 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIEFormer: Spectral-Interpretable and -Enhanced Transformer for Generalized Category Discovery
Feb 13, 2026This paper presents a novel approach, Spectral-Interpretable and -Enhanced Transformer (SIEFormer), which leverages spectral analysis to reinterpret the attention mechanism within Vision Transformer (ViT) and enhance feature adaptability, with particular emphasis on challenging Generalized Category Discovery (GCD) tasks. The proposed SIEFormer is composed of two main branches, each corresponding to an implicit and explicit spectral perspective of the ViT, enabling joint optimization. The implicit branch realizes the use of different types of graph Laplacians to model the local structure correlations of tokens, along with a novel Band-adaptive Filter (BaF) layer that can flexibly perform both band-pass and band-reject filtering. The explicit branch, on the other hand, introduces a Maneuverable Filtering Layer (MFL) that learns global dependencies among tokens by applying the Fourier transform to the input ``value" features, modulating the transformed signal with a set of learnable parameters in the frequency domain, and then performing an inverse Fourier transform to obtain the enhanced features. Extensive experiments reveal state-of-the-art performance on multiple image recognition datasets, reaffirming the superiority of our approach through ablation studies and visualizations.
Few-shot Novel Category Discovery
May 13, 2025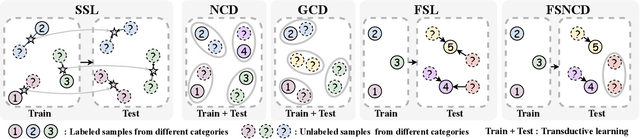
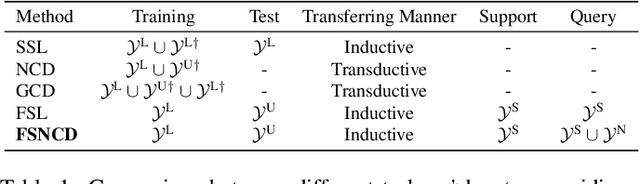
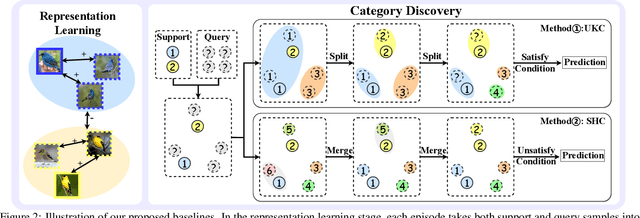
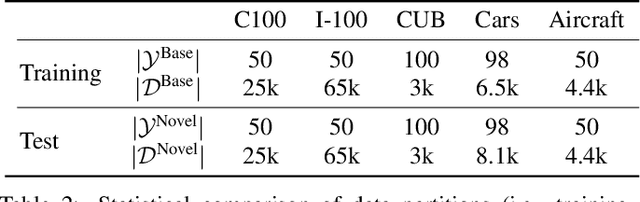
The recently proposed Novel Category Discovery (NCD) adapt paradigm of transductive learning hinders its application in more real-world scenarios. In fact, few labeled data in part of new categories can well alleviate this burden, which coincides with the ease that people can label few of new category data. Therefore, this paper presents a new setting in which a trained agent is able to flexibly switch between the tasks of identifying examples of known (labelled) classes and clustering novel (completely unlabeled) classes as the number of query examples increases by leveraging knowledge learned from only a few (handful) support examples. Drawing inspiration from the discovery of novel categories using prior-based clustering algorithms, we introduce a novel framework that further relaxes its assumptions to the real-world open set level by unifying the concept of model adaptability in few-shot learning. We refer to this setting as Few-Shot Novel Category Discovery (FSNCD) and propose Semi-supervised Hierarchical Clustering (SHC) and Uncertainty-aware K-means Clustering (UKC) to examine the model's reasoning capabilities. Extensive experiments and detailed analysis on five commonly used datasets demonstrate that our methods can achieve leading performance levels across different task settings and scenarios.
