 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DGS$^2$-TR: Scalable Second-Order Trust-Region Method for 3D Gaussian Splatting
Jan 30, 2026We propose 3DGS$^2$-TR,a second-order optimizer for accelerating the scene training problem in 3D Gaussian Splatting (3DGS). Unlike existing second-order approaches that rely on explicit or dense curvature representations, such as 3DGS-LM (Höllein et al., 2025) or 3DGS2 (Lan et al., 2025), our method approximates curvature using only the diagonal of the Hessian matrix, efficiently via Hutchinson's method. Our approach is fully matrix-free and has the same complexity as ADAM (Kingma, 2024), $O(n)$ in both computation and memory costs. To ensure stable optimization in the presence of strong nonlinearity in the 3DGS rasterization process, we introduce a parameter-wise trust-region technique based on the squared Hellinger distance, regularizing updates to Gaussian parameters. Under identical parameter initialization and without densification, 3DGS$^2$-TR is able to achieve better reconstruction quality on standard datasets, using 50% fewer training iterations compared to ADAM, while incurring less than 1GB of peak GPU memory overhead (17% more than ADAM and 85% less than 3DGS-LM), enabling scalability to very large scenes and potentially to distributed training settings.
Computron: Serving Distributed Deep Learning Models with Model Parallel Swapping
Jun 24, 2023



Many of the most performant deep learning models today in fields like language and image understanding are fine-tuned models that contain billions of parameters. In anticipation of workloads that involve serving many of such large models to handle different tasks, we develop Computron, a system that uses memory swapping to serve multiple distributed models on a shared GPU cluster. Computron implements a model parallel swapping design that takes advantage of the aggregate CPU-GPU link bandwidth of a cluster to speed up model parameter transfers. This design makes swapping large models feasible and can improve resource utilization. We demonstrate that Computron successfully parallelizes model swapping on multiple GPUs, and we test it on randomized workloads to show how it can tolerate real world variability factors like burstiness and skewed request rates. Computron's source code is available at https://github.com/dlzou/computron.
Distributed-Memory Sparse Kernels for Machine Learning
Mar 18, 2022
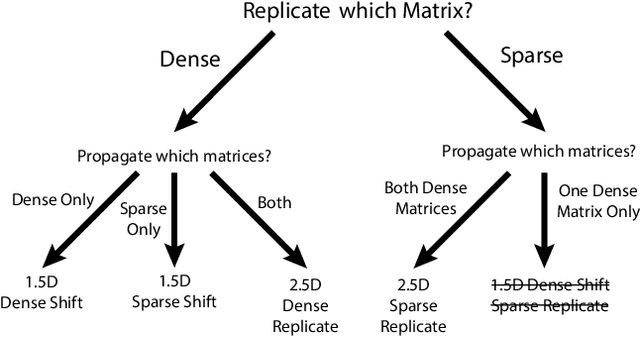

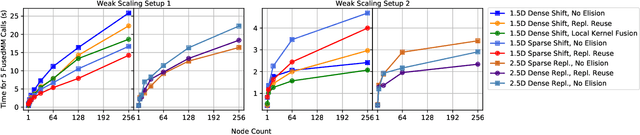
Sampled Dense Times Dense Matrix Multiplication (SDDMM) and Sparse Times Dense Matrix Multiplication (SpMM) appear in diverse settings, such as collaborative filtering, document clustering, and graph embedding. Frequently, the SDDMM output becomes the input sparse matrix for a subsequent SpMM operation. Existing work has focused on shared memory parallelization of these primitives. While there has been extensive analysis of communication-minimizing distributed 1.5D algorithms for SpMM, no such analysis exists for SDDMM or the back-to-back sequence of SDDMM and SpMM, termed FusedMM. We show that distributed memory 1.5D and 2.5D algorithms for SpMM can be converted to algorithms for SDDMM with identical communication costs and input / output data layouts. Further, we give two communication-eliding strategies to reduce costs further for FusedMM kernels: either reusing the replication of an input dense matrix for the SDDMM and SpMM in sequence, or fusing the local SDDMM and SpMM kernels. We benchmark FusedMM algorithms on Cori, a Cray XC40 at LBNL, using Erdos-Renyi random matrices and large real-world sparse matrices. On 256 nodes with 68 cores each, 1.5D FusedMM algorithms using either communication eliding approach can save at least 30% of time spent exclusively in communication compared to executing a distributed-memory SpMM and SDDMM kernel in sequence. On real-world matrices with hundreds of millions of edges, all of our algorithms exhibit at least a 10x speedup over the SpMM algorithm in PETSc. On these matrices, our communication-eliding techniques exhibit runtimes up to 1.6 times faster than an unoptimized sequence of SDDMM and SpMM. We embed and test the scaling of our algorithms in real-world applications, including collaborative filtering via alternating-least-squares and inference for attention-based graph neural networks.
