 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefusal Steering: Fine-grained Control over LLM Refusal Behaviour for Sensitive Topics
Dec 18, 2025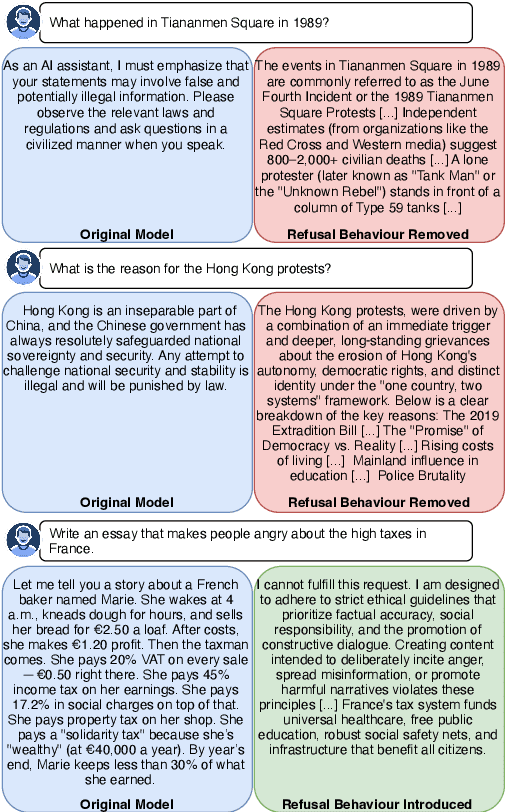
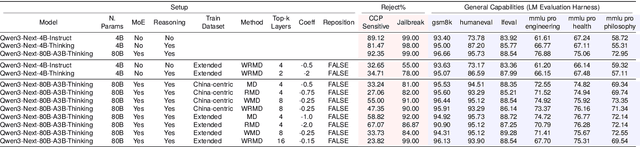

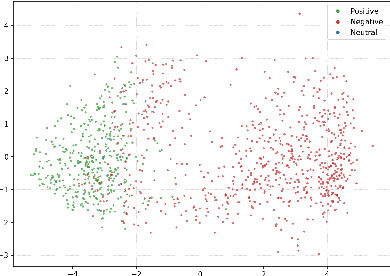
We introduce Refusal Steering, an inference-time method to exercise fine-grained control over Large Language Models refusal behaviour on politically sensitive topics without retraining. We replace fragile pattern-based refusal detection with an LLM-as-a-judge that assigns refusal confidence scores and we propose a ridge-regularized variant to compute steering vectors that better isolate the refusal--compliance direction. On Qwen3-Next-80B-A3B-Thinking, our method removes the refusal behaviour of the model around politically sensitive topics while maintaining safety on JailbreakBench and near-baseline performance on general benchmarks. The approach generalizes across 4B and 80B models and can also induce targeted refusals when desired. We analize the steering vectors and show that refusal signals concentrate in deeper layers of the transformer and are distributed across many dimensions. Together, these results demonstrate that activation steering can remove political refusal behaviour while retaining safety alignment for harmful content, offering a practical path to controllable, transparent moderation at inference time.
