 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing BERT Pre-Training Time from 3 Days to 76 Minutes
Apr 01, 2019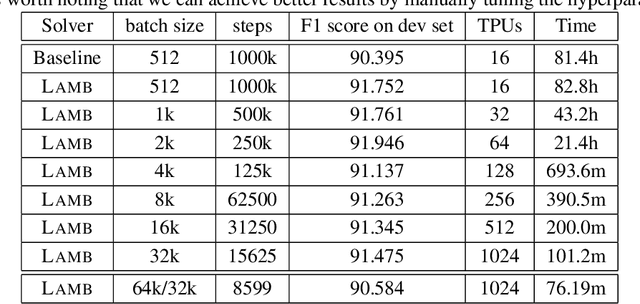

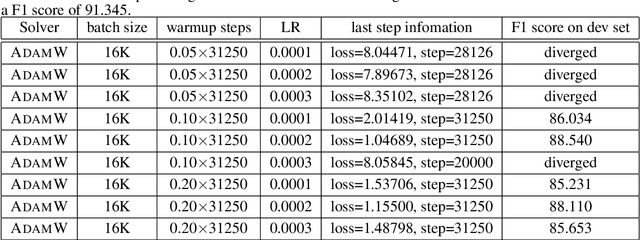

Large-batch training is key to speeding up deep neural network training in large distributed systems. However, large-batch training is difficult because it produces a generalization gap. Straightforward optimization often leads to accuracy loss on the test set. BERT \cite{devlin2018bert} is a state-of-the-art deep learning model that builds on top of deep bidirectional transformers for language understanding. Previous large-batch training techniques do not perform well for BERT when we scale the batch size (e.g. beyond 8192). BERT pre-training also takes a long time to finish (around three days on 16 TPUv3 chips). To solve this problem, we propose the LAMB optimizer, which helps us to scale the batch size to 65536 without losing accuracy. LAMB is a general optimizer that works for both small and large batch sizes and does not need hyper-parameter tuning besides the learning rate. The baseline BERT-Large model needs 1 million iterations to finish pre-training, while LAMB with batch size 65536/32768 only needs 8599 iterations. We push the batch size to the memory limit of a TPUv3 pod and can finish BERT training in 76 minutes.
Large-Batch Training for LSTM and Beyond
Jan 24, 2019

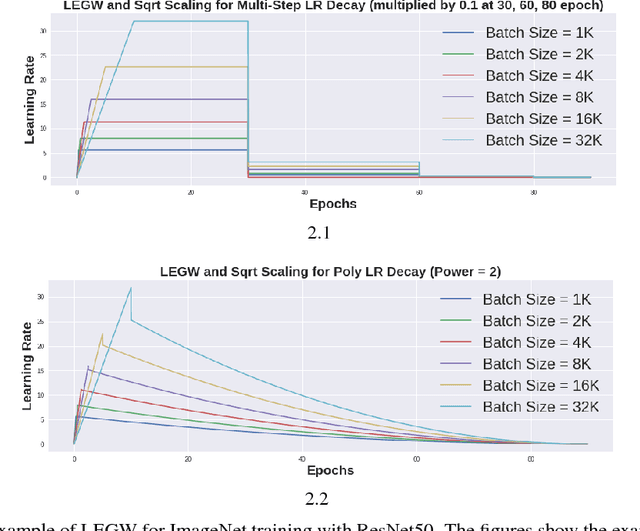
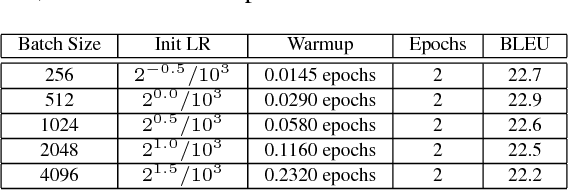
Large-batch training approaches have enabled researchers to utilize large-scale distributed processing and greatly accelerate deep-neural net (DNN) training. For example, by scaling the batch size from 256 to 32K, researchers have been able to reduce the training time of ResNet50 on ImageNet from 29 hours to 2.2 minutes (Ying et al., 2018). In this paper, we propose a new approach called linear-epoch gradual-warmup (LEGW) for better large-batch training. With LEGW, we are able to conduct large-batch training for both CNNs and RNNs with the Sqrt Scaling scheme. LEGW enables Sqrt Scaling scheme to be useful in practice and as a result we achieve much better results than the Linear Scaling learning rate scheme. For LSTM applications, we are able to scale the batch size by a factor of 64 without losing accuracy and without tuning the hyper-parameters. For CNN applications, LEGW is able to achieve the same accuracy even as we scale the batch size to 32K. LEGW works better than previous large-batch auto-tuning techniques. LEGW achieves a 5.3X average speedup over the baselines for four LSTM-based applications on the same hardware. We also provide some theoretical explanations for LEGW.