 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-Precision Communication-Avoiding SGD for Generalized Linear Models on GPUs
Jun 16, 2026Distributed stochastic gradient descent (SGD) is limited by communication rather than computation, since each iteration requires an AllReduce across processes. Communication-avoiding SGD (CA-SGD) amortizes communication over $s$ iterations by replacing $s$ consecutive AllReduces with a single AllReduce of an $sb\times sb$ Gram matrix, trading more computation and bandwidth for fewer synchronization points. Modern GPUs with matrix hardware and reduced-precision formats offset this by accelerating the Gram GEMM and shrinking BF16 traffic. We study mixed-precision CA-SGD for generalized linear models on NVIDIA GPUs. Our finite-precision analysis decomposes the local rounding error of one CA-SGD outer iteration into nine independent precision choices, depending on the hardware only through its low-precision unit roundoffs, so the resulting recipes transfer in principle across GPU generations. The recipe stores the input matrix and margin vector in low precision, computes the Gram matrix from low-precision inputs with high-precision accumulation, communicates it in high precision, and performs the inner recurrence and weight updates in high precision. On NERSC Perlmutter A100 GPUs, mixed-precision CA-SGD matches FP32 SGD loss within $0.5\%$ on logistic, linear, and Poisson problems and reaches $5.1$--$6.8\times$ speedup over FP32 SGD on epsilon, SUSY, HIGGS, synth, and Poisson-synth. Our software is available at https://doi.org/10.5281/zenodo.20448273
Communication-Avoiding Linear Algebraic Kernel K-Means on GPUs
Jan 23, 2026Clustering is an important tool in data analysis, with K-means being popular for its simplicity and versatility. However, it cannot handle non-linearly separable clusters. Kernel K-means addresses this limitation but requires a large kernel matrix, making it computationally and memory intensive. Prior work has accelerated Kernel K-means by formulating it using sparse linear algebra primitives and implementing it on a single GPU. However, that approach cannot run on datasets with more than approximately 80,000 samples due to limited GPU memory. In this work, we address this issue by presenting a suite of distributed-memory parallel algorithms for large-scale Kernel K-means clustering on multi-GPU systems. Our approach maps the most computationally expensive components of Kernel K-means onto communication-efficient distributed linear algebra primitives uniquely tailored for Kernel K-means, enabling highly scalable implementations that efficiently cluster million-scale datasets. Central to our work is the design of partitioning schemes that enable communication-efficient composition of the linear algebra primitives that appear in Kernel K-means. Our 1.5D algorithm consistently achieves the highest performance, enabling Kernel K-means to scale to data one to two orders of magnitude larger than previously practical. On 256 GPUs, it achieves a geometric mean weak scaling efficiency of $79.7\%$ and a geometric mean strong scaling speedup of $4.2\times$. Compared to our 1D algorithm, the 1.5D approach achieves up to a $3.6\times$ speedup on 256 GPUs and reduces clustering time from over an hour to under two seconds relative to a single-GPU sliding window implementation. Our results show that distributed algorithms designed with application-specific linear algebraic formulations can achieve substantial performance improvement.
Communication-Efficient, 2D Parallel Stochastic Gradient Descent for Distributed-Memory Optimization
Jan 13, 2025Distributed-memory implementations of numerical optimization algorithm, such as stochastic gradient descent (SGD), require interprocessor communication at every iteration of the algorithm. On modern distributed-memory clusters where communication is more expensive than computation, the scalability and performance of these algorithms are limited by communication cost. This work generalizes prior work on 1D $s$-step SGD and 1D Federated SGD with Averaging (FedAvg) to yield a 2D parallel SGD method (HybridSGD) which attains a continuous performance trade off between the two baseline algorithms. We present theoretical analysis which show the convergence, computation, communication, and memory trade offs between $s$-step SGD, FedAvg, 2D parallel SGD, and other parallel SGD variants. We implement all algorithms in C++ and MPI and evaluate their performance on a Cray EX supercomputing system. Our empirical results show that HybridSGD achieves better convergence than FedAvg at similar processor scales while attaining speedups of $5.3\times$ over $s$-step SGD and speedups up to $121\times$ over FedAvg when used to solve binary classification tasks using the convex, logistic regression model on datasets obtained from the LIBSVM repository.
