 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRényi Differential Privacy for Heavy-Tailed SDEs via Fractional Poincaré Inequalities
Nov 19, 2025Characterizing the differential privacy (DP) of learning algorithms has become a major challenge in recent years. In parallel, many studies suggested investigating the behavior of stochastic gradient descent (SGD) with heavy-tailed noise, both as a model for modern deep learning models and to improve their performance. However, most DP bounds focus on light-tailed noise, where satisfactory guarantees have been obtained but the proposed techniques do not directly extend to the heavy-tailed setting. Recently, the first DP guarantees for heavy-tailed SGD were obtained. These results provide $(0,δ)$-DP guarantees without requiring gradient clipping. Despite casting new light on the link between DP and heavy-tailed algorithms, these results have a strong dependence on the number of parameters and cannot be extended to other DP notions like the well-established Rényi differential privacy (RDP). In this work, we propose to address these limitations by deriving the first RDP guarantees for heavy-tailed SDEs, as well as their discretized counterparts. Our framework is based on new Rényi flow computations and the use of well-established fractional Poincaré inequalities. Under the assumption that such inequalities are satisfied, we obtain DP guarantees that have a much weaker dependence on the dimension compared to prior art.
Differential Privacy of Noisy GD under Heavy-Tailed Perturbations
Mar 04, 2024Injecting heavy-tailed noise to the iterates of stochastic gradient descent (SGD) has received increasing attention over the past few years. While various theoretical properties of the resulting algorithm have been analyzed mainly from learning theory and optimization perspectives, their privacy preservation properties have not yet been established. Aiming to bridge this gap, we provide differential privacy (DP) guarantees for noisy SGD, when the injected noise follows an $\alpha$-stable distribution, which includes a spectrum of heavy-tailed distributions (with infinite variance) as well as the Gaussian distribution. Considering the $(\epsilon, \delta)$-DP framework, we show that SGD with heavy-tailed perturbations achieves $(0, \tilde{\mathcal{O}}(1/n))$-DP for a broad class of loss functions which can be non-convex, where $n$ is the number of data points. As a remarkable byproduct, contrary to prior work that necessitates bounded sensitivity for the gradients or clipping the iterates, our theory reveals that under mild assumptions, such a projection step is not actually necessary. We illustrate that the heavy-tailed noising mechanism achieves similar DP guarantees compared to the Gaussian case, which suggests that it can be a viable alternative to its light-tailed counterparts.
Cyclic and Randomized Stepsizes Invoke Heavier Tails in SGD
Feb 10, 2023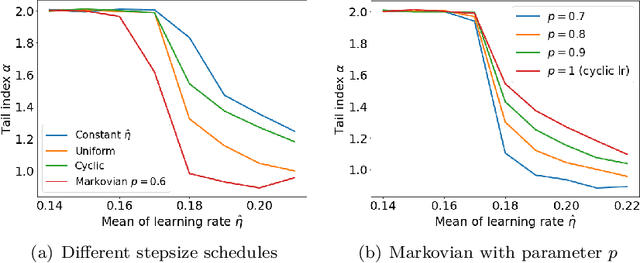
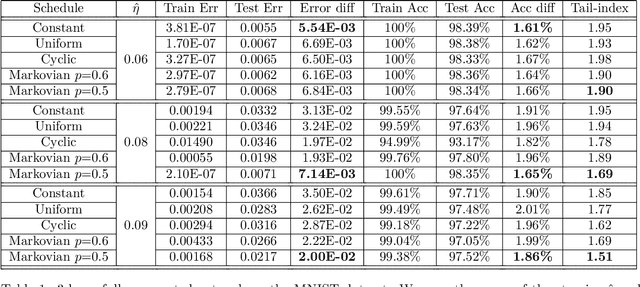
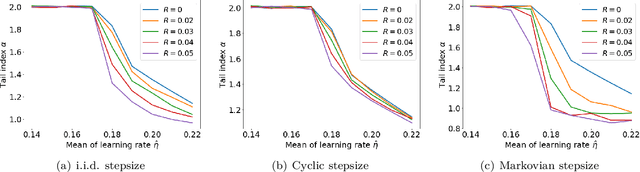
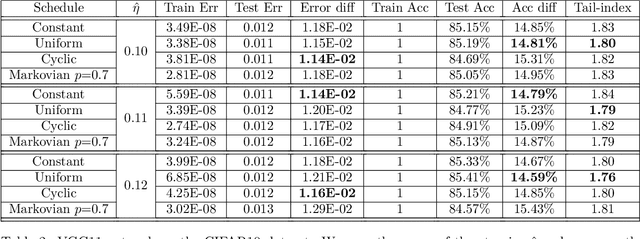
Cyclic and randomized stepsizes are widely used in the deep learning practice and can often outperform standard stepsize choices such as constant stepsize in SGD. Despite their empirical success, not much is currently known about when and why they can theoretically improve the generalization performance. We consider a general class of Markovian stepsizes for learning, which contain i.i.d. random stepsize, cyclic stepsize as well as the constant stepsize as special cases, and motivated by the literature which shows that heaviness of the tails (measured by the so-called "tail-index") in the SGD iterates is correlated with generalization, we study tail-index and provide a number of theoretical results that demonstrate how the tail-index varies on the stepsize scheduling. Our results bring a new understanding of the benefits of cyclic and randomized stepsizes compared to constant stepsize in terms of the tail behavior. We illustrate our theory on linear regression experiments and show through deep learning experiments that Markovian stepsizes can achieve even a heavier tail and be a viable alternative to cyclic and i.i.d. randomized stepsize rules.