CoSA: Scheduling by Constrained Optimization for Spatial Accelerators
May 05, 2021
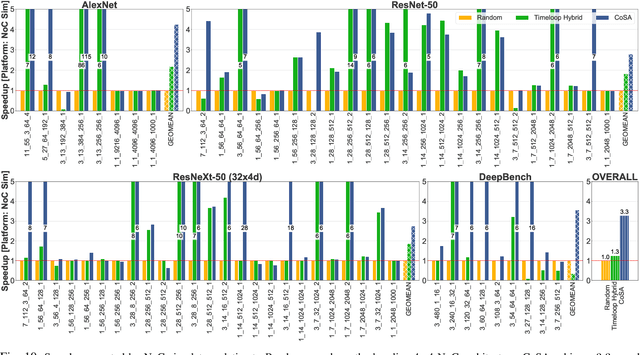
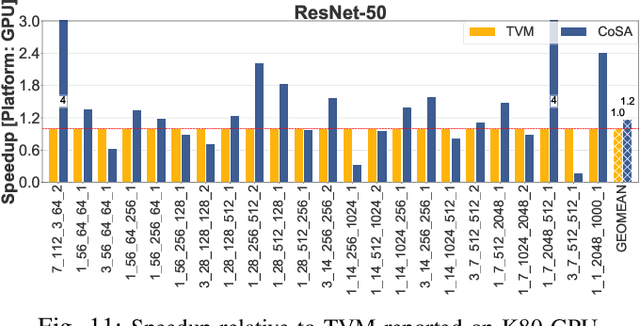
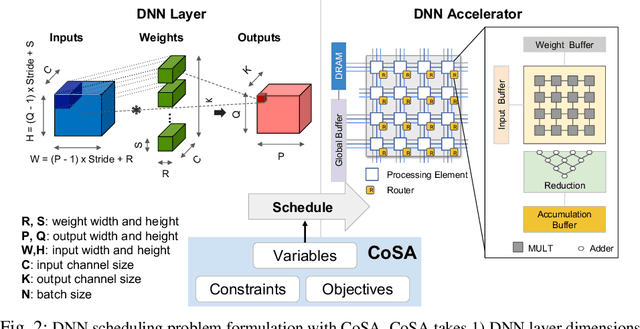
Recent advances in Deep Neural Networks (DNNs) have led to active development of specialized DNN accelerators, many of which feature a large number of processing elements laid out spatially, together with a multi-level memory hierarchy and flexible interconnect. While DNN accelerators can take advantage of data reuse and achieve high peak throughput, they also expose a large number of runtime parameters to the programmers who need to explicitly manage how computation is scheduled both spatially and temporally. In fact, different scheduling choices can lead to wide variations in performance and efficiency, motivating the need for a fast and efficient search strategy to navigate the vast scheduling space. To address this challenge, we present CoSA, a constrained-optimization-based approach for scheduling DNN accelerators. As opposed to existing approaches that either rely on designers' heuristics or iterative methods to navigate the search space, CoSA expresses scheduling decisions as a constrained-optimization problem that can be deterministically solved using mathematical optimization techniques. Specifically, CoSA leverages the regularities in DNN operators and hardware to formulate the DNN scheduling space into a mixed-integer programming (MIP) problem with algorithmic and architectural constraints, which can be solved to automatically generate a highly efficient schedule in one shot. We demonstrate that CoSA-generated schedules significantly outperform state-of-the-art approaches by a geometric mean of up to 2.5x across a wide range of DNN networks while improving the time-to-solution by 90x.
