 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
TENGraD: Time-Efficient Natural Gradient Descent with Exact Fisher-Block Inversion
Jun 07, 2021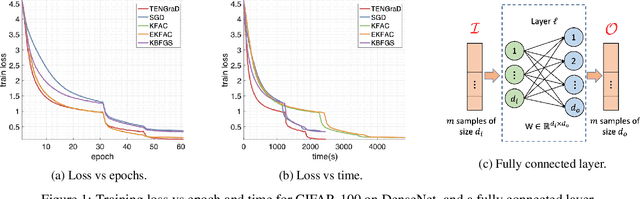

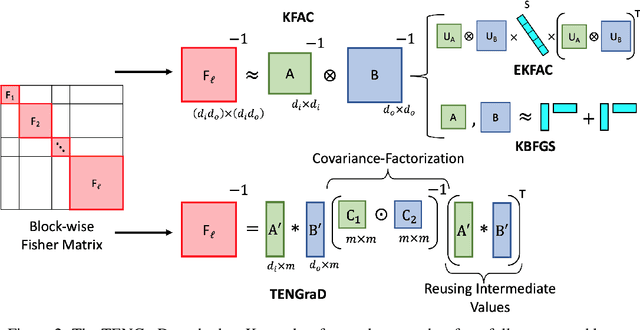
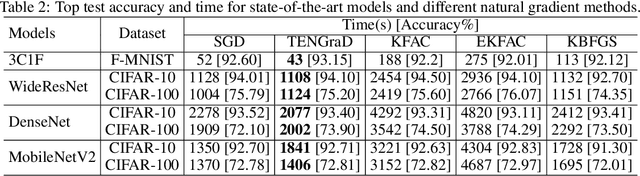
This work proposes a time-efficient Natural Gradient Descent method, called TENGraD, with linear convergence guarantees. Computing the inverse of the neural network's Fisher information matrix is expensive in NGD because the Fisher matrix is large. Approximate NGD methods such as KFAC attempt to improve NGD's running time and practical application by reducing the Fisher matrix inversion cost with approximation. However, the approximations do not reduce the overall time significantly and lead to less accurate parameter updates and loss of curvature information. TENGraD improves the time efficiency of NGD by computing Fisher block inverses with a computationally efficient covariance factorization and reuse method. It computes the inverse of each block exactly using the Woodbury matrix identity to preserve curvature information while admitting (linear) fast convergence rates. Our experiments on image classification tasks for state-of-the-art deep neural architecture on CIFAR-10, CIFAR-100, and Fashion-MNIST show that TENGraD significantly outperforms state-of-the-art NGD methods and often stochastic gradient descent in wall-clock time.
ASYNC: Asynchronous Machine Learning on Distributed Systems
Jul 27, 2019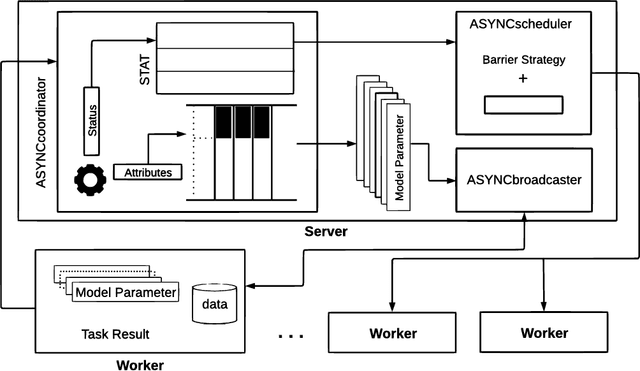

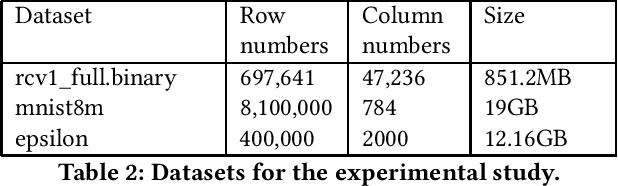
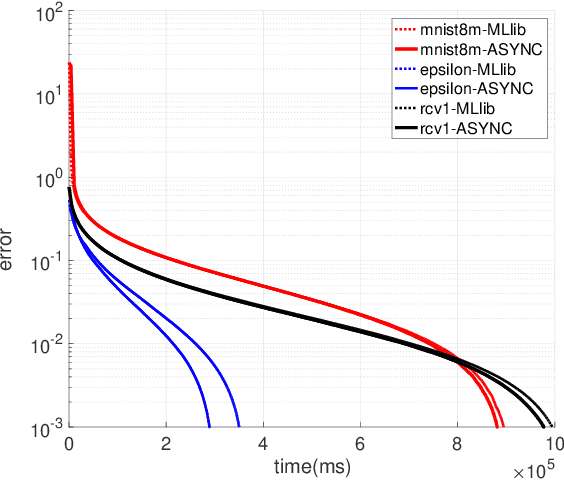
ASYNC is a framework that supports the implementation of asynchronous machine learning methods on cloud and distributed computing platforms. The popularity of asynchronous optimization methods has increased in distributed machine learning. However, their applicability and practical experimentation on distributed systems are limited because current engines do not support many of the algorithmic features of asynchronous optimization methods. ASYNC implements the functionality and the API to provide practitioners with a framework to develop and study asynchronous machine learning methods and execute them on cloud and distributed platforms. The synchronous and asynchronous variants of two well-known optimization methods, stochastic gradient descent and SAGA, are implemented in ASYNC and examples of implementing other algorithms are also provided.