Algorithmic Stability of Heavy-Tailed SGD with General Loss Functions
Jan 30, 2023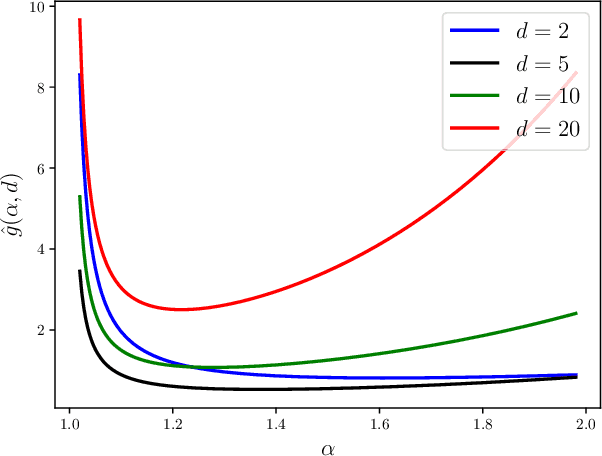
Heavy-tail phenomena in stochastic gradient descent (SGD) have been reported in several empirical studies. Experimental evidence in previous works suggests a strong interplay between the heaviness of the tails and generalization behavior of SGD. To address this empirical phenomena theoretically, several works have made strong topological and statistical assumptions to link the generalization error to heavy tails. Very recently, new generalization bounds have been proven, indicating a non-monotonic relationship between the generalization error and heavy tails, which is more pertinent to the reported empirical observations. While these bounds do not require additional topological assumptions given that SGD can be modeled using a heavy-tailed stochastic differential equation (SDE), they can only apply to simple quadratic problems. In this paper, we build on this line of research and develop generalization bounds for a more general class of objective functions, which includes non-convex functions as well. Our approach is based on developing Wasserstein stability bounds for heavy-tailed SDEs and their discretizations, which we then convert to generalization bounds. Our results do not require any nontrivial assumptions; yet, they shed more light to the empirical observations, thanks to the generality of the loss functions.
Penalized Langevin and Hamiltonian Monte Carlo Algorithms for Constrained Sampling
Nov 29, 2022



We consider the constrained sampling problem where the goal is to sample from a distribution $\pi(x)\propto e^{-f(x)}$ and $x$ is constrained on a convex body $\mathcal{C}\subset \mathbb{R}^d$. Motivated by penalty methods from optimization, we propose penalized Langevin Dynamics (PLD) and penalized Hamiltonian Monte Carlo (PHMC) that convert the constrained sampling problem into an unconstrained one by introducing a penalty function for constraint violations. When $f$ is smooth and the gradient is available, we show $\tilde{\mathcal{O}}(d/\varepsilon^{10})$ iteration complexity for PLD to sample the target up to an $\varepsilon$-error where the error is measured in terms of the total variation distance and $\tilde{\mathcal{O}}(\cdot)$ hides some logarithmic factors. For PHMC, we improve this result to $\tilde{\mathcal{O}}(\sqrt{d}/\varepsilon^{7})$ when the Hessian of $f$ is Lipschitz and the boundary of $\mathcal{C}$ is sufficiently smooth. To our knowledge, these are the first convergence rate results for Hamiltonian Monte Carlo methods in the constrained sampling setting that can handle non-convex $f$ and can provide guarantees with the best dimension dependency among existing methods with deterministic gradients. We then consider the setting where unbiased stochastic gradients are available. We propose PSGLD and PSGHMC that can handle stochastic gradients without Metropolis-Hasting correction steps. When $f$ is strongly convex and smooth, we obtain an iteration complexity of $\tilde{\mathcal{O}}(d/\varepsilon^{18})$ and $\tilde{\mathcal{O}}(d\sqrt{d}/\varepsilon^{39})$ respectively in the 2-Wasserstein distance. For the more general case, when $f$ is smooth and non-convex, we also provide finite-time performance bounds and iteration complexity results. Finally, we test our algorithms on Bayesian LASSO regression and Bayesian constrained deep learning problems.