Avoiding Communication in Logistic Regression
Nov 16, 2020
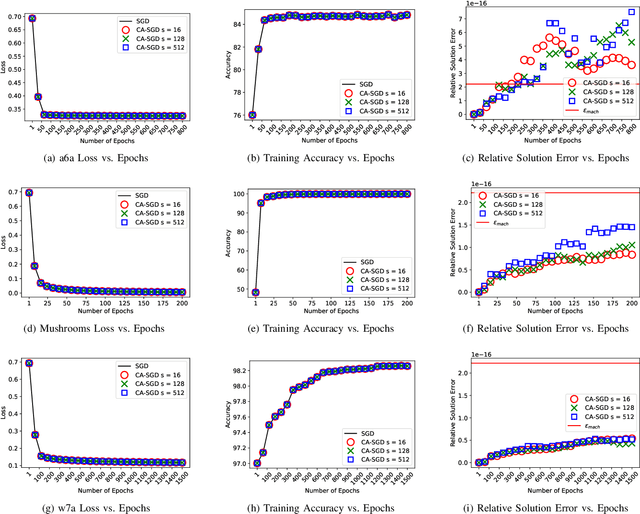
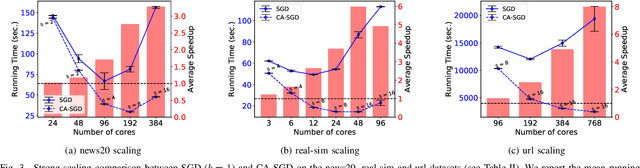
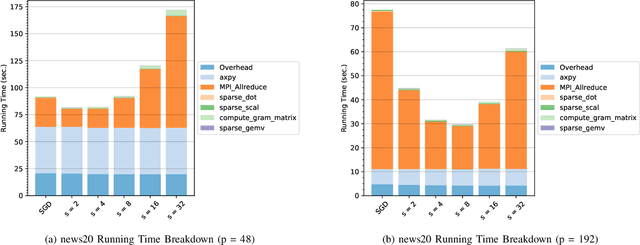
Stochastic gradient descent (SGD) is one of the most widely used optimization methods for solving various machine learning problems. SGD solves an optimization problem by iteratively sampling a few data points from the input data, computing gradients for the selected data points, and updating the solution. However, in a parallel setting, SGD requires interprocess communication at every iteration. We introduce a new communication-avoiding technique for solving the logistic regression problem using SGD. This technique re-organizes the SGD computations into a form that communicates every $s$ iterations instead of every iteration, where $s$ is a tuning parameter. We prove theoretical flops, bandwidth, and latency upper bounds for SGD and its new communication-avoiding variant. Furthermore, we show experimental results that illustrate that the new Communication-Avoiding SGD (CA-SGD) method can achieve speedups of up to $4.97\times$ on a high-performance Infiniband cluster without altering the convergence behavior or accuracy.
Training EfficientNets at Supercomputer Scale: 83% ImageNet Top-1 Accuracy in One Hour
Nov 05, 2020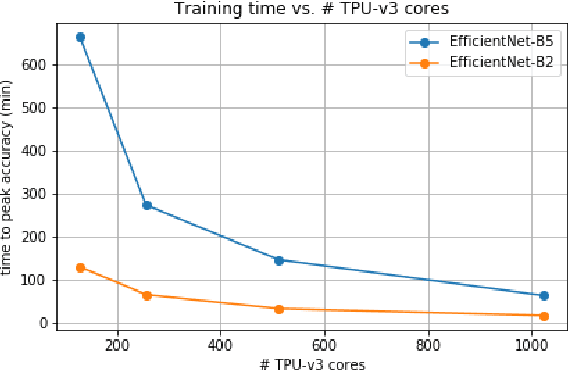
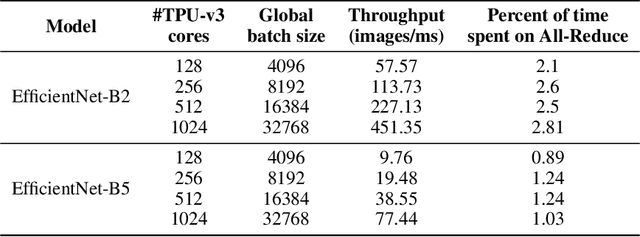
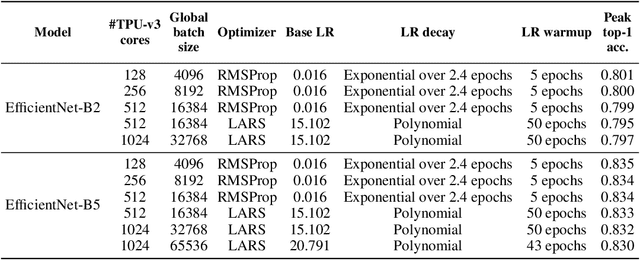
EfficientNets are a family of state-of-the-art image classification models based on efficiently scaled convolutional neural networks. Currently, EfficientNets can take on the order of days to train; for example, training an EfficientNet-B0 model takes 23 hours on a Cloud TPU v2-8 node. In this paper, we explore techniques to scale up the training of EfficientNets on TPU-v3 Pods with 2048 cores, motivated by speedups that can be achieved when training at such scales. We discuss optimizations required to scale training to a batch size of 65536 on 1024 TPU-v3 cores, such as selecting large batch optimizers and learning rate schedules as well as utilizing distributed evaluation and batch normalization techniques. Additionally, we present timing and performance benchmarks for EfficientNet models trained on the ImageNet dataset in order to analyze the behavior of EfficientNets at scale. With our optimizations, we are able to train EfficientNet on ImageNet to an accuracy of 83% in 1 hour and 4 minutes.