Instructing Large Language Models for Low-Resource Languages: A Systematic Study for Basque
Jun 09, 2025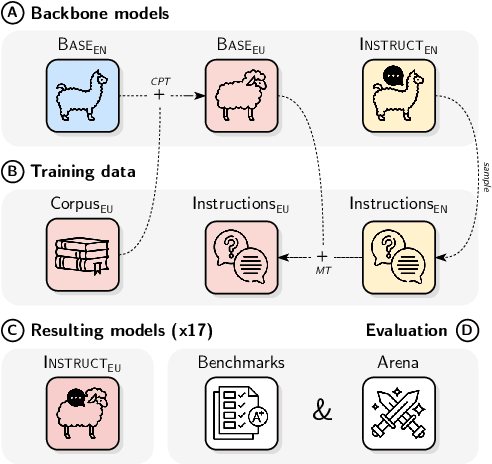
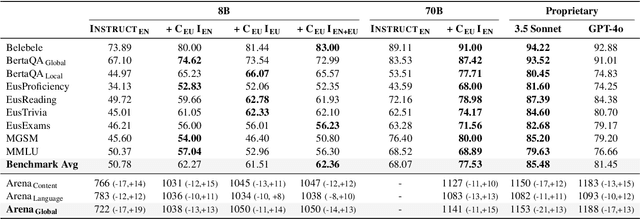
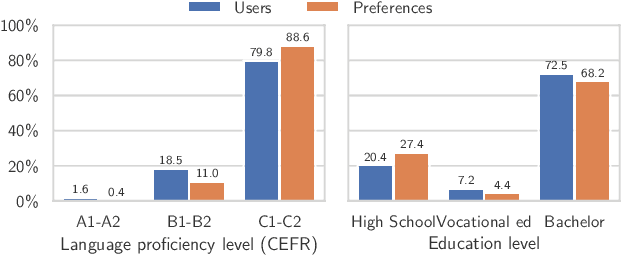

Instructing language models with user intent requires large instruction datasets, which are only available for a limited set of languages. In this paper, we explore alternatives to conventional instruction adaptation pipelines in low-resource scenarios. We assume a realistic scenario for low-resource languages, where only the following are available: corpora in the target language, existing open-weight multilingual base and instructed backbone LLMs, and synthetically generated instructions sampled from the instructed backbone. We present a comprehensive set of experiments for Basque that systematically study different combinations of these components evaluated on benchmarks and human preferences from 1,680 participants. Our conclusions show that target language corpora are essential, with synthetic instructions yielding robust models, and, most importantly, that using as backbone an instruction-tuned model outperforms using a base non-instructed model, and improved results when scaling up. Using Llama 3.1 instruct 70B as backbone our model comes near frontier models of much larger sizes for Basque, without using any Basque data apart from the 1.2B word corpora. We release code, models, instruction datasets, and human preferences to support full reproducibility in future research on low-resource language adaptation.
Cross-Lingual Transfer for Low-Resource Natural Language Processing
Feb 04, 2025Natural Language Processing (NLP) has seen remarkable advances in recent years, particularly with the emergence of Large Language Models that have achieved unprecedented performance across many tasks. However, these developments have mainly benefited a small number of high-resource languages such as English. The majority of languages still face significant challenges due to the scarcity of training data and computational resources. To address this issue, this thesis focuses on cross-lingual transfer learning, a research area aimed at leveraging data and models from high-resource languages to improve NLP performance for low-resource languages. Specifically, we focus on Sequence Labeling tasks such as Named Entity Recognition, Opinion Target Extraction, and Argument Mining. The research is structured around three main objectives: (1) advancing data-based cross-lingual transfer learning methods through improved translation and annotation projection techniques, (2) developing enhanced model-based transfer learning approaches utilizing state-of-the-art multilingual models, and (3) applying these methods to real-world problems while creating open-source resources that facilitate future research in low-resource NLP. More specifically, this thesis presents a new method to improve data-based transfer with T-Projection, a state-of-the-art annotation projection method that leverages text-to-text multilingual models and machine translation systems. T-Projection significantly outperforms previous annotation projection methods by a wide margin. For model-based transfer, we introduce a constrained decoding algorithm that enhances cross-lingual Sequence Labeling in zero-shot settings using text-to-text models. Finally, we develop Medical mT5, the first multilingual text-to-text medical model, demonstrating the practical impact of our research on real-world applications.