Algorithmic Stability of Heavy-Tailed Stochastic Gradient Descent on Least Squares
Jun 06, 2022
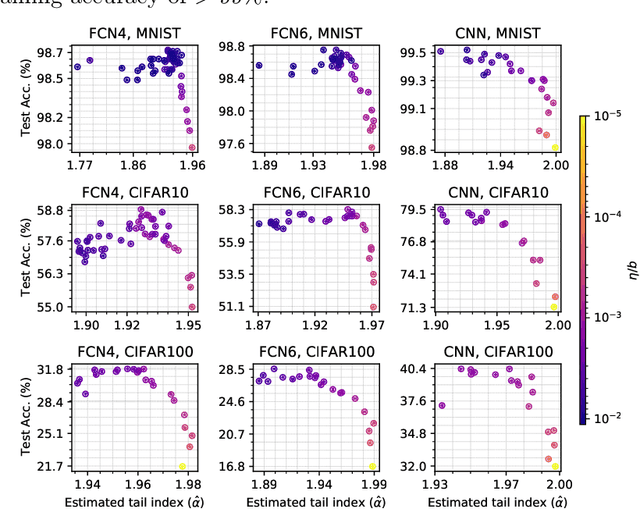

Recent studies have shown that heavy tails can emerge in stochastic optimization and that the heaviness of the tails has links to the generalization error. While these studies have shed light on interesting aspects of the generalization behavior in modern settings, they relied on strong topological and statistical regularity assumptions, which are hard to verify in practice. Furthermore, it has been empirically illustrated that the relation between heavy tails and generalization might not always be monotonic in practice, contrary to the conclusions of existing theory. In this study, we establish novel links between the tail behavior and generalization properties of stochastic gradient descent (SGD), through the lens of algorithmic stability. We consider a quadratic optimization problem and use a heavy-tailed stochastic differential equation as a proxy for modeling the heavy-tailed behavior emerging in SGD. We then prove uniform stability bounds, which reveal the following outcomes: (i) Without making any exotic assumptions, we show that SGD will not be stable if the stability is measured with the squared-loss $x\mapsto x^2$, whereas it in turn becomes stable if the stability is instead measured with a surrogate loss $x\mapsto |x|^p$ with some $p<2$. (ii) Depending on the variance of the data, there exists a \emph{`threshold of heavy-tailedness'} such that the generalization error decreases as the tails become heavier, as long as the tails are lighter than this threshold. This suggests that the relation between heavy tails and generalization is not globally monotonic. (iii) We prove matching lower-bounds on uniform stability, implying that our bounds are tight in terms of the heaviness of the tails. We support our theory with synthetic and real neural network experiments.
