 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaEval: Evaluating Agents in Production
Apr 14, 2026The rapid deployment of AI agents in commercial settings has outpaced the development of evaluation methodologies that reflect production realities. Existing benchmarks measure agent capabilities through retrospectively curated tasks with well-specified requirements and deterministic metrics -- conditions that diverge fundamentally from production environments where requirements contain implicit constraints, inputs are heterogeneous multi-modal documents with information fragmented across sources, tasks demand undeclared domain expertise, outputs are long-horizon professional deliverables, and success is judged by domain experts whose standards evolve over time. We present AlphaEval, a production-grounded benchmark of 94 tasks sourced from seven companies deploying AI agents in their core business, spanning six O*NET (Occupational Information Network) domains. Unlike model-centric benchmarks, AlphaEval evaluates complete agent products -- Claude Code, Codex, etc. -- as commercial systems, capturing performance variations invisible to model-level evaluation. Our evaluation framework covers multiple paradigms (LLM-as-a-Judge, reference-driven metrics, formal verification, rubric-based assessment, automated UI testing, etc.), with individual domains composing multiple paradigms. Beyond the benchmark itself, we contribute a requirement-to-benchmark construction framework -- a systematic methodology that transforms authentic production requirements into executable evaluation tasks in minimal time. This framework standardizes the entire pipeline from requirement to evaluation, providing a reproducible, modular process that any organization can adopt to construct production-grounded benchmarks for their own domains.
Rubrics to Tokens: Bridging Response-level Rubrics and Token-level Rewards in Instruction Following Tasks
Apr 03, 2026Rubric-based Reinforcement Learning (RL) has emerged as a promising approach for aligning Large Language Models (LLMs) with complex, open-domain instruction following tasks. However, existing methods predominantly rely on response-level rewards, introducing severe reward sparsity and reward ambiguity problems. To address these issues, we propose Rubrics to Tokens (RTT), a novel rubric-based RL framework that bridges coarse response-level scores and fine-grained token-level credit assignment. RTT introduces a Token-Level Relevance Discriminator to predict which tokens in the response are responsible for a specific constraint, and optimizes the policy model via RTT-GRPO, which integrates response-level and token-level advantages within a unified framework. Furthermore, when transitioning from one-dimensional, outcome-level reward to three-dimensional reward space in the token-level rubric-based RL, we propose a novel group normalization method, called Intra-sample Token Group Normalization, to accommodate this shift. Extensive experiments and benchmarks demonstrate that RTT consistently outperforms other baselines in both instruction- and rubric-level accuracy across different models.
ASI-Evolve: AI Accelerates AI
Mar 31, 2026Can AI accelerate the development of AI itself? While recent agentic systems have shown strong performance on well-scoped tasks with rapid feedback, it remains unclear whether they can tackle the costly, long-horizon, and weakly supervised research loops that drive real AI progress. We present ASI-Evolve, an agentic framework for AI-for-AI research that closes this loop through a learn-design-experiment-analyze cycle. ASI-Evolve augments standard evolutionary agents with two key components: a cognition base that injects accumulated human priors into each round of exploration, and a dedicated analyzer that distills complex experimental outcomes into reusable insights for future iterations. To our knowledge, ASI-Evolve is the first unified framework to demonstrate AI-driven discovery across three central components of AI development: data, architectures, and learning algorithms. In neural architecture design, it discovered 105 SOTA linear attention architectures, with the best discovered model surpassing DeltaNet by +0.97 points, nearly 3x the gain of recent human-designed improvements. In pretraining data curation, the evolved pipeline improves average benchmark performance by +3.96 points, with gains exceeding 18 points on MMLU. In reinforcement learning algorithm design, discovered algorithms outperform GRPO by up to +12.5 points on AMC32, +11.67 points on AIME24, and +5.04 points on OlympiadBench. We further provide initial evidence that this AI-for-AI paradigm can transfer beyond the AI stack through experiments in mathematics and biomedicine. Together, these results suggest that ASI-Evolve represents a promising step toward enabling AI to accelerate AI across the foundational stages of development, offering early evidence for the feasibility of closed-loop AI research.
Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
Mar 23, 2026We present daVinci-MagiHuman, an open-source audio-video generative foundation model for human-centric generation. daVinci-MagiHuman jointly generates synchronized video and audio using a single-stream Transformer that processes text, video, and audio within a unified token sequence via self-attention only. This single-stream design avoids the complexity of multi-stream or cross-attention architectures while remaining easy to optimize with standard training and inference infrastructure. The model is particularly strong in human-centric scenarios, producing expressive facial performance, natural speech-expression coordination, realistic body motion, and precise audio-video synchronization. It supports multilingual spoken generation across Chinese (Mandarin and Cantonese), English, Japanese, Korean, German, and French. For efficient inference, we combine the single-stream backbone with model distillation, latent-space super-resolution, and a Turbo VAE decoder, enabling generation of a 5-second 256p video in 2 seconds on a single H100 GPU. In automatic evaluation, daVinci-MagiHuman achieves the highest visual quality and text alignment among leading open models, along with the lowest word error rate (14.60%) for speech intelligibility. In pairwise human evaluation, it achieves win rates of 80.0% against Ovi 1.1 and 60.9% against LTX 2.3 over 2000 comparisons. We open-source the complete model stack, including the base model, the distilled model, the super-resolution model, and the inference codebase.
ProjDevBench: Benchmarking AI Coding Agents on End-to-End Project Development
Feb 02, 2026Recent coding agents can generate complete codebases from simple prompts, yet existing evaluations focus on issue-level bug fixing and lag behind end-to-end development. We introduce ProjDevBench, an end-to-end benchmark that provides project requirements to coding agents and evaluates the resulting repositories. Combining Online Judge (OJ) testing with LLM-assisted code review, the benchmark evaluates agents on (1) system architecture design, (2) functional correctness, and (3) iterative solution refinement. We curate 20 programming problems across 8 categories, covering both concept-oriented tasks and real-world application scenarios, and evaluate six coding agents built on different LLM backends. Our evaluation reports an overall acceptance rate of 27.38%: agents handle basic functionality and data structures but struggle with complex system design, time complexity optimization, and resource management. Our benchmark is available at https://github.com/zsworld6/projdevbench.
daVinci-Dev: Agent-native Mid-training for Software Engineering
Jan 27, 2026Recently, the frontier of Large Language Model (LLM) capabilities has shifted from single-turn code generation to agentic software engineering-a paradigm where models autonomously navigate, edit, and test complex repositories. While post-training methods have become the de facto approach for code agents, **agentic mid-training**-mid-training (MT) on large-scale data that mirrors authentic agentic workflows-remains critically underexplored due to substantial resource requirements, despite offering a more scalable path to instilling foundational agentic behaviors than relying solely on expensive reinforcement learning. A central challenge in realizing effective agentic mid-training is the distribution mismatch between static training data and the dynamic, feedback-rich environment of real development. To address this, we present a systematic study of agentic mid-training, establishing both the data synthesis principles and training methodology for effective agent development at scale. Central to our approach is **agent-native data**-supervision comprising two complementary types of trajectories: **contextually-native trajectories** that preserve the complete information flow an agent experiences, offering broad coverage and diversity; and **environmentally-native trajectories** collected from executable repositories where observations stem from actual tool invocations and test executions, providing depth and interaction authenticity. We verify the model's agentic capabilities on `SWE-Bench Verified`. We demonstrate our superiority over the previous open software engineering mid-training recipe `Kimi-Dev` under two post-training settings with an aligned base model and agentic scaffold, while using less than half mid-training tokens (73.1B). Besides relative advantage, our best performing 32B and 72B models achieve **56.1%** and **58.5%** resolution rates, respectively, which are ...