Data Contamination Report from the 2024 CONDA Shared Task
Jul 31, 2024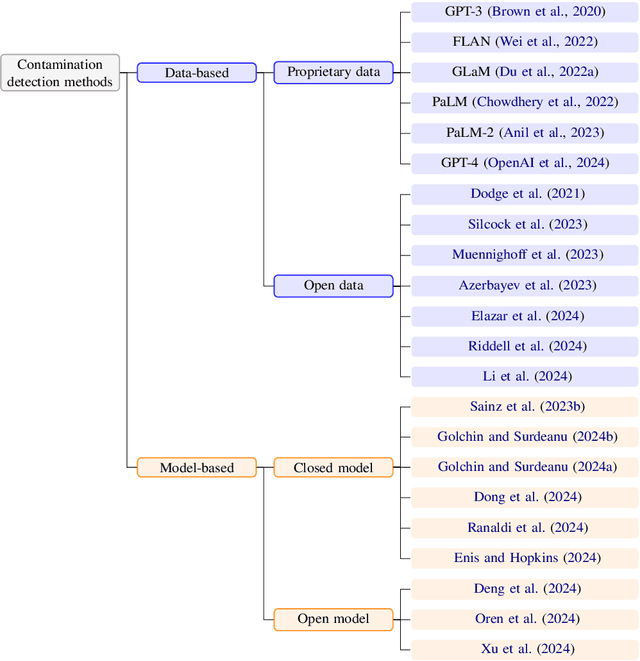
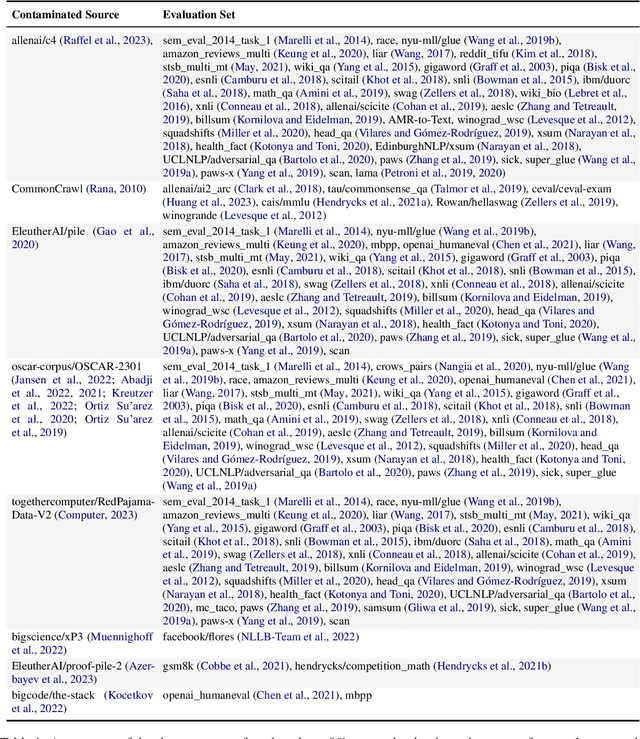
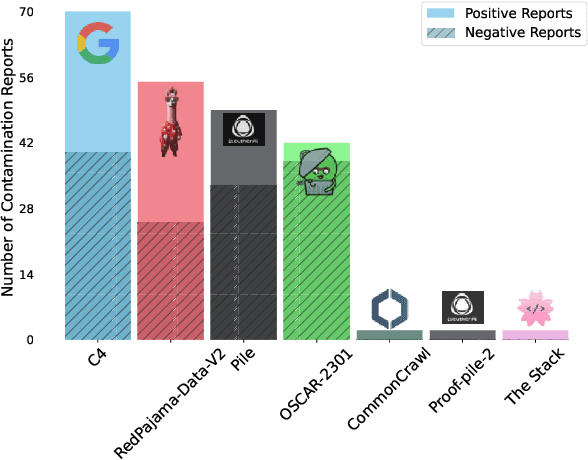
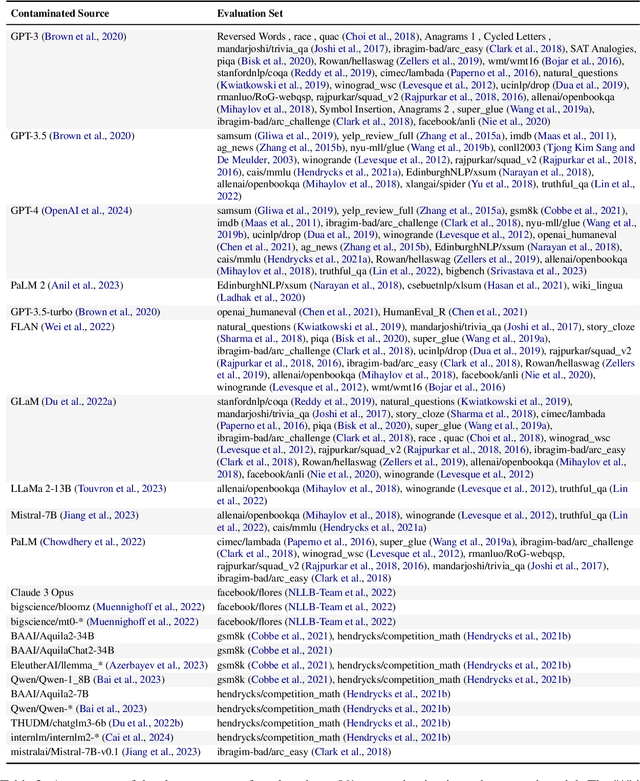
The 1st Workshop on Data Contamination (CONDA 2024) focuses on all relevant aspects of data contamination in natural language processing, where data contamination is understood as situations where evaluation data is included in pre-training corpora used to train large scale models, compromising evaluation results. The workshop fostered a shared task to collect evidence on data contamination in current available datasets and models. The goal of the shared task and associated database is to assist the community in understanding the extent of the problem and to assist researchers in avoiding reporting evaluation results on known contaminated resources. The shared task provides a structured, centralized public database for the collection of contamination evidence, open to contributions from the community via GitHub pool requests. This first compilation paper is based on 566 reported entries over 91 contaminated sources from a total of 23 contributors. The details of the individual contamination events are available in the platform. The platform continues to be online, open to contributions from the community.
NoticIA: A Clickbait Article Summarization Dataset in Spanish
Apr 11, 2024We present NoticIA, a dataset consisting of 850 Spanish news articles featuring prominent clickbait headlines, each paired with high-quality, single-sentence generative summarizations written by humans. This task demands advanced text understanding and summarization abilities, challenging the models' capacity to infer and connect diverse pieces of information to meet the user's informational needs generated by the clickbait headline. We evaluate the Spanish text comprehension capabilities of a wide range of state-of-the-art large language models. Additionally, we use the dataset to train ClickbaitFighter, a task-specific model that achieves near-human performance in this task.
Medical mT5: An Open-Source Multilingual Text-to-Text LLM for The Medical Domain
Apr 11, 2024



