 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaGo Moment for Model Architecture Discovery
Jul 24, 2025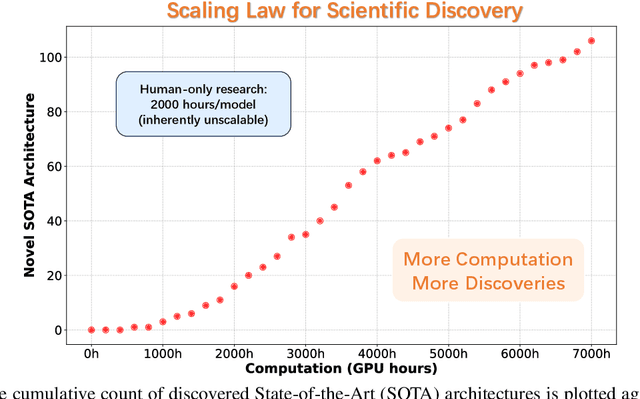
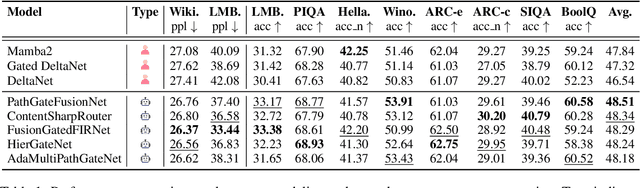
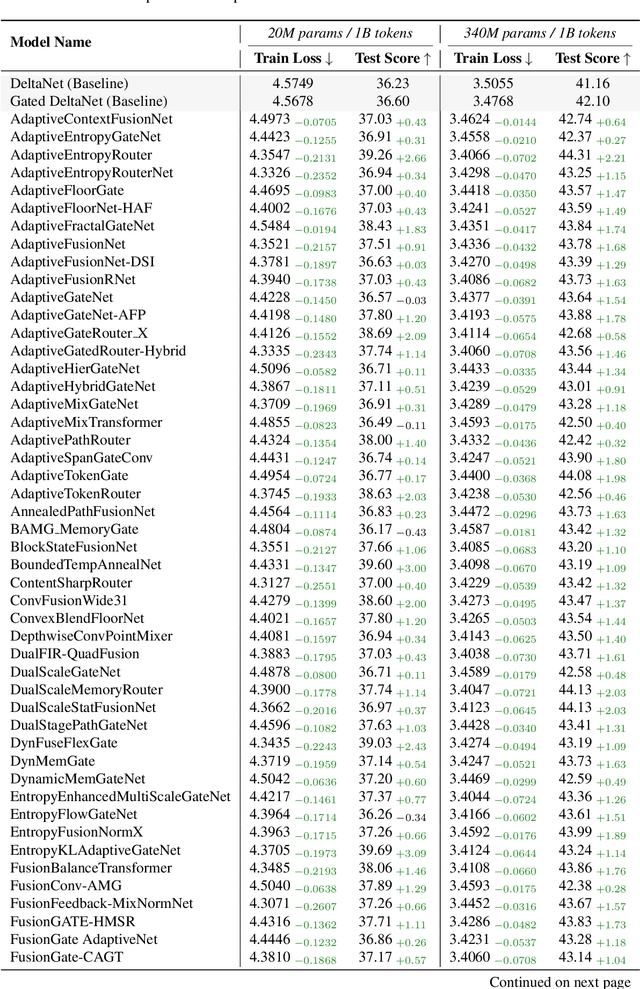
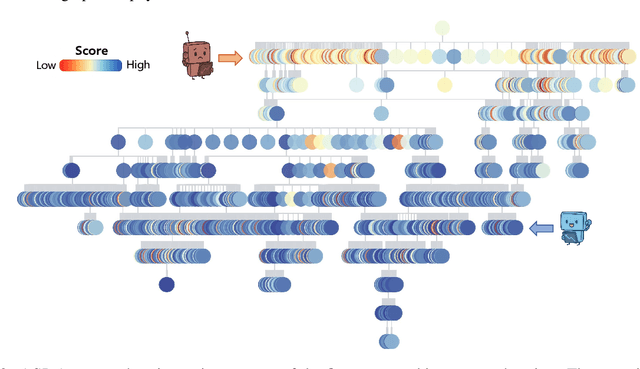
While AI systems demonstrate exponentially improving capabilities, the pace of AI research itself remains linearly bounded by human cognitive capacity, creating an increasingly severe development bottleneck. We present ASI-Arch, the first demonstration of Artificial Superintelligence for AI research (ASI4AI) in the critical domain of neural architecture discovery--a fully autonomous system that shatters this fundamental constraint by enabling AI to conduct its own architectural innovation. Moving beyond traditional Neural Architecture Search (NAS), which is fundamentally limited to exploring human-defined spaces, we introduce a paradigm shift from automated optimization to automated innovation. ASI-Arch can conduct end-to-end scientific research in the domain of architecture discovery, autonomously hypothesizing novel architectural concepts, implementing them as executable code, training and empirically validating their performance through rigorous experimentation and past experience. ASI-Arch conducted 1,773 autonomous experiments over 20,000 GPU hours, culminating in the discovery of 106 innovative, state-of-the-art (SOTA) linear attention architectures. Like AlphaGo's Move 37 that revealed unexpected strategic insights invisible to human players, our AI-discovered architectures demonstrate emergent design principles that systematically surpass human-designed baselines and illuminate previously unknown pathways for architectural innovation. Crucially, we establish the first empirical scaling law for scientific discovery itself--demonstrating