Avoiding Communication in Proximal Methods for Convex Optimization Problems
Oct 24, 2017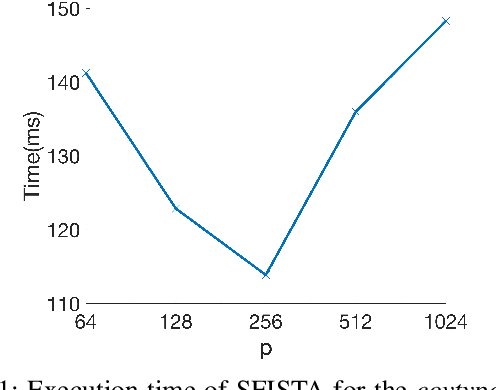
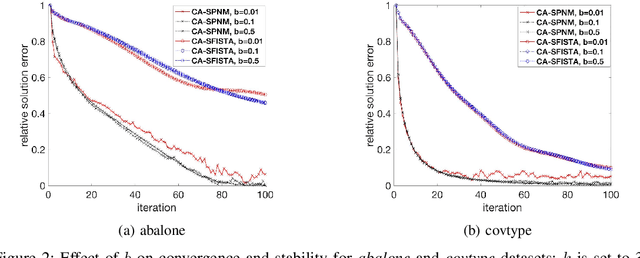
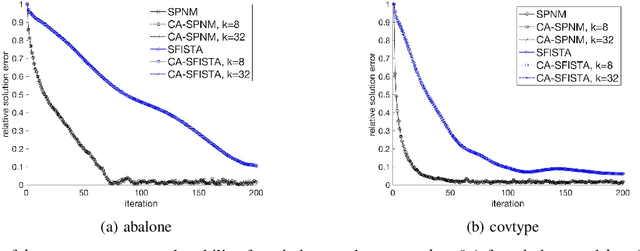
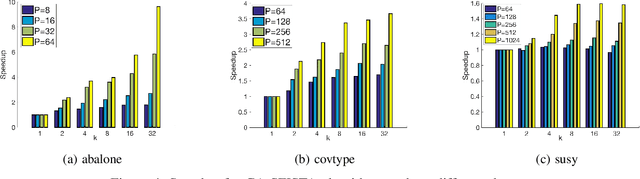
The fast iterative soft thresholding algorithm (FISTA) is used to solve convex regularized optimization problems in machine learning. Distributed implementations of the algorithm have become popular since they enable the analysis of large datasets. However, existing formulations of FISTA communicate data at every iteration which reduces its performance on modern distributed architectures. The communication costs of FISTA, including bandwidth and latency costs, is closely tied to the mathematical formulation of the algorithm. This work reformulates FISTA to communicate data at every k iterations and reduce data communication when operating on large data sets. We formulate the algorithm for two different optimization methods on the Lasso problem and show that the latency cost is reduced by a factor of k while bandwidth and floating-point operation costs remain the same. The convergence rates and stability properties of the reformulated algorithms are similar to the standard formulations. The performance of communication-avoiding FISTA and Proximal Newton methods is evaluated on 1 to 1024 nodes for multiple benchmarks and demonstrate average speedups of 3-10x with scaling properties that outperform the classical algorithms.