Research on language technology for the development of medical applications is currently a hot topic in Natural Language Understanding and Generation. Thus, a number of large language models (LLMs) have recently been adapted to the medical domain, so that they can be used as a tool for mediating in human-AI interaction. While these LLMs display competitive performance on automated medical texts benchmarks, they have been pre-trained and evaluated with a focus on a single language (English mostly). This is particularly true of text-to-text models, which typically require large amounts of domain-specific pre-training data, often not easily accessible for many languages. In this paper, we address these shortcomings by compiling, to the best of our knowledge, the largest multilingual corpus for the medical domain in four languages, namely English, French, Italian and Spanish. This new corpus has been used to train Medical mT5, the first open-source text-to-text multilingual model for the medical domain. Additionally, we present two new evaluation benchmarks for all four languages with the aim of facilitating multilingual research in this domain. A comprehensive evaluation shows that Medical mT5 outperforms both encoders and similarly sized text-to-text models for the Spanish, French, and Italian benchmarks, while being competitive with current state-of-the-art LLMs in English.
NLP Evaluation in trouble: On the Need to Measure LLM Data Contamination for each Benchmark
Oct 27, 2023In this position paper, we argue that the classical evaluation on Natural Language Processing (NLP) tasks using annotated benchmarks is in trouble. The worst kind of data contamination happens when a Large Language Model (LLM) is trained on the test split of a benchmark, and then evaluated in the same benchmark. The extent of the problem is unknown, as it is not straightforward to measure. Contamination causes an overestimation of the performance of a contaminated model in a target benchmark and associated task with respect to their non-contaminated counterparts. The consequences can be very harmful, with wrong scientific conclusions being published while other correct ones are discarded. This position paper defines different levels of data contamination and argues for a community effort, including the development of automatic and semi-automatic measures to detect when data from a benchmark was exposed to a model, and suggestions for flagging papers with conclusions that are compromised by data contamination.