Scalable Dual Coordinate Descent for Kernel Methods
Jun 26, 2024



Dual Coordinate Descent (DCD) and Block Dual Coordinate Descent (BDCD) are important iterative methods for solving convex optimization problems. In this work, we develop scalable DCD and BDCD methods for the kernel support vector machines (K-SVM) and kernel ridge regression (K-RR) problems. On distributed-memory parallel machines the scalability of these methods is limited by the need to communicate every iteration. On modern hardware where communication is orders of magnitude more expensive, the running time of the DCD and BDCD methods is dominated by communication cost. We address this communication bottleneck by deriving $s$-step variants of DCD and BDCD for solving the K-SVM and K-RR problems, respectively. The $s$-step variants reduce the frequency of communication by a tunable factor of $s$ at the expense of additional bandwidth and computation. The $s$-step variants compute the same solution as the existing methods in exact arithmetic. We perform numerical experiments to illustrate that the $s$-step variants are also numerically stable in finite-arithmetic, even for large values of $s$. We perform theoretical analysis to bound the computation and communication costs of the newly designed variants, up to leading order. Finally, we develop high performance implementations written in C and MPI and present scaling experiments performed on a Cray EX cluster. The new $s$-step variants achieved strong scaling speedups of up to $9.8\times$ over existing methods using up to $512$ cores.
Sequential and Shared-Memory Parallel Algorithms for Partitioned Local Depths
Jul 31, 2023



In this work, we design, analyze, and optimize sequential and shared-memory parallel algorithms for partitioned local depths (PaLD). Given a set of data points and pairwise distances, PaLD is a method for identifying strength of pairwise relationships based on relative distances, enabling the identification of strong ties within dense and sparse communities even if their sizes and within-community absolute distances vary greatly. We design two algorithmic variants that perform community structure analysis through triplet comparisons of pairwise distances. We present theoretical analyses of computation and communication costs and prove that the sequential algorithms are communication optimal, up to constant factors. We introduce performance optimization strategies that yield sequential speedups of up to $29\times$ over a baseline sequential implementation and parallel speedups of up to $19.4\times$ over optimized sequential implementations using up to $32$ threads on an Intel multicore CPU.
Avoiding Communication in Logistic Regression
Nov 16, 2020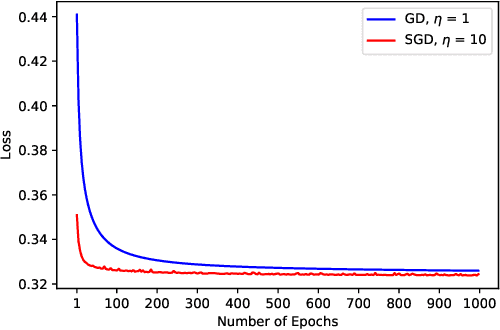
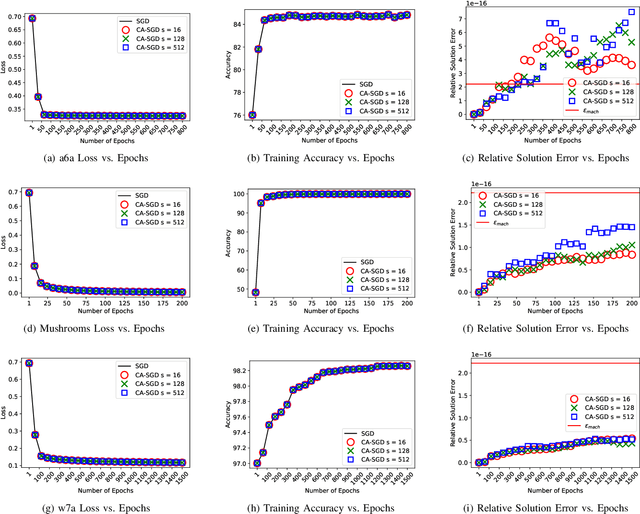
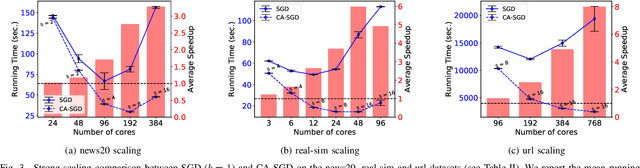
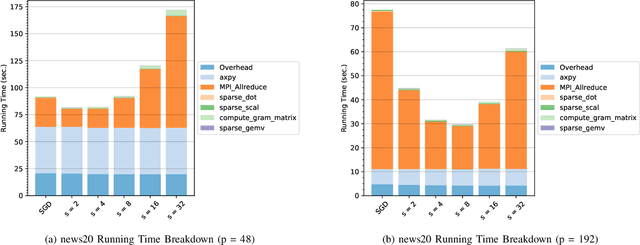
Stochastic gradient descent (SGD) is one of the most widely used optimization methods for solving various machine learning problems. SGD solves an optimization problem by iteratively sampling a few data points from the input data, computing gradients for the selected data points, and updating the solution. However, in a parallel setting, SGD requires interprocess communication at every iteration. We introduce a new communication-avoiding technique for solving the logistic regression problem using SGD. This technique re-organizes the SGD computations into a form that communicates every $s$ iterations instead of every iteration, where $s$ is a tuning parameter. We prove theoretical flops, bandwidth, and latency upper bounds for SGD and its new communication-avoiding variant. Furthermore, we show experimental results that illustrate that the new Communication-Avoiding SGD (CA-SGD) method can achieve speedups of up to $4.97\times$ on a high-performance Infiniband cluster without altering the convergence behavior or accuracy.
