 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCanvas: A Diffusion-base Unified Model for Text-in-Image Joint Generation
Jun 02, 2026Recent years have seen remarkable progress in unified vision-language models handling both multimodal understanding and generation within a single architecture. While autoregressive VLMs can reason across modalities, they fail to generate high-quality images. In contrast, diffusion models produce photorealistic visuals yet struggle to generate coherent text, making it challenging to develop a single unified model that can seamlessly handle both visual and text generation. Recent advances suggest that language can be effectively embedded within visual representations, allowing models to reason about textual semantics directly from images. To this end, we propose UniCanvas, a first attempt that unifies diffusion models to generate interleaved multimodal contents through text-in-image generation. Diffusion models naturally capture transformations on a shared pixel canvas, which can be viewed as world models of visual change. Instead of producing discrete text tokens, the model learns to represent language as visual patterns inside images, leveraging its inherent multimodal embedding space. This design allows the model to "draw" text naturally within a single pixel canvas during image synthesis, achieving seamless multimodal generation. Experiments demonstrate that UniCanvas improves performance over previous unified models, positioning text-in-image generation with diffusion models as a promising unified multimodal generation paradigm.
Fast Spatial Memory with Elastic Test-Time Training
Apr 08, 2026Large Chunk Test-Time Training (LaCT) has shown strong performance on long-context 3D reconstruction, but its fully plastic inference-time updates remain vulnerable to catastrophic forgetting and overfitting. As a result, LaCT is typically instantiated with a single large chunk spanning the full input sequence, falling short of the broader goal of handling arbitrarily long sequences in a single pass. We propose Elastic Test-Time Training inspired by elastic weight consolidation, that stabilizes LaCT fast-weight updates with a Fisher-weighted elastic prior around a maintained anchor state. The anchor evolves as an exponential moving average of past fast weights to balance stability and plasticity. Based on this updated architecture, we introduce Fast Spatial Memory (FSM), an efficient and scalable model for 4D reconstruction that learns spatiotemporal representations from long observation sequences and renders novel view-time combinations. We pre-trained FSM on large-scale curated 3D/4D data to capture the dynamics and semantics of complex spatial environments. Extensive experiments show that FSM supports fast adaptation over long sequences and delivers high-quality 3D/4D reconstruction with smaller chunks and mitigating the camera-interpolation shortcut. Overall, we hope to advance LaCT beyond the bounded single-chunk setting toward robust multi-chunk adaptation, a necessary step for generalization to genuinely longer sequences, while substantially alleviating the activation-memory bottleneck.
TalkCuts: A Large-Scale Dataset for Multi-Shot Human Speech Video Generation
Oct 08, 2025In this work, we present TalkCuts, a large-scale dataset designed to facilitate the study of multi-shot human speech video generation. Unlike existing datasets that focus on single-shot, static viewpoints, TalkCuts offers 164k clips totaling over 500 hours of high-quality human speech videos with diverse camera shots, including close-up, half-body, and full-body views. The dataset includes detailed textual descriptions, 2D keypoints and 3D SMPL-X motion annotations, covering over 10k identities, enabling multimodal learning and evaluation. As a first attempt to showcase the value of the dataset, we present Orator, an LLM-guided multi-modal generation framework as a simple baseline, where the language model functions as a multi-faceted director, orchestrating detailed specifications for camera transitions, speaker gesticulations, and vocal modulation. This architecture enables the synthesis of coherent long-form videos through our integrated multi-modal video generation module. Extensive experiments in both pose-guided and audio-driven settings show that training on TalkCuts significantly enhances the cinematographic coherence and visual appeal of generated multi-shot speech videos. We believe TalkCuts provides a strong foundation for future work in controllable, multi-shot speech video generation and broader multimodal learning.