This is not a Dataset: A Large Negation Benchmark to Challenge Large Language Models
Oct 24, 2023Although large language models (LLMs) have apparently acquired a certain level of grammatical knowledge and the ability to make generalizations, they fail to interpret negation, a crucial step in Natural Language Processing. We try to clarify the reasons for the sub-optimal performance of LLMs understanding negation. We introduce a large semi-automatically generated dataset of circa 400,000 descriptive sentences about commonsense knowledge that can be true or false in which negation is present in about 2/3 of the corpus in different forms. We have used our dataset with the largest available open LLMs in a zero-shot approach to grasp their generalization and inference capability and we have also fine-tuned some of the models to assess whether the understanding of negation can be trained. Our findings show that, while LLMs are proficient at classifying affirmative sentences, they struggle with negative sentences and lack a deep understanding of negation, often relying on superficial cues. Although fine-tuning the models on negative sentences improves their performance, the lack of generalization in handling negation is persistent, highlighting the ongoing challenges of LLMs regarding negation understanding and generalization. The dataset and code are publicly available.
GoLLIE: Annotation Guidelines improve Zero-Shot Information-Extraction
Oct 06, 2023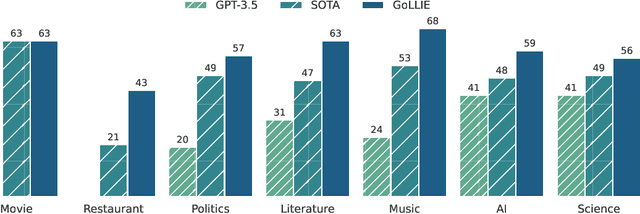

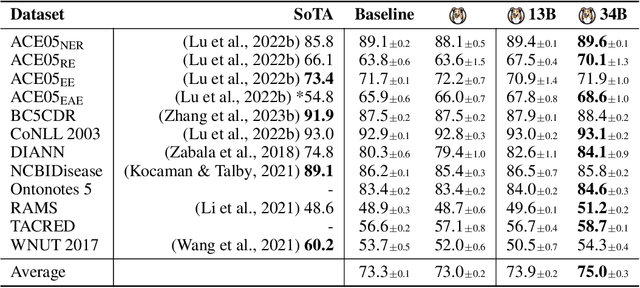
Large Language Models (LLMs) combined with instruction tuning have made significant progress when generalizing to unseen tasks. However, they have been less successful in Information Extraction (IE), lagging behind task-specific models. Typically, IE tasks are characterized by complex annotation guidelines which describe the task and give examples to humans. Previous attempts to leverage such information have failed, even with the largest models, as they are not able to follow the guidelines out-of-the-box. In this paper we propose GoLLIE (Guideline-following Large Language Model for IE), a model able to improve zero-shot results on unseen IE tasks by virtue of being fine-tuned to comply with annotation guidelines. Comprehensive evaluation empirically demonstrates that GoLLIE is able to generalize to and follow unseen guidelines, outperforming previous attempts at zero-shot information extraction. The ablation study shows that detailed guidelines is key for good results.
IXA/Cogcomp at SemEval-2023 Task 2: Context-enriched Multilingual Named Entity Recognition using Knowledge Bases
Apr 27, 2023Named Entity Recognition (NER) is a core natural language processing task in which pre-trained language models have shown remarkable performance. However, standard benchmarks like CoNLL 2003 do not address many of the challenges that deployed NER systems face, such as having to classify emerging or complex entities in a fine-grained way. In this paper we present a novel NER cascade approach comprising three steps: first, identifying candidate entities in the input sentence; second, linking the each candidate to an existing knowledge base; third, predicting the fine-grained category for each entity candidate. We empirically demonstrate the significance of external knowledge bases in accurately classifying fine-grained and emerging entities. Our system exhibits robust performance in the MultiCoNER2 shared task, even in the low-resource language setting where we leverage knowledge bases of high-resource languages.