DeepPersona: A Generative Engine for Scaling Deep Synthetic Personas
Nov 11, 2025Simulating human profiles by instilling personas into large language models (LLMs) is rapidly transforming research in agentic behavioral simulation, LLM personalization, and human-AI alignment. However, most existing synthetic personas remain shallow and simplistic, capturing minimal attributes and failing to reflect the rich complexity and diversity of real human identities. We introduce DEEPPERSONA, a scalable generative engine for synthesizing narrative-complete synthetic personas through a two-stage, taxonomy-guided method. First, we algorithmically construct the largest-ever human-attribute taxonomy, comprising over hundreds of hierarchically organized attributes, by mining thousands of real user-ChatGPT conversations. Second, we progressively sample attributes from this taxonomy, conditionally generating coherent and realistic personas that average hundreds of structured attributes and roughly 1 MB of narrative text, two orders of magnitude deeper than prior works. Intrinsic evaluations confirm significant improvements in attribute diversity (32 percent higher coverage) and profile uniqueness (44 percent greater) compared to state-of-the-art baselines. Extrinsically, our personas enhance GPT-4.1-mini's personalized question answering accuracy by 11.6 percent on average across ten metrics and substantially narrow (by 31.7 percent) the gap between simulated LLM citizens and authentic human responses in social surveys. Our generated national citizens reduced the performance gap on the Big Five personality test by 17 percent relative to LLM-simulated citizens. DEEPPERSONA thus provides a rigorous, scalable, and privacy-free platform for high-fidelity human simulation and personalized AI research.
* 12 pages, 5 figures, accepted at LAW 2025 Workshop (NeurIPS 2025) Project page: https://deeppersona-ai.github.io/
InnovatorBench: Evaluating Agents' Ability to Conduct Innovative LLM Research
Nov 03, 2025



AI agents could accelerate scientific discovery by automating hypothesis formation, experiment design, coding, execution, and analysis, yet existing benchmarks probe narrow skills in simplified settings. To address this gap, we introduce InnovatorBench, a benchmark-platform pair for realistic, end-to-end assessment of agents performing Large Language Model (LLM) research. It comprises 20 tasks spanning Data Construction, Filtering, Augmentation, Loss Design, Reward Design, and Scaffold Construction, which require runnable artifacts and assessment of correctness, performance, output quality, and uncertainty. To support agent operation, we develop ResearchGym, a research environment offering rich action spaces, distributed and long-horizon execution, asynchronous monitoring, and snapshot saving. We also implement a lightweight ReAct agent that couples explicit reasoning with executable planning using frontier models such as Claude-4, GPT-5, GLM-4.5, and Kimi-K2. Our experiments demonstrate that while frontier models show promise in code-driven research tasks, they struggle with fragile algorithm-related tasks and long-horizon decision making, such as impatience, poor resource management, and overreliance on template-based reasoning. Furthermore, agents require over 11 hours to achieve their best performance on InnovatorBench, underscoring the benchmark's difficulty and showing the potential of InnovatorBench to be the next generation of code-based research benchmark.
Interaction as Intelligence Part II: Asynchronous Human-Agent Rollout for Long-Horizon Task Training
Nov 03, 2025Large Language Model (LLM) agents have recently shown strong potential in domains such as automated coding, deep research, and graphical user interface manipulation. However, training them to succeed on long-horizon, domain-specialized tasks remains challenging. Current methods primarily fall into two categories. The first relies on dense human annotations through behavior cloning, which is prohibitively expensive for long-horizon tasks that can take days or months. The second depends on outcome-driven sampling, which often collapses due to the rarity of valid positive trajectories on domain-specialized tasks. We introduce Apollo, a sampling framework that integrates asynchronous human guidance with action-level data filtering. Instead of requiring annotators to shadow every step, Apollo allows them to intervene only when the agent drifts from a promising trajectory, by providing prior knowledge, strategic advice, etc. This lightweight design makes it possible to sustain interactions for over 30 hours and produces valuable trajectories at a lower cost. Apollo then applies supervision control to filter out sub-optimal actions and prevent error propagation. Together, these components enable reliable and effective data collection in long-horizon environments. To demonstrate the effectiveness of Apollo, we evaluate it using InnovatorBench. Our experiments show that when applied to train the GLM-4.5 model on InnovatorBench, Apollo achieves more than a 50% improvement over the untrained baseline and a 28% improvement over a variant trained without human interaction. These results highlight the critical role of human-in-the-loop sampling and the robustness of Apollo's design in handling long-horizon, domain-specialized tasks.
