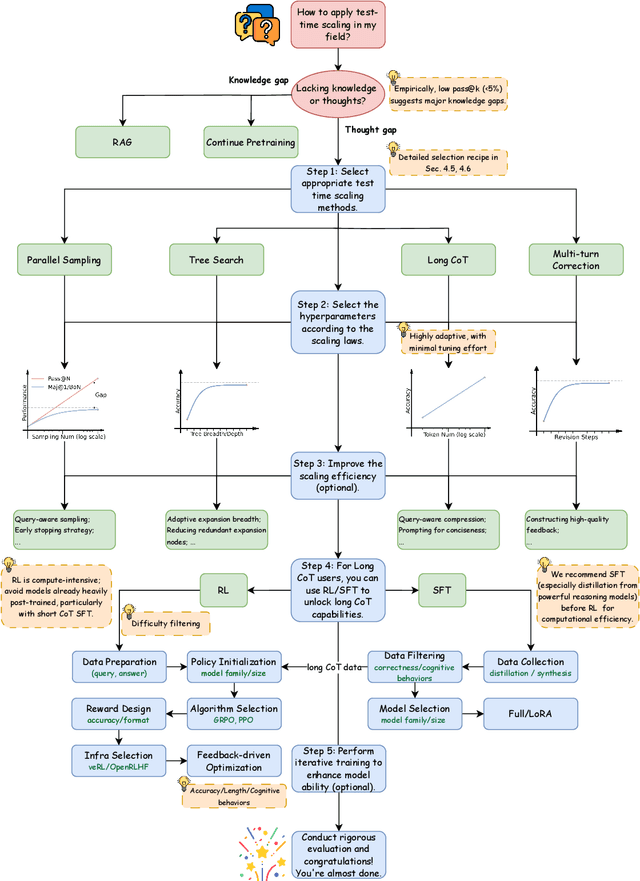
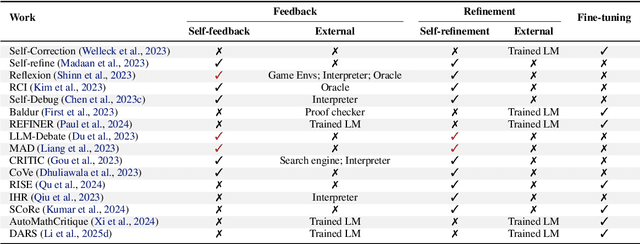
The first generation of Large Language Models - what might be called "Act I" of generative AI (2020-2023) - achieved remarkable success through massive parameter and data scaling, yet exhibited fundamental limitations such as knowledge latency, shallow reasoning, and constrained cognitive processes. During this era, prompt engineering emerged as our primary interface with AI, enabling dialogue-level communication through natural language. We now witness the emergence of "Act II" (2024-present), where models are transitioning from knowledge-retrieval systems (in latent space) to thought-construction engines through test-time scaling techniques. This new paradigm establishes a mind-level connection with AI through language-based thoughts. In this paper, we clarify the conceptual foundations of cognition engineering and explain why this moment is critical for its development. We systematically break down these advanced approaches through comprehensive tutorials and optimized implementations, democratizing access to cognition engineering and enabling every practitioner to participate in AI's second act. We provide a regularly updated collection of papers on test-time scaling in the GitHub Repository: https://github.com/GAIR-NLP/cognition-engineering
DIVE: Diversified Iterative Self-Improvement
Jan 01, 2025Recent advances in large language models (LLMs) have demonstrated the effectiveness of Iterative Self-Improvement (ISI) techniques. However, continuous training on self-generated data leads to reduced output diversity, a limitation particularly critical in reasoning tasks where diverse solution paths are essential. We present DIVE (Diversified Iterative Self-Improvement), a novel framework that addresses this challenge through two key components: Sample Pool Expansion for broader solution exploration, and Data Selection for balancing diversity and quality in preference pairs. Experiments on MATH and GSM8k datasets show that DIVE achieves a 10% to 45% relative increase in output diversity metrics while maintaining performance quality compared to vanilla ISI. Our ablation studies confirm both components' significance in achieving these improvements. Code is available at https://github.com/qinyiwei/DIVE.
O1 Replication Journey -- Part 2: Surpassing O1-preview through Simple Distillation, Big Progress or Bitter Lesson?