RobustEMD: Domain Robust Matching for Cross-domain Few-shot Medical Image Segmentation
Oct 01, 2024



Few-shot medical image segmentation (FSMIS) aims to perform the limited annotated data learning in the medical image analysis scope. Despite the progress has been achieved, current FSMIS models are all trained and deployed on the same data domain, as is not consistent with the clinical reality that medical imaging data is always across different data domains (e.g. imaging modalities, institutions and equipment sequences). How to enhance the FSMIS models to generalize well across the different specific medical imaging domains? In this paper, we focus on the matching mechanism of the few-shot semantic segmentation models and introduce an Earth Mover's Distance (EMD) calculation based domain robust matching mechanism for the cross-domain scenario. Specifically, we formulate the EMD transportation process between the foreground support-query features, the texture structure aware weights generation method, which proposes to perform the sobel based image gradient calculation over the nodes, is introduced in the EMD matching flow to restrain the domain relevant nodes. Besides, the point set level distance measurement metric is introduced to calculated the cost for the transportation from support set nodes to query set nodes. To evaluate the performance of our model, we conduct experiments on three scenarios (i.e., cross-modal, cross-sequence and cross-institution), which includes eight medical datasets and involves three body regions, and the results demonstrate that our model achieves the SoTA performance against the compared models.
Contextual Interaction via Primitive-based Adversarial Training For Compositional Zero-shot Learning
Jun 21, 2024
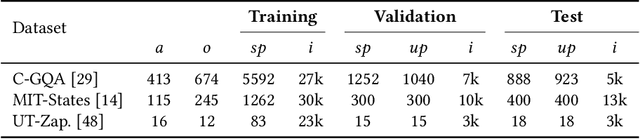

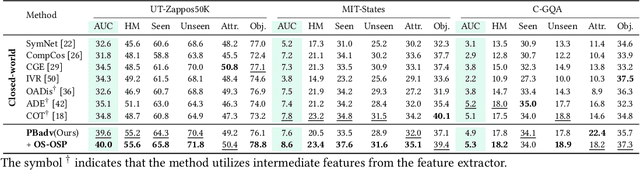
Compositional Zero-shot Learning (CZSL) aims to identify novel compositions via known attribute-object pairs. The primary challenge in CZSL tasks lies in the significant discrepancies introduced by the complex interaction between the visual primitives of attribute and object, consequently decreasing the classification performance towards novel compositions. Previous remarkable works primarily addressed this issue by focusing on disentangling strategy or utilizing object-based conditional probabilities to constrain the selection space of attributes. Unfortunately, few studies have explored the problem from the perspective of modeling the mechanism of visual primitive interactions. Inspired by the success of vanilla adversarial learning in Cross-Domain Few-Shot Learning, we take a step further and devise a model-agnostic and Primitive-Based Adversarial training (PBadv) method to deal with this problem. Besides, the latest studies highlight the weakness of the perception of hard compositions even under data-balanced conditions. To this end, we propose a novel over-sampling strategy with object-similarity guidance to augment target compositional training data. We performed detailed quantitative analysis and retrieval experiments on well-established datasets, such as UT-Zappos50K, MIT-States, and C-GQA, to validate the effectiveness of our proposed method, and the state-of-the-art (SOTA) performance demonstrates the superiority of our approach. The code is available at https://github.com/lisuyi/PBadv_czsl.
Wearable-based behaviour interpolation for semi-supervised human activity recognition
May 24, 2024



While traditional feature engineering for Human Activity Recognition (HAR) involves a trial-anderror process, deep learning has emerged as a preferred method for high-level representations of sensor-based human activities. However, most deep learning-based HAR requires a large amount of labelled data and extracting HAR features from unlabelled data for effective deep learning training remains challenging. We, therefore, introduce a deep semi-supervised HAR approach, MixHAR, which concurrently uses labelled and unlabelled activities. Our MixHAR employs a linear interpolation mechanism to blend labelled and unlabelled activities while addressing both inter- and intra-activity variability. A unique challenge identified is the activityintrusion problem during mixing, for which we propose a mixing calibration mechanism to mitigate it in the feature embedding space. Additionally, we rigorously explored and evaluated the five conventional/popular deep semi-supervised technologies on HAR, acting as the benchmark of deep semi-supervised HAR. Our results demonstrate that MixHAR significantly improves performance, underscoring the potential of deep semi-supervised techniques in HAR.