Context Engineering 2.0: The Context of Context Engineering
Oct 30, 2025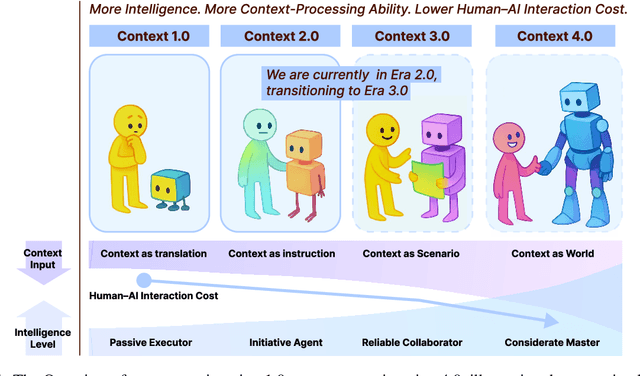
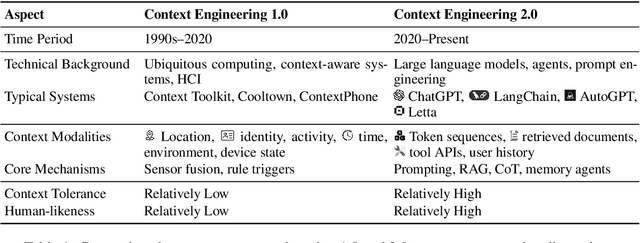
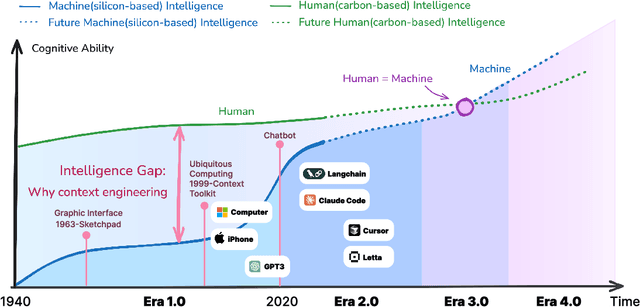
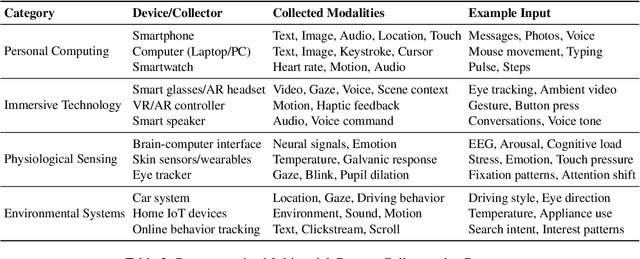
Karl Marx once wrote that ``the human essence is the ensemble of social relations'', suggesting that individuals are not isolated entities but are fundamentally shaped by their interactions with other entities, within which contexts play a constitutive and essential role. With the advent of computers and artificial intelligence, these contexts are no longer limited to purely human--human interactions: human--machine interactions are included as well. Then a central question emerges: How can machines better understand our situations and purposes? To address this challenge, researchers have recently introduced the concept of context engineering. Although it is often regarded as a recent innovation of the agent era, we argue that related practices can be traced back more than twenty years. Since the early 1990s, the field has evolved through distinct historical phases, each shaped by the intelligence level of machines: from early human--computer interaction frameworks built around primitive computers, to today's human--agent interaction paradigms driven by intelligent agents, and potentially to human--level or superhuman intelligence in the future. In this paper, we situate context engineering, provide a systematic definition, outline its historical and conceptual landscape, and examine key design considerations for practice. By addressing these questions, we aim to offer a conceptual foundation for context engineering and sketch its promising future. This paper is a stepping stone for a broader community effort toward systematic context engineering in AI systems.