 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Segment Transformer for Action Segmentation
Feb 25, 2023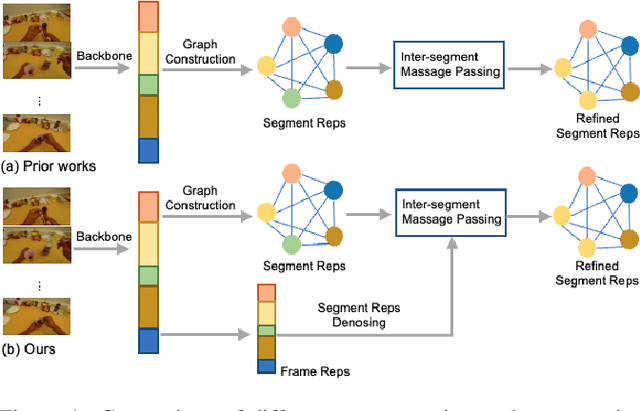



Recognizing human actions from untrimmed videos is an important task in activity understanding, and poses unique challenges in modeling long-range temporal relations. Recent works adopt a predict-and-refine strategy which converts an initial prediction to action segments for global context modeling. However, the generated segment representations are often noisy and exhibit inaccurate segment boundaries, over-segmentation and other problems. To deal with these issues, we propose an attention based approach which we call \textit{temporal segment transformer}, for joint segment relation modeling and denoising. The main idea is to denoise segment representations using attention between segment and frame representations, and also use inter-segment attention to capture temporal correlations between segments. The refined segment representations are used to predict action labels and adjust segment boundaries, and a final action segmentation is produced based on voting from segment masks. We show that this novel architecture achieves state-of-the-art accuracy on the popular 50Salads, GTEA and Breakfast benchmarks. We also conduct extensive ablations to demonstrate the effectiveness of different components of our design.
Human-Object Interaction Detection via Disentangled Transformer
Apr 20, 2022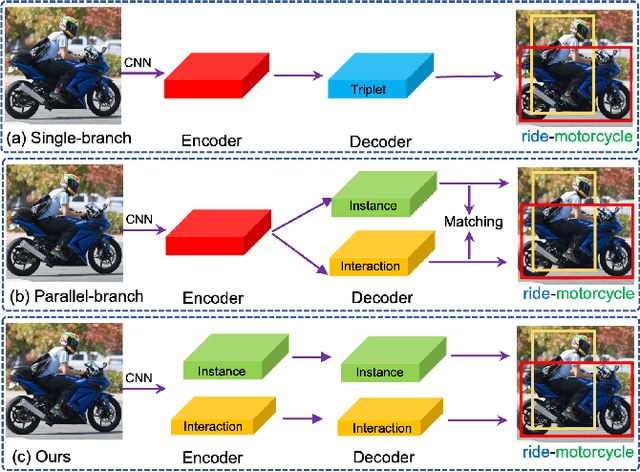



Human-Object Interaction Detection tackles the problem of joint localization and classification of human object interactions. Existing HOI transformers either adopt a single decoder for triplet prediction, or utilize two parallel decoders to detect individual objects and interactions separately, and compose triplets by a matching process. In contrast, we decouple the triplet prediction into human-object pair detection and interaction classification. Our main motivation is that detecting the human-object instances and classifying interactions accurately needs to learn representations that focus on different regions. To this end, we present Disentangled Transformer, where both encoder and decoder are disentangled to facilitate learning of two sub-tasks. To associate the predictions of disentangled decoders, we first generate a unified representation for HOI triplets with a base decoder, and then utilize it as input feature of each disentangled decoder. Extensive experiments show that our method outperforms prior work on two public HOI benchmarks by a sizeable margin. Code will be available.