The Limit of the Batch Size
Jun 15, 2020



Large-batch training is an efficient approach for current distributed deep learning systems. It has enabled researchers to reduce the ImageNet/ResNet-50 training from 29 hours to around 1 minute. In this paper, we focus on studying the limit of the batch size. We think it may provide a guidance to AI supercomputer and algorithm designers. We provide detailed numerical optimization instructions for step-by-step comparison. Moreover, it is important to understand the generalization and optimization performance of huge batch training. Hoffer et al. introduced "ultra-slow diffusion" theory to large-batch training. However, our experiments show contradictory results with the conclusion of Hoffer et al. We provide comprehensive experimental results and detailed analysis to study the limitations of batch size scaling and "ultra-slow diffusion" theory. For the first time we scale the batch size on ImageNet to at least a magnitude larger than all previous work, and provide detailed studies on the performance of many state-of-the-art optimization schemes under this setting. We propose an optimization recipe that is able to improve the top-1 test accuracy by 18% compared to the baseline.
Auto-Precision Scaling for Distributed Deep Learning
Nov 20, 2019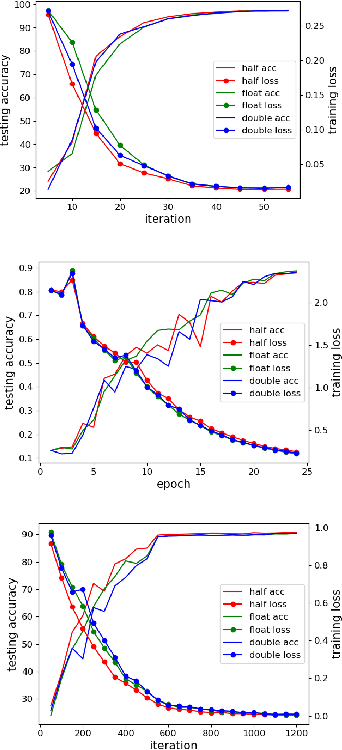
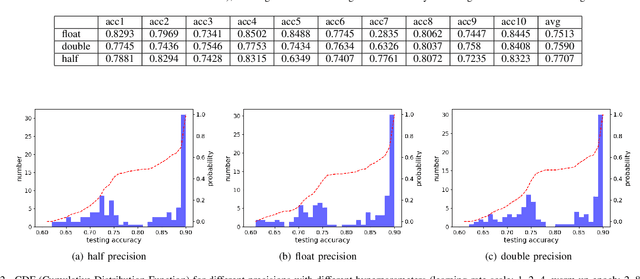
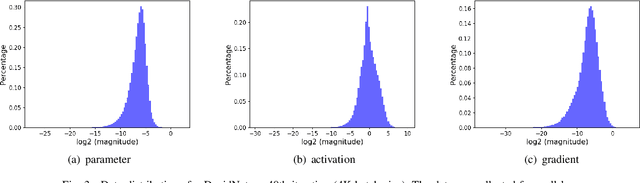

In recent years, large-batch optimization is becoming the key of distributed deep learning. However, large-batch optimization is hard. Straightforwardly porting the code often leads to a significant loss in testing accuracy. As some researchers suggested that large batch optimization leads to a low generalization performance, and they further conjectured that large-batch training needs a higher floating-point precision to achieve a higher generalization performance. To solve this problem, we conduct an open study in this paper. Our target is to find the number of bits that large-batch training needs. To do so, we need a system for customized precision study. However, state-of-the-art systems have some limitations that lower the efficiency of developers and researchers. To solve this problem, we design and implement our own system CPD: A High Performance System for Customized-Precision Distributed DL. In our experiments, our application often loses accuracy if we use a very-low precision (e.g. 8 bits or 4 bits). To solve this problem, we proposed the APS (Auto-Precision-Scaling) algorithm, which is a layer-wise adaptive scheme for gradients shifting. With APS, we are able to make the large-batch training converge with only 4 bits.
