 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Stability of Heavy-Tailed Stochastic Gradient Descent on Least Squares
Paper and Code

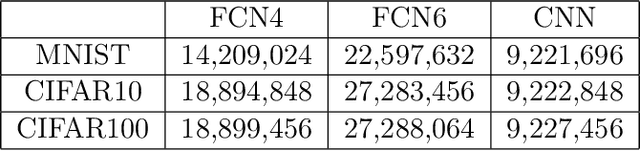
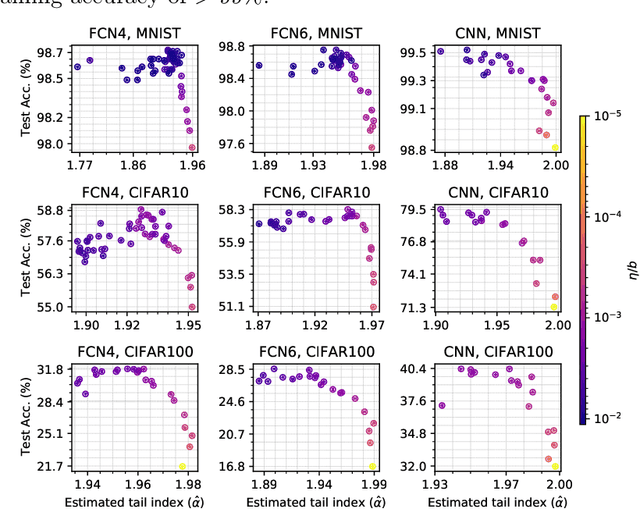

Recent studies have shown that heavy tails can emerge in stochastic optimization and that the heaviness of the tails has links to the generalization error. While these studies have shed light on interesting aspects of the generalization behavior in modern settings, they relied on strong topological and statistical regularity assumptions, which are hard to verify in practice. Furthermore, it has been empirically illustrated that the relation between heavy tails and generalization might not always be monotonic in practice, contrary to the conclusions of existing theory. In this study, we establish novel links between the tail behavior and generalization properties of stochastic gradient descent (SGD), through the lens of algorithmic stability. We consider a quadratic optimization problem and use a heavy-tailed stochastic differential equation as a proxy for modeling the heavy-tailed behavior emerging in SGD. We then prove uniform stability bounds, which reveal the following outcomes: (i) Without making any exotic assumptions, we show that SGD will not be stable if the stability is measured with the squared-loss $x\mapsto x^2$, whereas it in turn becomes stable if the stability is instead measured with a surrogate loss $x\mapsto |x|^p$ with some $p<2$. (ii) Depending on the variance of the data, there exists a \emph{`threshold of heavy-tailedness'} such that the generalization error decreases as the tails become heavier, as long as the tails are lighter than this threshold. This suggests that the relation between heavy tails and generalization is not globally monotonic. (iii) We prove matching lower-bounds on uniform stability, implying that our bounds are tight in terms of the heaviness of the tails. We support our theory with synthetic and real neural network experiments.