GLUS: Global-Local Reasoning Unified into A Single Large Language Model for Video Segmentation
Apr 10, 2025
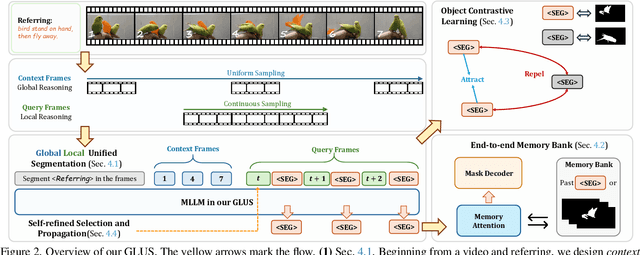
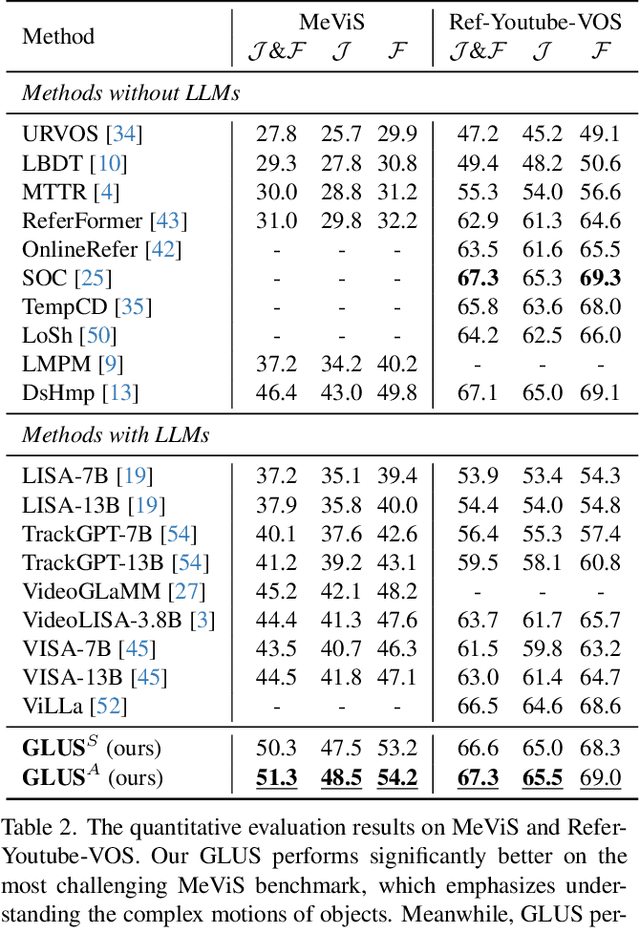
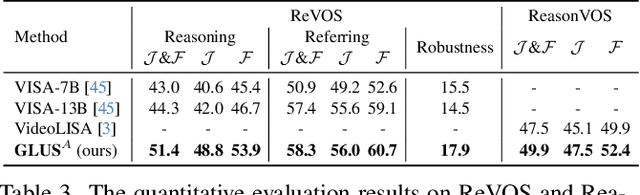
This paper proposes a novel framework utilizing multi-modal large language models (MLLMs) for referring video object segmentation (RefVOS). Previous MLLM-based methods commonly struggle with the dilemma between "Ref" and "VOS": they either specialize in understanding a few key frames (global reasoning) or tracking objects on continuous frames (local reasoning), and rely on external VOS or frame selectors to mitigate the other end of the challenge. However, our framework GLUS shows that global and local consistency can be unified into a single video segmentation MLLM: a set of sparse "context frames" provides global information, while a stream of continuous "query frames" conducts local object tracking. This is further supported by jointly training the MLLM with a pre-trained VOS memory bank to simultaneously digest short-range and long-range temporal information. To improve the information efficiency within the limited context window of MLLMs, we introduce object contrastive learning to distinguish hard false-positive objects and a self-refined framework to identify crucial frames and perform propagation. By collectively integrating these insights, our GLUS delivers a simple yet effective baseline, achieving new state-of-the-art for MLLMs on the MeViS and Ref-Youtube-VOS benchmark. Our project page is at https://glus-video.github.io/.
Freeze and Cluster: A Simple Baseline for Rehearsal-Free Continual Category Discovery
Mar 12, 2025This paper addresses the problem of Rehearsal-Free Continual Category Discovery (RF-CCD), which focuses on continuously identifying novel class by leveraging knowledge from labeled data. Existing methods typically train from scratch, overlooking the potential of base models, and often resort to data storage to prevent forgetting. Moreover, because RF-CCD encompasses both continual learning and novel class discovery, previous approaches have struggled to effectively integrate advanced techniques from these fields, resulting in less convincing comparisons and failing to reveal the unique challenges posed by RF-CCD. To address these challenges, we lead the way in integrating advancements from both domains and conducting extensive experiments and analyses. Our findings demonstrate that this integration can achieve state-of-the-art results, leading to the conclusion that in the presence of pre-trained models, the representation does not improve and may even degrade with the introduction of unlabeled data. To mitigate representation degradation, we propose a straightforward yet highly effective baseline method. This method first utilizes prior knowledge of known categories to estimate the number of novel classes. It then acquires representations using a model specifically trained on the base classes, generates high-quality pseudo-labels through k-means clustering, and trains only the classifier layer. We validate our conclusions and methods by conducting extensive experiments across multiple benchmarks, including the Stanford Cars, CUB, iNat, and Tiny-ImageNet datasets. The results clearly illustrate our findings, demonstrate the effectiveness of our baseline, and pave the way for future advancements in RF-CCD.
