 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed-Memory Sparse Kernels for Machine Learning
Paper and Code

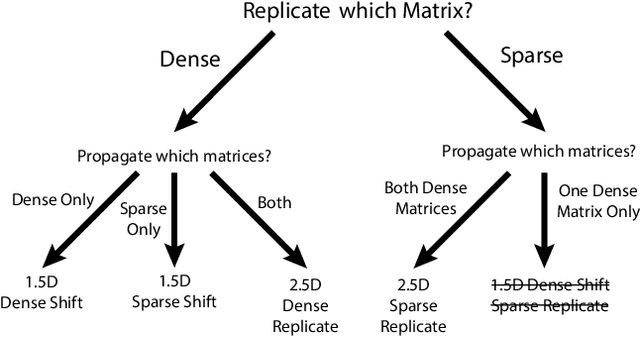

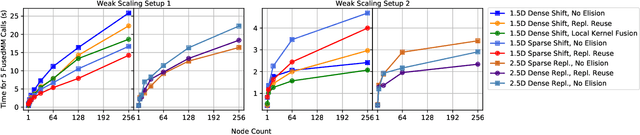
Sampled Dense Times Dense Matrix Multiplication (SDDMM) and Sparse Times Dense Matrix Multiplication (SpMM) appear in diverse settings, such as collaborative filtering, document clustering, and graph embedding. Frequently, the SDDMM output becomes the input sparse matrix for a subsequent SpMM operation. Existing work has focused on shared memory parallelization of these primitives. While there has been extensive analysis of communication-minimizing distributed 1.5D algorithms for SpMM, no such analysis exists for SDDMM or the back-to-back sequence of SDDMM and SpMM, termed FusedMM. We show that distributed memory 1.5D and 2.5D algorithms for SpMM can be converted to algorithms for SDDMM with identical communication costs and input / output data layouts. Further, we give two communication-eliding strategies to reduce costs further for FusedMM kernels: either reusing the replication of an input dense matrix for the SDDMM and SpMM in sequence, or fusing the local SDDMM and SpMM kernels. We benchmark FusedMM algorithms on Cori, a Cray XC40 at LBNL, using Erdos-Renyi random matrices and large real-world sparse matrices. On 256 nodes with 68 cores each, 1.5D FusedMM algorithms using either communication eliding approach can save at least 30% of time spent exclusively in communication compared to executing a distributed-memory SpMM and SDDMM kernel in sequence. On real-world matrices with hundreds of millions of edges, all of our algorithms exhibit at least a 10x speedup over the SpMM algorithm in PETSc. On these matrices, our communication-eliding techniques exhibit runtimes up to 1.6 times faster than an unoptimized sequence of SDDMM and SpMM. We embed and test the scaling of our algorithms in real-world applications, including collaborative filtering via alternating-least-squares and inference for attention-based graph neural networks.