Fractal Structure and Generalization Properties of Stochastic Optimization Algorithms
Jun 09, 2021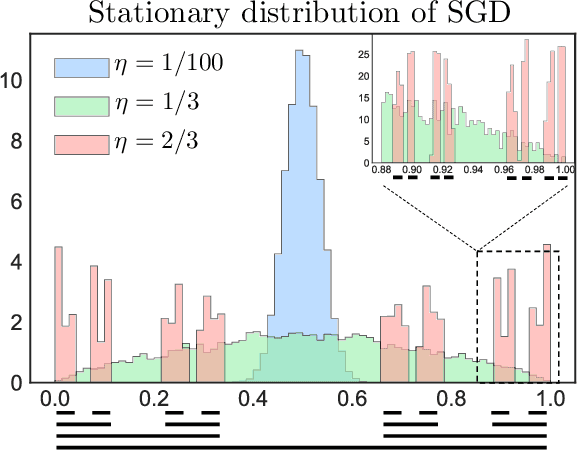
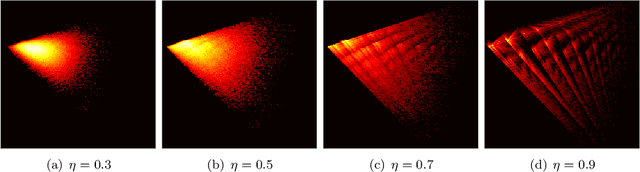
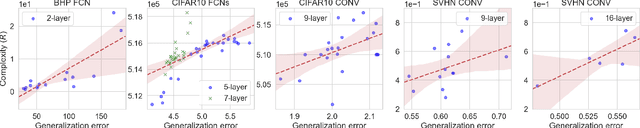
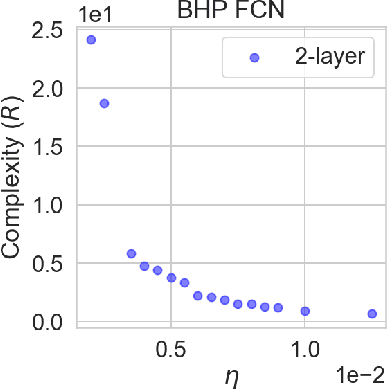
Understanding generalization in deep learning has been one of the major challenges in statistical learning theory over the last decade. While recent work has illustrated that the dataset and the training algorithm must be taken into account in order to obtain meaningful generalization bounds, it is still theoretically not clear which properties of the data and the algorithm determine the generalization performance. In this study, we approach this problem from a dynamical systems theory perspective and represent stochastic optimization algorithms as random iterated function systems (IFS). Well studied in the dynamical systems literature, under mild assumptions, such IFSs can be shown to be ergodic with an invariant measure that is often supported on sets with a fractal structure. As our main contribution, we prove that the generalization error of a stochastic optimization algorithm can be bounded based on the `complexity' of the fractal structure that underlies its invariant measure. Leveraging results from dynamical systems theory, we show that the generalization error can be explicitly linked to the choice of the algorithm (e.g., stochastic gradient descent -- SGD), algorithm hyperparameters (e.g., step-size, batch-size), and the geometry of the problem (e.g., Hessian of the loss). We further specialize our results to specific problems (e.g., linear/logistic regression, one hidden-layered neural networks) and algorithms (e.g., SGD and preconditioned variants), and obtain analytical estimates for our bound.For modern neural networks, we develop an efficient algorithm to compute the developed bound and support our theory with various experiments on neural networks.
TENGraD: Time-Efficient Natural Gradient Descent with Exact Fisher-Block Inversion
Jun 07, 2021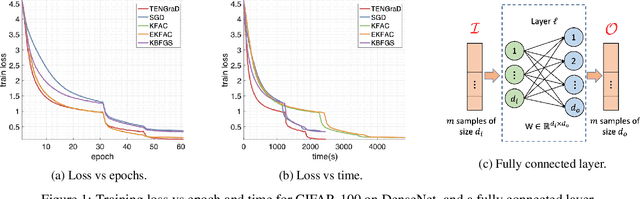

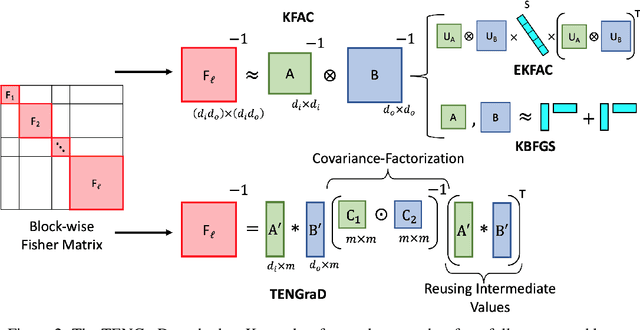
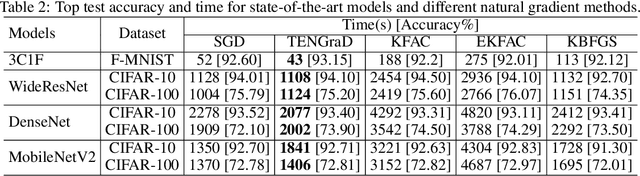
This work proposes a time-efficient Natural Gradient Descent method, called TENGraD, with linear convergence guarantees. Computing the inverse of the neural network's Fisher information matrix is expensive in NGD because the Fisher matrix is large. Approximate NGD methods such as KFAC attempt to improve NGD's running time and practical application by reducing the Fisher matrix inversion cost with approximation. However, the approximations do not reduce the overall time significantly and lead to less accurate parameter updates and loss of curvature information. TENGraD improves the time efficiency of NGD by computing Fisher block inverses with a computationally efficient covariance factorization and reuse method. It computes the inverse of each block exactly using the Woodbury matrix identity to preserve curvature information while admitting (linear) fast convergence rates. Our experiments on image classification tasks for state-of-the-art deep neural architecture on CIFAR-10, CIFAR-100, and Fashion-MNIST show that TENGraD significantly outperforms state-of-the-art NGD methods and often stochastic gradient descent in wall-clock time.