Nov 25, 2024This paper presents a critical examination of current approaches to replicating OpenAI's O1 model capabilities, with particular focus on the widespread but often undisclosed use of knowledge distillation techniques. While our previous work explored the fundamental technical path to O1 replication, this study reveals how simple distillation from O1's API, combined with supervised fine-tuning, can achieve superior performance on complex mathematical reasoning tasks. Through extensive experiments, we show that a base model fine-tuned on simply tens of thousands of samples O1-distilled long-thought chains outperforms O1-preview on the American Invitational Mathematics Examination (AIME) with minimal technical complexity. Moreover, our investigation extends beyond mathematical reasoning to explore the generalization capabilities of O1-distilled models across diverse tasks: hallucination, safety and open-domain QA. Notably, despite training only on mathematical problem-solving data, our models demonstrated strong generalization to open-ended QA tasks and became significantly less susceptible to sycophancy after fine-tuning. We deliberately make this finding public to promote transparency in AI research and to challenge the current trend of obscured technical claims in the field. Our work includes: (1) A detailed technical exposition of the distillation process and its effectiveness, (2) A comprehensive benchmark framework for evaluating and categorizing O1 replication attempts based on their technical transparency and reproducibility, (3) A critical discussion of the limitations and potential risks of over-relying on distillation approaches, our analysis culminates in a crucial bitter lesson: while the pursuit of more capable AI systems is important, the development of researchers grounded in first-principles thinking is paramount.
OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent AI
Jun 18, 2024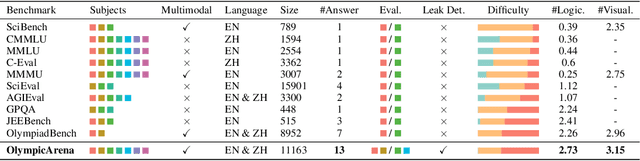
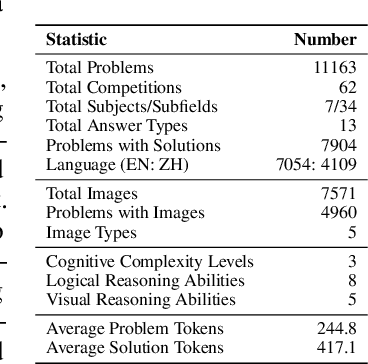
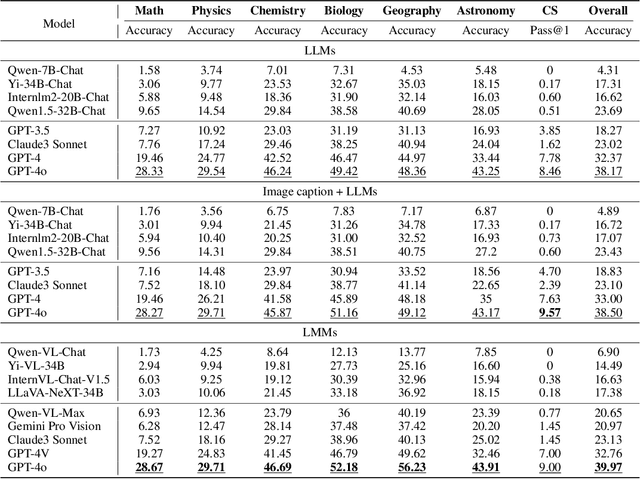
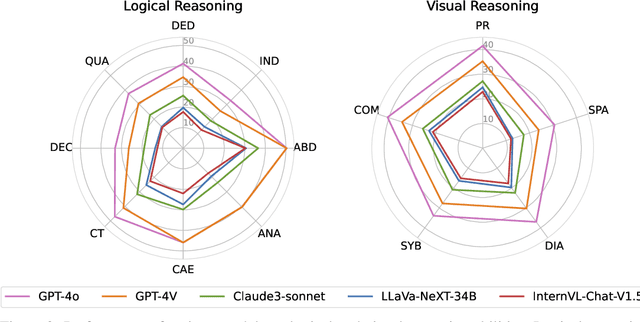
The evolution of Artificial Intelligence (AI) has been significantly accelerated by advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), gradually showcasing potential cognitive reasoning abilities in problem-solving and scientific discovery (i.e., AI4Science) once exclusive to human intellect. To comprehensively evaluate current models' performance in cognitive reasoning abilities, we introduce OlympicArena, which includes 11,163 bilingual problems across both text-only and interleaved text-image modalities. These challenges encompass a wide range of disciplines spanning seven fields and 62 international Olympic competitions, rigorously examined for data leakage. We argue that the challenges in Olympic competition problems are ideal for evaluating AI's cognitive reasoning due to their complexity and interdisciplinary nature, which are essential for tackling complex scientific challenges and facilitating discoveries. Beyond evaluating performance across various disciplines using answer-only criteria, we conduct detailed experiments and analyses from multiple perspectives. We delve into the models' cognitive reasoning abilities, their performance across different modalities, and their outcomes in process-level evaluations, which are vital for tasks requiring complex reasoning with lengthy solutions. Our extensive evaluations reveal that even advanced models like GPT-4o only achieve a 39.97% overall accuracy, illustrating current AI limitations in complex reasoning and multimodal integration. Through the OlympicArena, we aim to advance AI towards superintelligence, equipping it to address more complex challenges in science and beyond. We also provide a comprehensive set of resources to support AI research, including a benchmark dataset, an open-source annotation platform, a detailed evaluation tool, and a leaderboard with automatic submission features.