that architectural breakthroughs can be scaled computationally, transforming research progress from a human-limited to a computation-scalable process. We provide comprehensive analysis of the emergent design patterns and autonomous research capabilities that enabled these breakthroughs, establishing a blueprint for self-accelerating AI systems.
Generative AI Act II: Test Time Scaling Drives Cognition Engineering
Apr 21, 2025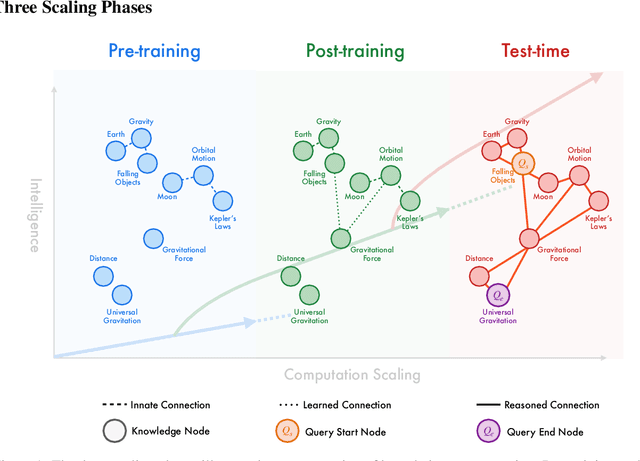
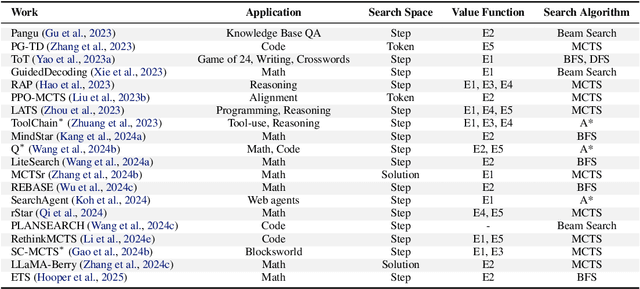
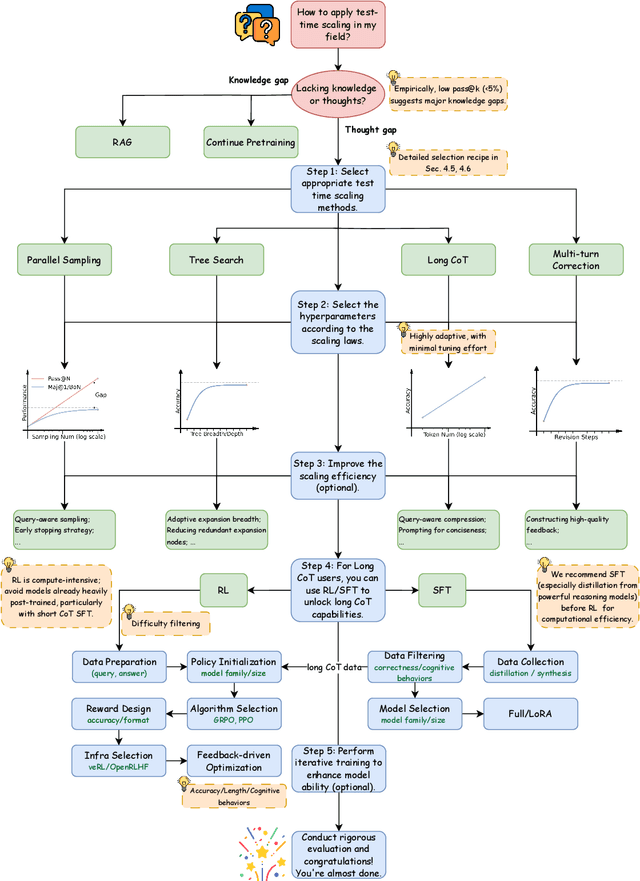
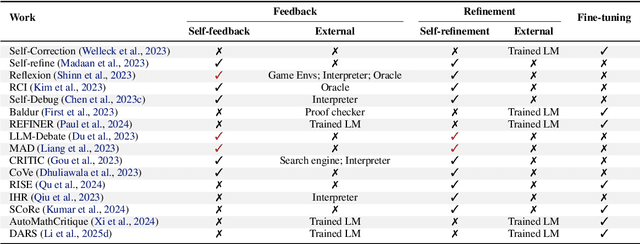
The first generation of Large Language Models - what might be called "Act I" of generative AI (2020-2023) - achieved remarkable success through massive parameter and data scaling, yet exhibited fundamental limitations such as knowledge latency, shallow reasoning, and constrained cognitive processes. During this era, prompt engineering emerged as our primary interface with AI, enabling dialogue-level communication through natural language. We now witness the emergence of "Act II" (2024-present), where models are transitioning from knowledge-retrieval systems (in latent space) to thought-construction engines through test-time scaling techniques. This new paradigm establishes a mind-level connection with AI through language-based thoughts. In this paper, we clarify the conceptual foundations of cognition engineering and explain why this moment is critical for its development. We systematically break down these advanced approaches through comprehensive tutorials and optimized implementations, democratizing access to cognition engineering and enabling every practitioner to participate in AI's second act. We provide a regularly updated collection of papers on test-time scaling in the GitHub Repository: https://github.com/GAIR-NLP/cognition-engineering
