 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTENGraD: Time-Efficient Natural Gradient Descent with Exact Fisher-Block Inversion
Paper and Code
Jun 07, 2021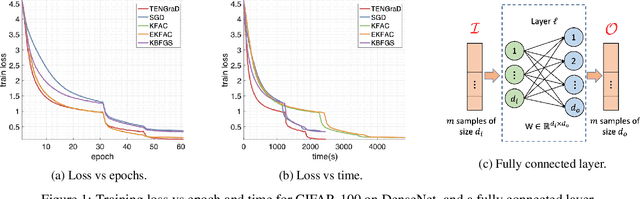

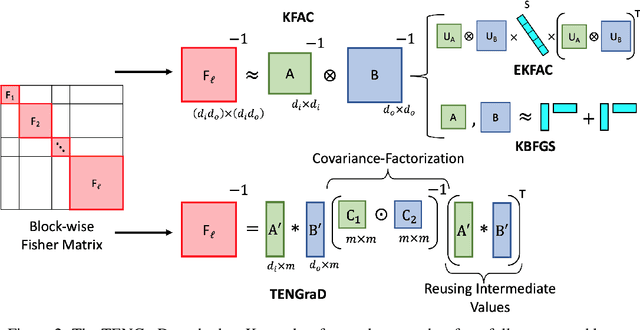
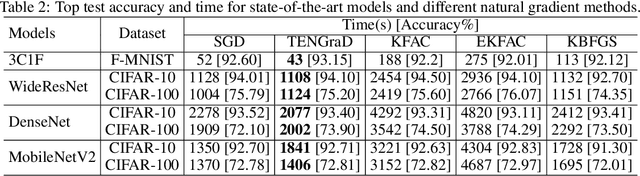
This work proposes a time-efficient Natural Gradient Descent method, called TENGraD, with linear convergence guarantees. Computing the inverse of the neural network's Fisher information matrix is expensive in NGD because the Fisher matrix is large. Approximate NGD methods such as KFAC attempt to improve NGD's running time and practical application by reducing the Fisher matrix inversion cost with approximation. However, the approximations do not reduce the overall time significantly and lead to less accurate parameter updates and loss of curvature information. TENGraD improves the time efficiency of NGD by computing Fisher block inverses with a computationally efficient covariance factorization and reuse method. It computes the inverse of each block exactly using the Woodbury matrix identity to preserve curvature information while admitting (linear) fast convergence rates. Our experiments on image classification tasks for state-of-the-art deep neural architecture on CIFAR-10, CIFAR-100, and Fashion-MNIST show that TENGraD significantly outperforms state-of-the-art NGD methods and often stochastic gradient descent in wall-clock time.