Partition-A-Medical-Image: Extracting Multiple Representative Sub-regions for Few-shot Medical Image Segmentation
Sep 20, 2023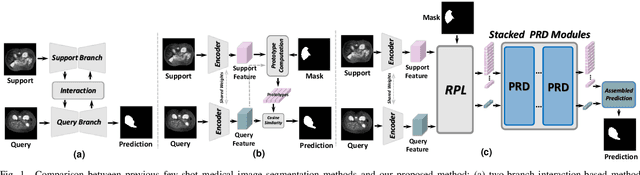
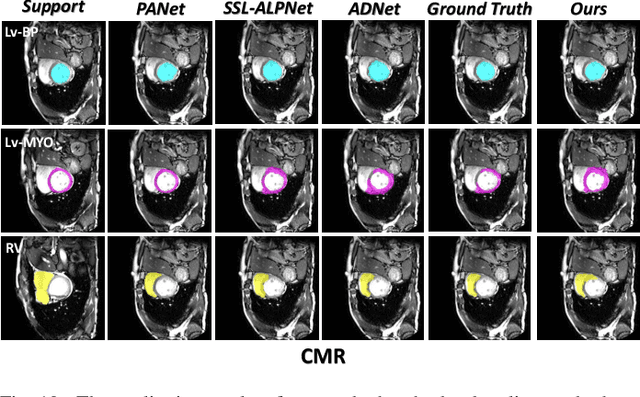
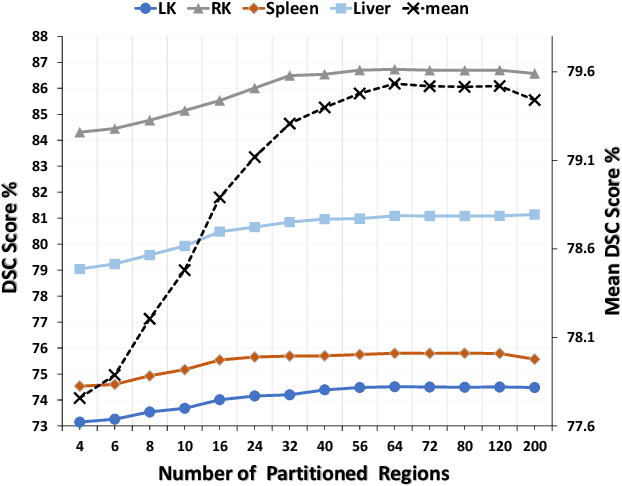
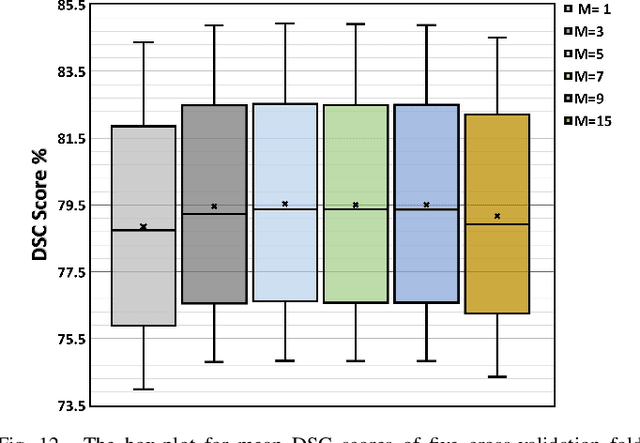
Few-shot Medical Image Segmentation (FSMIS) is a more promising solution for medical image segmentation tasks where high-quality annotations are naturally scarce. However, current mainstream methods primarily focus on extracting holistic representations from support images with large intra-class variations in appearance and background, and encounter difficulties in adapting to query images. In this work, we present an approach to extract multiple representative sub-regions from a given support medical image, enabling fine-grained selection over the generated image regions. Specifically, the foreground of the support image is decomposed into distinct regions, which are subsequently used to derive region-level representations via a designed Regional Prototypical Learning (RPL) module. We then introduce a novel Prototypical Representation Debiasing (PRD) module based on a two-way elimination mechanism which suppresses the disturbance of regional representations by a self-support, Multi-direction Self-debiasing (MS) block, and a support-query, Interactive Debiasing (ID) block. Finally, an Assembled Prediction (AP) module is devised to balance and integrate predictions of multiple prototypical representations learned using stacked PRD modules. Results obtained through extensive experiments on three publicly accessible medical imaging datasets demonstrate consistent improvements over the leading FSMIS methods. The source code is available at https://github.com/YazhouZhu19/PAMI.