Reducing BERT Pre-Training Time from 3 Days to 76 Minutes
Apr 01, 2019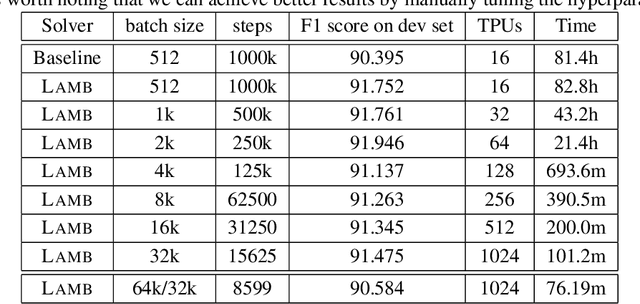

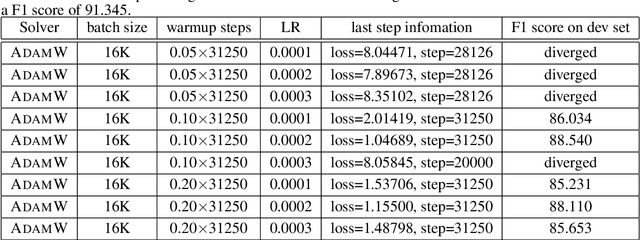

Large-batch training is key to speeding up deep neural network training in large distributed systems. However, large-batch training is difficult because it produces a generalization gap. Straightforward optimization often leads to accuracy loss on the test set. BERT \cite{devlin2018bert} is a state-of-the-art deep learning model that builds on top of deep bidirectional transformers for language understanding. Previous large-batch training techniques do not perform well for BERT when we scale the batch size (e.g. beyond 8192). BERT pre-training also takes a long time to finish (around three days on 16 TPUv3 chips). To solve this problem, we propose the LAMB optimizer, which helps us to scale the batch size to 65536 without losing accuracy. LAMB is a general optimizer that works for both small and large batch sizes and does not need hyper-parameter tuning besides the learning rate. The baseline BERT-Large model needs 1 million iterations to finish pre-training, while LAMB with batch size 65536/32768 only needs 8599 iterations. We push the batch size to the memory limit of a TPUv3 pod and can finish BERT training in 76 minutes.
Large-Batch Training for LSTM and Beyond
Jan 24, 2019

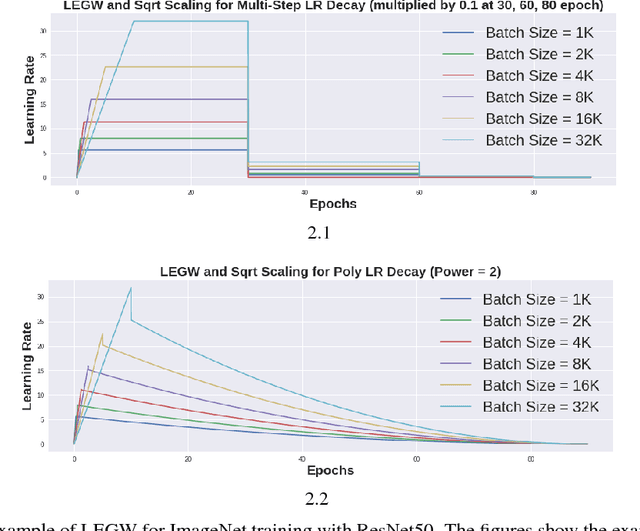
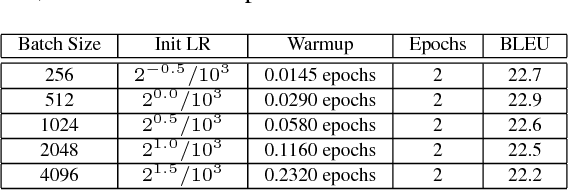
Large-batch training approaches have enabled researchers to utilize large-scale distributed processing and greatly accelerate deep-neural net (DNN) training. For example, by scaling the batch size from 256 to 32K, researchers have been able to reduce the training time of ResNet50 on ImageNet from 29 hours to 2.2 minutes (Ying et al., 2018). In this paper, we propose a new approach called linear-epoch gradual-warmup (LEGW) for better large-batch training. With LEGW, we are able to conduct large-batch training for both CNNs and RNNs with the Sqrt Scaling scheme. LEGW enables Sqrt Scaling scheme to be useful in practice and as a result we achieve much better results than the Linear Scaling learning rate scheme. For LSTM applications, we are able to scale the batch size by a factor of 64 without losing accuracy and without tuning the hyper-parameters. For CNN applications, LEGW is able to achieve the same accuracy even as we scale the batch size to 32K. LEGW works better than previous large-batch auto-tuning techniques. LEGW achieves a 5.3X average speedup over the baselines for four LSTM-based applications on the same hardware. We also provide some theoretical explanations for LEGW.