Reproducibility Companion Paper:In-processing User Constrained Dominant Sets for User-Oriented Fairness in Recommender Systems
Mar 29, 2025In this paper, we reproduce experimental results presented in our earlier work titled "In-processing User Constrained Dominant Sets for User-Oriented Fairness in Recommender Systems" that was presented in the proceeding of the 31st ACM International Conference on Multimedia.This work aims to verify the effectiveness of our previously proposed method and provide guidance for reproducibility. We present detailed descriptions of our preprocessed datasets, the structure of our source code, configuration file settings, experimental environment, and the reproduced experimental results.
DIVE: Diversified Iterative Self-Improvement
Jan 01, 2025Recent advances in large language models (LLMs) have demonstrated the effectiveness of Iterative Self-Improvement (ISI) techniques. However, continuous training on self-generated data leads to reduced output diversity, a limitation particularly critical in reasoning tasks where diverse solution paths are essential. We present DIVE (Diversified Iterative Self-Improvement), a novel framework that addresses this challenge through two key components: Sample Pool Expansion for broader solution exploration, and Data Selection for balancing diversity and quality in preference pairs. Experiments on MATH and GSM8k datasets show that DIVE achieves a 10% to 45% relative increase in output diversity metrics while maintaining performance quality compared to vanilla ISI. Our ablation studies confirm both components' significance in achieving these improvements. Code is available at https://github.com/qinyiwei/DIVE.
O1 Replication Journey -- Part 2: Surpassing O1-preview through Simple Distillation, Big Progress or Bitter Lesson?