VCA: Video Curious Agent for Long Video Understanding
Dec 12, 2024
Long video understanding poses unique challenges due to their temporal complexity and low information density. Recent works address this task by sampling numerous frames or incorporating auxiliary tools using LLMs, both of which result in high computational costs. In this work, we introduce a curiosity-driven video agent with self-exploration capability, dubbed as VCA. Built upon VLMs, VCA autonomously navigates video segments and efficiently builds a comprehensive understanding of complex video sequences. Instead of directly sampling frames, VCA employs a tree-search structure to explore video segments and collect frames. Rather than relying on external feedback or reward, VCA leverages VLM's self-generated intrinsic reward to guide its exploration, enabling it to capture the most crucial information for reasoning. Experimental results on multiple long video benchmarks demonstrate our approach's superior effectiveness and efficiency.
Learning Video Representations without Natural Videos
Oct 31, 2024



In this paper, we show that useful video representations can be learned from synthetic videos and natural images, without incorporating natural videos in the training. We propose a progression of video datasets synthesized by simple generative processes, that model a growing set of natural video properties (e.g. motion, acceleration, and shape transformations). The downstream performance of video models pre-trained on these generated datasets gradually increases with the dataset progression. A VideoMAE model pre-trained on our synthetic videos closes 97.2% of the performance gap on UCF101 action classification between training from scratch and self-supervised pre-training from natural videos, and outperforms the pre-trained model on HMDB51. Introducing crops of static images to the pre-training stage results in similar performance to UCF101 pre-training and outperforms the UCF101 pre-trained model on 11 out of 14 out-of-distribution datasets of UCF101-P. Analyzing the low-level properties of the datasets, we identify correlations between frame diversity, frame similarity to natural data, and downstream performance. Our approach provides a more controllable and transparent alternative to video data curation processes for pre-training.
Composing Novel Classes: A Concept-Driven Approach to Generalized Category Discovery
Oct 17, 2024We tackle the generalized category discovery (GCD) problem, which aims to discover novel classes in unlabeled datasets by leveraging the knowledge of known classes. Previous works utilize the known class knowledge through shared representation spaces. Despite their progress, our analysis experiments show that novel classes can achieve impressive clustering results on the feature space of a known class pre-trained model, suggesting that existing methods may not fully utilize known class knowledge. To address it, we introduce a novel concept learning framework for GCD, named ConceptGCD, that categorizes concepts into two types: derivable and underivable from known class concepts, and adopts a stage-wise learning strategy to learn them separately. Specifically, our framework first extracts known class concepts by a known class pre-trained model and then produces derivable concepts from them by a generator layer with a covariance-augmented loss. Subsequently, we expand the generator layer to learn underivable concepts in a balanced manner ensured by a concept score normalization strategy and integrate a contrastive loss to preserve previously learned concepts. Extensive experiments on various benchmark datasets demonstrate the superiority of our approach over the previous state-of-the-art methods. Code will be available soon.
Computron: Serving Distributed Deep Learning Models with Model Parallel Swapping
Jun 24, 2023



Many of the most performant deep learning models today in fields like language and image understanding are fine-tuned models that contain billions of parameters. In anticipation of workloads that involve serving many of such large models to handle different tasks, we develop Computron, a system that uses memory swapping to serve multiple distributed models on a shared GPU cluster. Computron implements a model parallel swapping design that takes advantage of the aggregate CPU-GPU link bandwidth of a cluster to speed up model parameter transfers. This design makes swapping large models feasible and can improve resource utilization. We demonstrate that Computron successfully parallelizes model swapping on multiple GPUs, and we test it on randomized workloads to show how it can tolerate real world variability factors like burstiness and skewed request rates. Computron's source code is available at https://github.com/dlzou/computron.