Few-Shot Medical Image Segmentation via a Region-enhanced Prototypical Transformer
Sep 09, 2023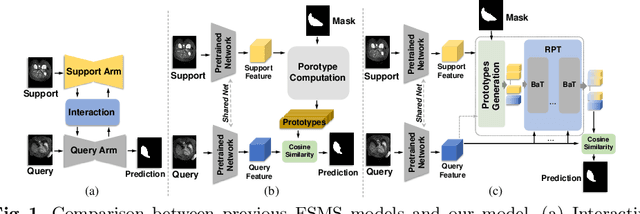
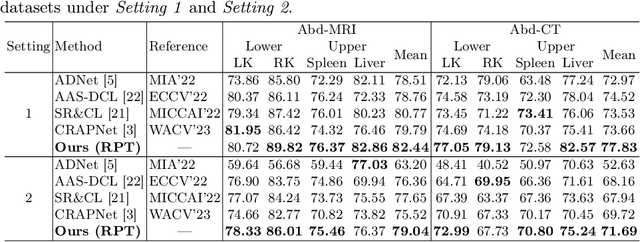

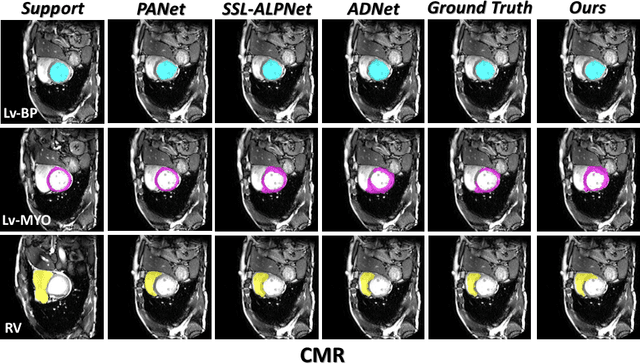
Automated segmentation of large volumes of medical images is often plagued by the limited availability of fully annotated data and the diversity of organ surface properties resulting from the use of different acquisition protocols for different patients. In this paper, we introduce a more promising few-shot learning-based method named Region-enhanced Prototypical Transformer (RPT) to mitigate the effects of large intra-class diversity/bias. First, a subdivision strategy is introduced to produce a collection of regional prototypes from the foreground of the support prototype. Second, a self-selection mechanism is proposed to incorporate into the Bias-alleviated Transformer (BaT) block to suppress or remove interferences present in the query prototype and regional support prototypes. By stacking BaT blocks, the proposed RPT can iteratively optimize the generated regional prototypes and finally produce rectified and more accurate global prototypes for Few-Shot Medical Image Segmentation (FSMS). Extensive experiments are conducted on three publicly available medical image datasets, and the obtained results show consistent improvements compared to state-of-the-art FSMS methods. The source code is available at: https://github.com/YazhouZhu19/RPT.
Mutual Balancing in State-Object Components for Compositional Zero-Shot Learning
Nov 19, 2022



Compositional Zero-Shot Learning (CZSL) aims to recognize unseen compositions from seen states and objects. The disparity between the manually labeled semantic information and its actual visual features causes a significant imbalance of visual deviation in the distribution of various object classes and state classes, which is ignored by existing methods. To ameliorate these issues, we consider the CZSL task as an unbalanced multi-label classification task and propose a novel method called MUtual balancing in STate-object components (MUST) for CZSL, which provides a balancing inductive bias for the model. In particular, we split the classification of the composition classes into two consecutive processes to analyze the entanglement of the two components to get additional knowledge in advance, which reflects the degree of visual deviation between the two components. We use the knowledge gained to modify the model's training process in order to generate more distinct class borders for classes with significant visual deviations. Extensive experiments demonstrate that our approach significantly outperforms the state-of-the-art on MIT-States, UT-Zappos, and C-GQA when combined with the basic CZSL frameworks, and it can improve various CZSL frameworks. Our codes are available on https://anonymous.4open.science/r/MUST_CGE/.
