Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching for Effective Multilingual Fine-Tuning Methods: A Case Study in Summarization
Paper and Code
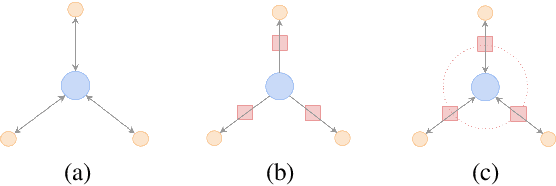
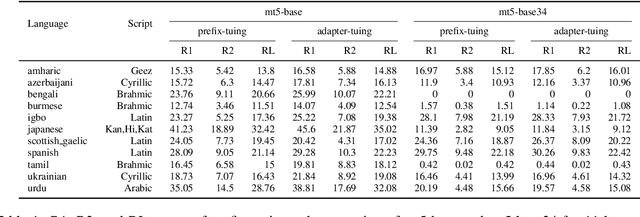
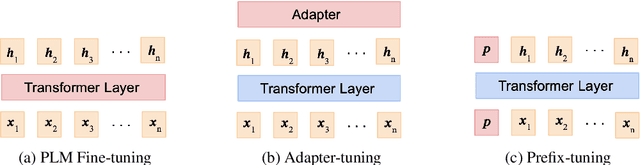
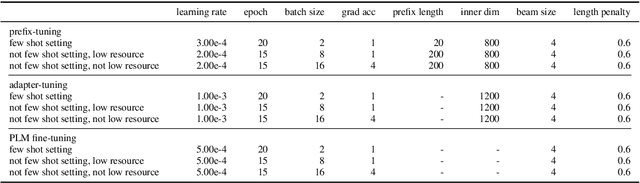
Recently, a large number of tuning strategies have been proposed to adapt pre-trained language models to downstream tasks. In this paper, we perform an extensive empirical evaluation of various tuning strategies for multilingual learning, particularly in the context of text summarization. Specifically, we explore the relative advantages of three families of multilingual tuning strategies (a total of five models) and empirically evaluate them for summarization over 45 languages. Experimentally, we not only established a new state-of-the-art on the XL-Sum dataset but also derive a series of observations that hopefully can provide hints for future research on the design of multilingual tuning strategies.
View paper on