InFoBench: Evaluating Instruction Following Ability in Large Language Models
Jan 07, 2024This paper introduces the Decomposed Requirements Following Ratio (DRFR), a new metric for evaluating Large Language Models' (LLMs) ability to follow instructions. Addressing a gap in current methodologies, DRFR breaks down complex instructions into simpler criteria, facilitating a detailed analysis of LLMs' compliance with various aspects of tasks. Alongside this metric, we present InFoBench, a benchmark comprising 500 diverse instructions and 2,250 decomposed questions across multiple constraint categories. Our experiments compare DRFR with traditional scoring methods and explore annotation sources, including human experts, crowd-sourced workers, and GPT-4. The findings demonstrate DRFR's higher reliability and the effectiveness of using GPT-4 as a cost-efficient annotator. The evaluation of several advanced LLMs using this framework reveals their strengths and areas needing improvement, particularly in complex instruction-following. This study contributes a novel metric and benchmark, offering insights for future LLM development and evaluation.
T5Score: Discriminative Fine-tuning of Generative Evaluation Metrics
Dec 12, 2022Modern embedding-based metrics for evaluation of generated text generally fall into one of two paradigms: discriminative metrics that are trained to directly predict which outputs are of higher quality according to supervised human annotations, and generative metrics that are trained to evaluate text based on the probabilities of a generative model. Both have their advantages; discriminative metrics are able to directly optimize for the problem of distinguishing between good and bad outputs, while generative metrics can be trained using abundant raw text. In this paper, we present a framework that combines the best of both worlds, using both supervised and unsupervised signals from whatever data we have available. We operationalize this idea by training T5Score, a metric that uses these training signals with mT5 as the backbone. We perform an extensive empirical comparison with other existing metrics on 5 datasets, 19 languages and 280 systems, demonstrating the utility of our method. Experimental results show that: T5Score achieves the best performance on all datasets against existing top-scoring metrics at the segment level. We release our code and models at https://github.com/qinyiwei/T5Score.
Searching for Effective Multilingual Fine-Tuning Methods: A Case Study in Summarization
Dec 12, 2022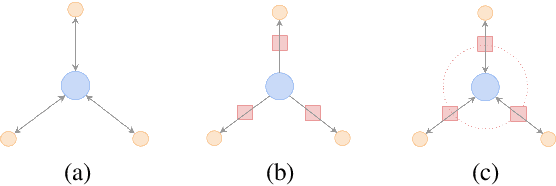
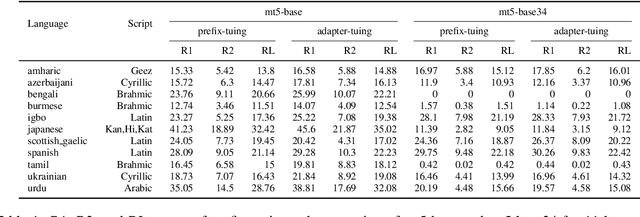
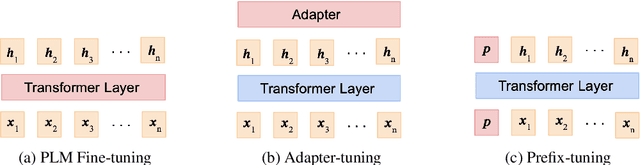
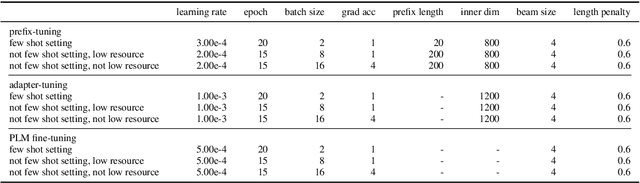
Recently, a large number of tuning strategies have been proposed to adapt pre-trained language models to downstream tasks. In this paper, we perform an extensive empirical evaluation of various tuning strategies for multilingual learning, particularly in the context of text summarization. Specifically, we explore the relative advantages of three families of multilingual tuning strategies (a total of five models) and empirically evaluate them for summarization over 45 languages. Experimentally, we not only established a new state-of-the-art on the XL-Sum dataset but also derive a series of observations that hopefully can provide hints for future research on the design of multilingual tuning strategies.