AdaBatch: Adaptive Batch Sizes for Training Deep Neural Networks
Feb 14, 2018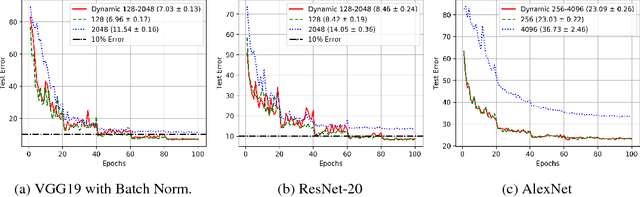

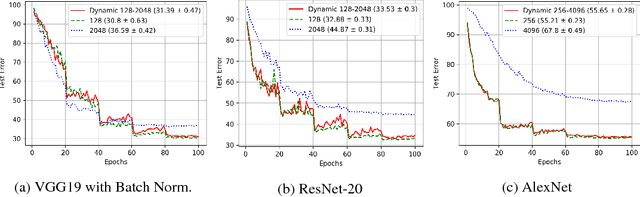

Training deep neural networks with Stochastic Gradient Descent, or its variants, requires careful choice of both learning rate and batch size. While smaller batch sizes generally converge in fewer training epochs, larger batch sizes offer more parallelism and hence better computational efficiency. We have developed a new training approach that, rather than statically choosing a single batch size for all epochs, adaptively increases the batch size during the training process. Our method delivers the convergence rate of small batch sizes while achieving performance similar to large batch sizes. We analyse our approach using the standard AlexNet, ResNet, and VGG networks operating on the popular CIFAR-10, CIFAR-100, and ImageNet datasets. Our results demonstrate that learning with adaptive batch sizes can improve performance by factors of up to 6.25 on 4 NVIDIA Tesla P100 GPUs while changing accuracy by less than 1% relative to training with fixed batch sizes.
Avoiding Synchronization in First-Order Methods for Sparse Convex Optimization
Dec 17, 2017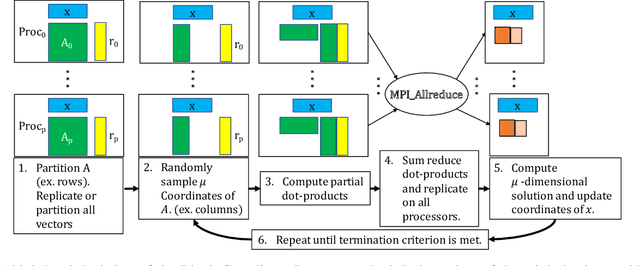
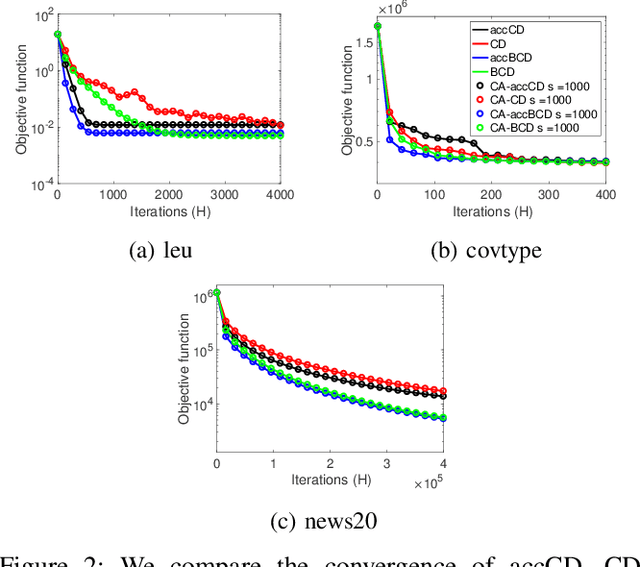
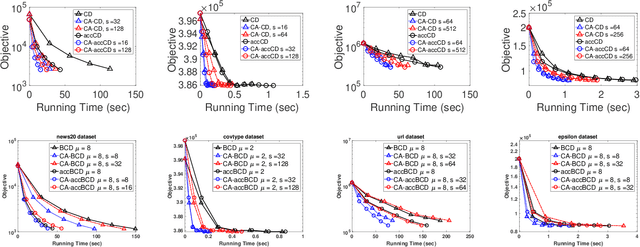
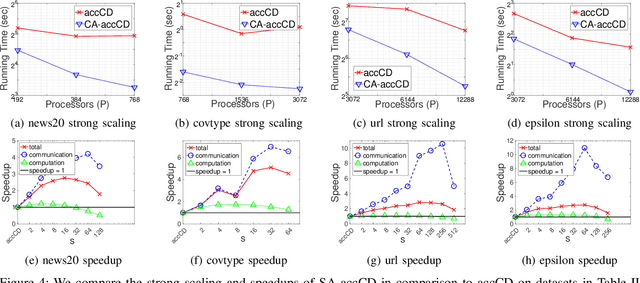
Parallel computing has played an important role in speeding up convex optimization methods for big data analytics and large-scale machine learning (ML). However, the scalability of these optimization methods is inhibited by the cost of communicating and synchronizing processors in a parallel setting. Iterative ML methods are particularly sensitive to communication cost since they often require communication every iteration. In this work, we extend well-known techniques from Communication-Avoiding Krylov subspace