Nov 25, 2024This paper presents a critical examination of current approaches to replicating OpenAI's O1 model capabilities, with particular focus on the widespread but often undisclosed use of knowledge distillation techniques. While our previous work explored the fundamental technical path to O1 replication, this study reveals how simple distillation from O1's API, combined with supervised fine-tuning, can achieve superior performance on complex mathematical reasoning tasks. Through extensive experiments, we show that a base model fine-tuned on simply tens of thousands of samples O1-distilled long-thought chains outperforms O1-preview on the American Invitational Mathematics Examination (AIME) with minimal technical complexity. Moreover, our investigation extends beyond mathematical reasoning to explore the generalization capabilities of O1-distilled models across diverse tasks: hallucination, safety and open-domain QA. Notably, despite training only on mathematical problem-solving data, our models demonstrated strong generalization to open-ended QA tasks and became significantly less susceptible to sycophancy after fine-tuning. We deliberately make this finding public to promote transparency in AI research and to challenge the current trend of obscured technical claims in the field. Our work includes: (1) A detailed technical exposition of the distillation process and its effectiveness, (2) A comprehensive benchmark framework for evaluating and categorizing O1 replication attempts based on their technical transparency and reproducibility, (3) A critical discussion of the limitations and potential risks of over-relying on distillation approaches, our analysis culminates in a crucial bitter lesson: while the pursuit of more capable AI systems is important, the development of researchers grounded in first-principles thinking is paramount.
SAFETY-J: Evaluating Safety with Critique
Jul 25, 2024The deployment of Large Language Models (LLMs) in content generation raises significant safety concerns, particularly regarding the transparency and interpretability of content evaluations. Current methods, primarily focused on binary safety classifications, lack mechanisms for detailed critique, limiting their utility for model improvement and user trust. To address these limitations, we introduce SAFETY-J, a bilingual generative safety evaluator for English and Chinese with critique-based judgment. SAFETY-J utilizes a robust training dataset that includes diverse dialogues and augmented query-response pairs to assess safety across various scenarios comprehensively. We establish an automated meta-evaluation benchmark that objectively assesses the quality of critiques with minimal human intervention, facilitating scalable and continuous improvement. Additionally, SAFETY-J employs an iterative preference learning technique to dynamically refine safety assessments based on meta-evaluations and critiques. Our evaluations demonstrate that SAFETY-J provides more nuanced and accurate safety evaluations, thereby enhancing both critique quality and predictive reliability in complex content scenarios. To facilitate further research and application, we open-source SAFETY-J's training protocols, datasets, and code at \url{https://github.com/GAIR-NLP/Safety-J}.
OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent AI
Jun 18, 2024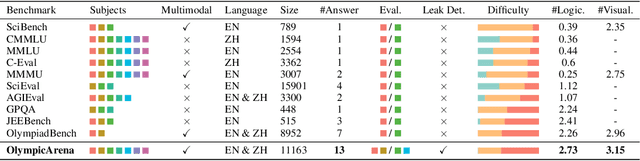
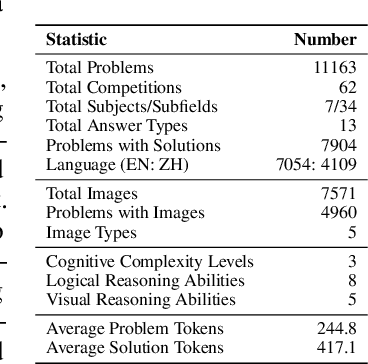
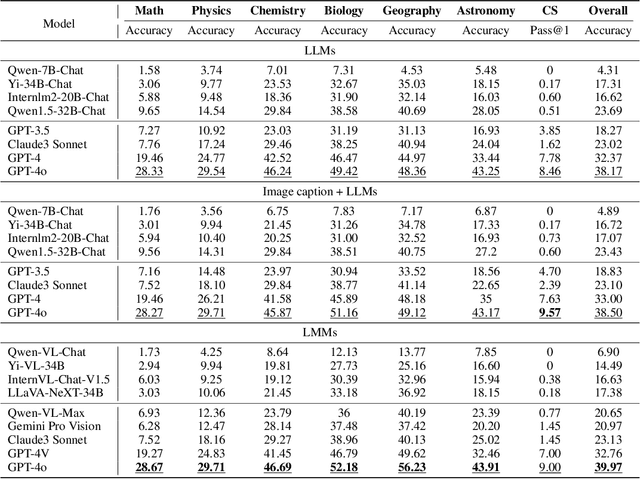
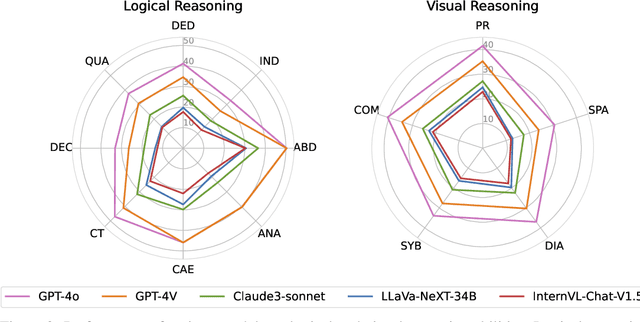