Part-aware Prototypical Graph Network for One-shot Skeleton-based Action Recognition
Aug 19, 2022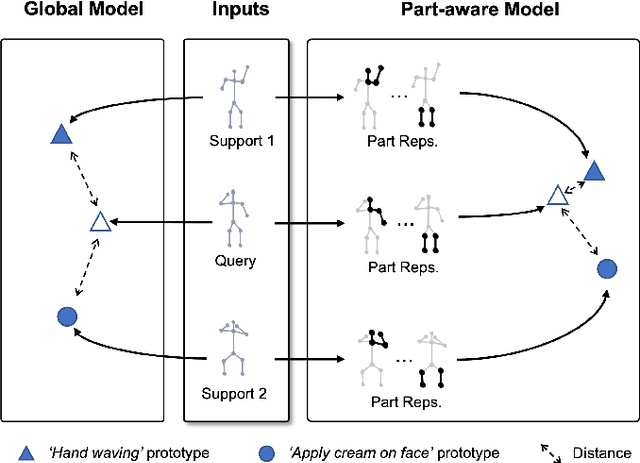
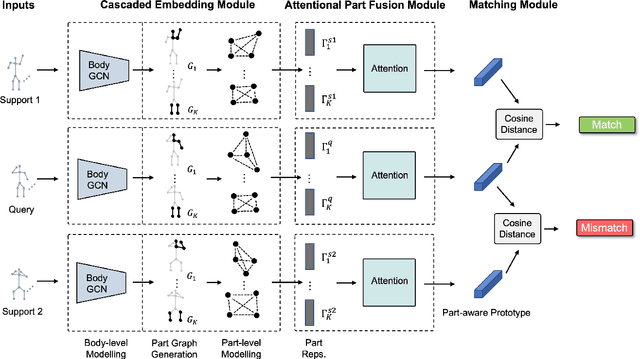
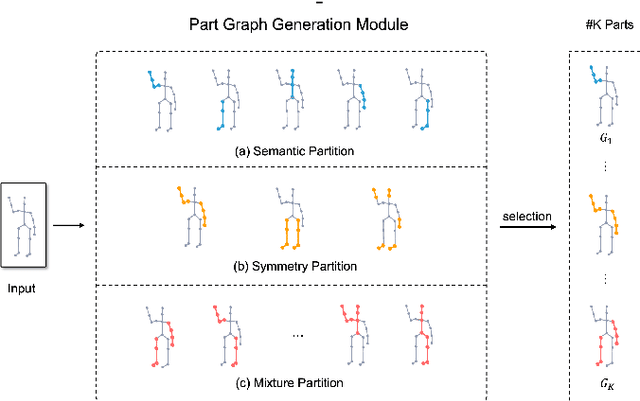
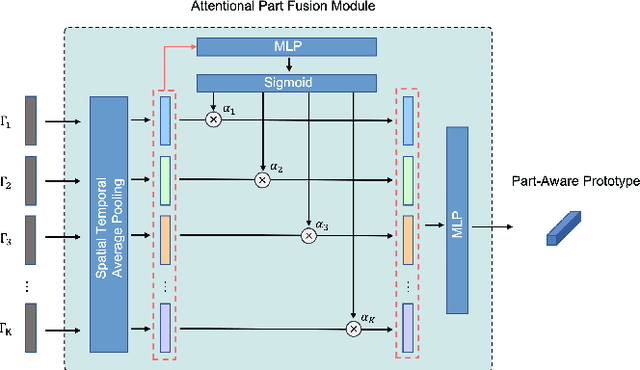
In this paper, we study the problem of one-shot skeleton-based action recognition, which poses unique challenges in learning transferable representation from base classes to novel classes, particularly for fine-grained actions. Existing meta-learning frameworks typically rely on the body-level representations in spatial dimension, which limits the generalisation to capture subtle visual differences in the fine-grained label space. To overcome the above limitation, we propose a part-aware prototypical representation for one-shot skeleton-based action recognition. Our method captures skeleton motion patterns at two distinctive spatial levels, one for global contexts among all body joints, referred to as body level, and the other attends to local spatial regions of body parts, referred to as the part level. We also devise a class-agnostic attention mechanism to highlight important parts for each action class. Specifically, we develop a part-aware prototypical graph network consisting of three modules: a cascaded embedding module for our dual-level modelling, an attention-based part fusion module to fuse parts and generate part-aware prototypes, and a matching module to perform classification with the part-aware representations. We demonstrate the effectiveness of our method on two public skeleton-based action recognition datasets: NTU RGB+D 120 and NW-UCLA.