methods to first-order, block coordinate descent methods for Support Vector Machines and Proximal Least-Squares problems. Our Synchronization-Avoiding (SA) variants reduce the latency cost by a tunable factor of $s$ at the expense of a factor of $s$ increase in flops and bandwidth costs. We show that the SA-variants are numerically stable and can attain large speedups of up to $5.1\times$ on a Cray XC30 supercomputer.
Avoiding Communication in Proximal Methods for Convex Optimization Problems
Oct 24, 2017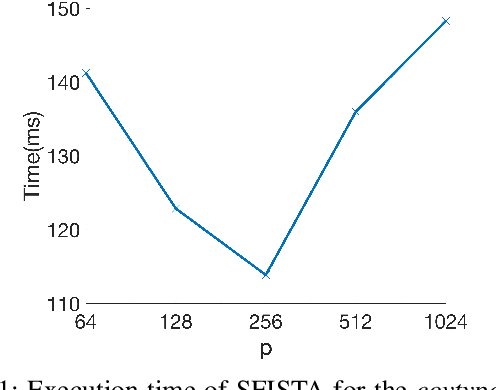
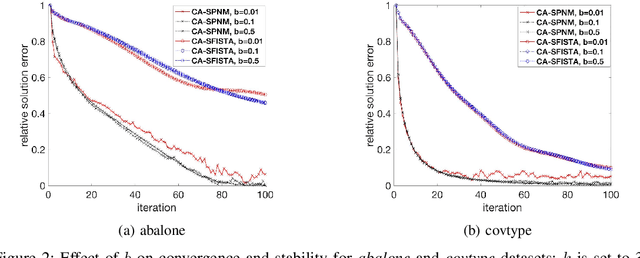
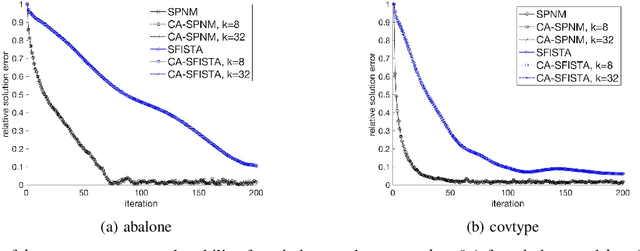
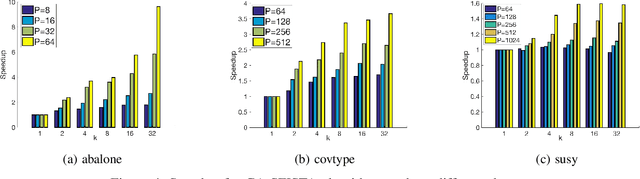
The fast iterative soft thresholding algorithm (FISTA) is used to solve convex regularized optimization problems in machine learning. Distributed implementations of the algorithm have become popular since they enable the analysis of large datasets. However, existing formulations of FISTA communicate data at every iteration which reduces its performance on modern distributed architectures. The communication costs of FISTA, including bandwidth and latency costs, is closely tied to the mathematical formulation of the algorithm. This work reformulates FISTA to communicate data at every k iterations and reduce data communication when operating on large data sets. We formulate the algorithm for two different optimization methods on the Lasso problem and show that the latency cost is reduced by a factor of k while bandwidth and floating-point operation costs remain the same. The convergence rates and stability properties of the reformulated algorithms are similar to the standard formulations. The performance of communication-avoiding FISTA and Proximal Newton methods is evaluated on 1 to 1024 nodes for multiple benchmarks and demonstrate average speedups of 3-10x with scaling properties that outperform the classical algorithms.