The evolution of Artificial Intelligence (AI) has been significantly accelerated by advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), gradually showcasing potential cognitive reasoning abilities in problem-solving and scientific discovery (i.e., AI4Science) once exclusive to human intellect. To comprehensively evaluate current models' performance in cognitive reasoning abilities, we introduce OlympicArena, which includes 11,163 bilingual problems across both text-only and interleaved text-image modalities. These challenges encompass a wide range of disciplines spanning seven fields and 62 international Olympic competitions, rigorously examined for data leakage. We argue that the challenges in Olympic competition problems are ideal for evaluating AI's cognitive reasoning due to their complexity and interdisciplinary nature, which are essential for tackling complex scientific challenges and facilitating discoveries. Beyond evaluating performance across various disciplines using answer-only criteria, we conduct detailed experiments and analyses from multiple perspectives. We delve into the models' cognitive reasoning abilities, their performance across different modalities, and their outcomes in process-level evaluations, which are vital for tasks requiring complex reasoning with lengthy solutions. Our extensive evaluations reveal that even advanced models like GPT-4o only achieve a 39.97% overall accuracy, illustrating current AI limitations in complex reasoning and multimodal integration. Through the OlympicArena, we aim to advance AI towards superintelligence, equipping it to address more complex challenges in science and beyond. We also provide a comprehensive set of resources to support AI research, including a benchmark dataset, an open-source annotation platform, a detailed evaluation tool, and a leaderboard with automatic submission features.
MSE-Nets: Multi-annotated Semi-supervised Ensemble Networks for Improving Segmentation of Medical Image with Ambiguous Boundaries
Nov 17, 2023



Medical image segmentation annotations exhibit variations among experts due to the ambiguous boundaries of segmented objects and backgrounds in medical images. Although using multiple annotations for each image in the fully-supervised has been extensively studied for training deep models, obtaining a large amount of multi-annotated data is challenging due to the substantial time and manpower costs required for segmentation annotations, resulting in most images lacking any annotations. To address this, we propose Multi-annotated Semi-supervised Ensemble Networks (MSE-Nets) for learning segmentation from limited multi-annotated and abundant unannotated data. Specifically, we introduce the Network Pairwise Consistency Enhancement (NPCE) module and Multi-Network Pseudo Supervised (MNPS) module to enhance MSE-Nets for the segmentation task by considering two major factors: (1) to optimize the utilization of all accessible multi-annotated data, the NPCE separates (dis)agreement annotations of multi-annotated data at the pixel level and handles agreement and disagreement annotations in different ways, (2) to mitigate the introduction of imprecise pseudo-labels, the MNPS extends the training data by leveraging consistent pseudo-labels from unannotated data. Finally, we improve confidence calibration by averaging the predictions of base networks. Experiments on the ISIC dataset show that we reduced the demand for multi-annotated data by 97.75\% and narrowed the gap with the best fully-supervised baseline to just a Jaccard index of 4\%. Furthermore, compared to other semi-supervised methods that rely only on a single annotation or a combined fusion approach, the comprehensive experimental results on ISIC and RIGA datasets demonstrate the superior performance of our proposed method in medical image segmentation with ambiguous boundaries.