Convergence Rates of Stochastic Gradient Descent under Infinite Noise Variance
Feb 20, 2021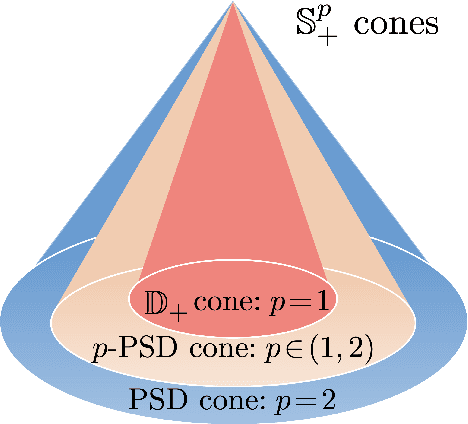
Recent studies have provided both empirical and theoretical evidence illustrating that heavy tails can emerge in stochastic gradient descent (SGD) in various scenarios. Such heavy tails potentially result in iterates with diverging variance, which hinders the use of conventional convergence analysis techniques that rely on the existence of the second-order moments. In this paper, we provide convergence guarantees for SGD under a state-dependent and heavy-tailed noise with a potentially infinite variance, for a class of strongly convex objectives. In the case where the $p$-th moment of the noise exists for some $p\in [1,2)$, we first identify a condition on the Hessian, coined '$p$-positive (semi-)definiteness', that leads to an interesting interpolation between positive semi-definite matrices ($p=2$) and diagonally dominant matrices with non-negative diagonal entries ($p=1$). Under this condition, we then provide a convergence rate for the distance to the global optimum in $L^p$. Furthermore, we provide a generalized central limit theorem, which shows that the properly scaled Polyak-Ruppert averaging converges weakly to a multivariate $\alpha$-stable random vector. Our results indicate that even under heavy-tailed noise with infinite variance, SGD can converge to the global optimum without necessitating any modification neither to the loss function or to the algorithm itself, as typically required in robust statistics. We demonstrate the implications of our results to applications such as linear regression and generalized linear models subject to heavy-tailed data.
Asymmetric Heavy Tails and Implicit Bias in Gaussian Noise Injections
Feb 13, 2021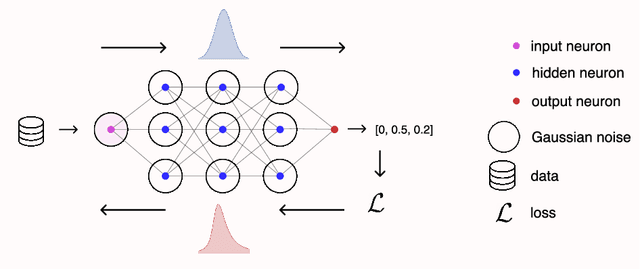
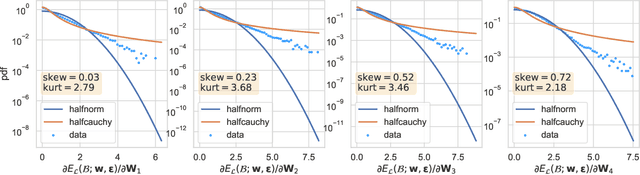
Gaussian noise injections (GNIs) are a family of simple and widely-used regularisation methods for training neural networks, where one injects additive or multiplicative Gaussian noise to the network activations at every iteration of the optimisation algorithm, which is typically chosen as stochastic gradient descent (SGD). In this paper we focus on the so-called `implicit effect' of GNIs, which is the effect of the injected noise on the dynamics of SGD. We show that this effect induces an asymmetric heavy-tailed noise on SGD gradient updates. In order to model this modified dynamics, we first develop a Langevin-like stochastic differential equation that is driven by a general family of asymmetric heavy-tailed noise. Using this model we then formally prove that GNIs induce an `implicit bias', which varies depending on the heaviness of the tails and the level of asymmetry. Our empirical results confirm that different types of neural networks trained with GNIs are well-modelled by the proposed dynamics and that the implicit effect of these injections induces a bias that degrades the performance of networks.