Boosting Generative Zero-Shot Learning by Synthesizing Diverse Features with Attribute Augmentation
Dec 23, 2021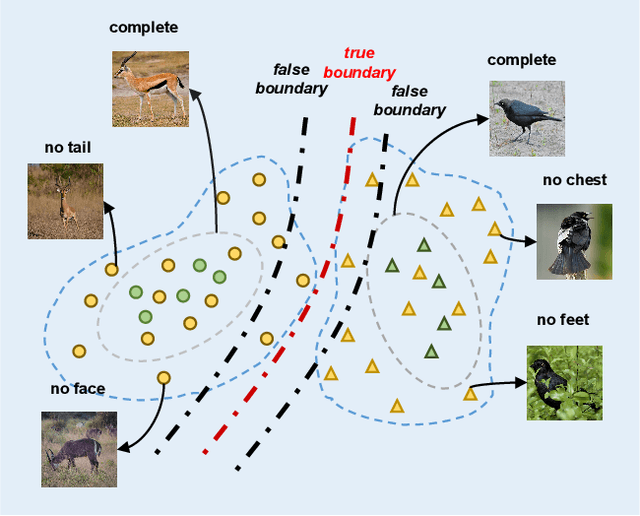
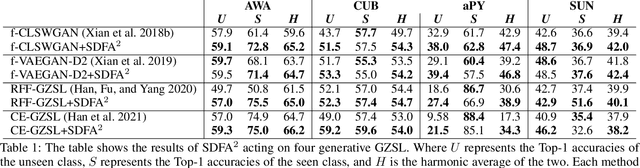
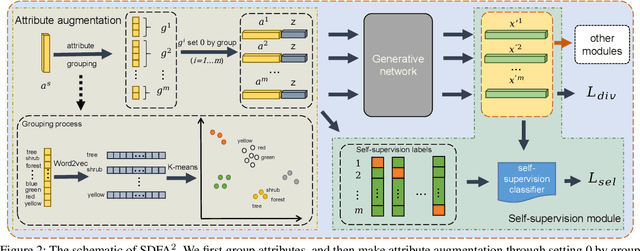
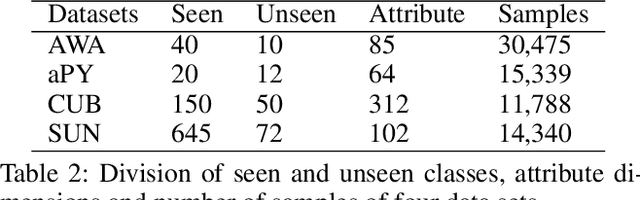
The recent advance in deep generative models outlines a promising perspective in the realm of Zero-Shot Learning (ZSL). Most generative ZSL methods use category semantic attributes plus a Gaussian noise to generate visual features. After generating unseen samples, this family of approaches effectively transforms the ZSL problem into a supervised classification scheme. However, the existing models use a single semantic attribute, which contains the complete attribute information of the category. The generated data also carry the complete attribute information, but in reality, visual samples usually have limited attributes. Therefore, the generated data from attribute could have incomplete semantics. Based on this fact, we propose a novel framework to boost ZSL by synthesizing diverse features. This method uses augmented semantic attributes to train the generative model, so as to simulate the real distribution of visual features. We evaluate the proposed model on four benchmark datasets, observing significant performance improvement against the state-of-the-art.