 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAS-Bench-101: Towards Reproducible Neural Architecture Search
Feb 25, 2019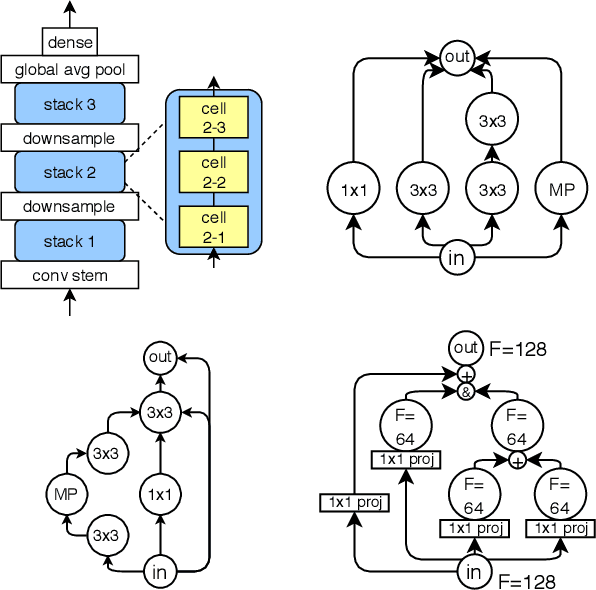
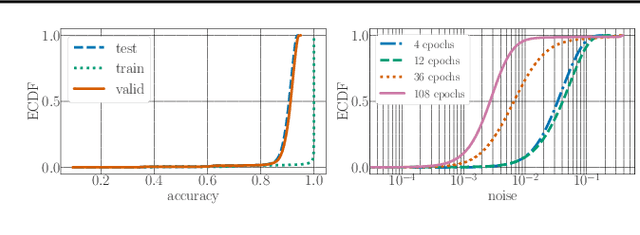
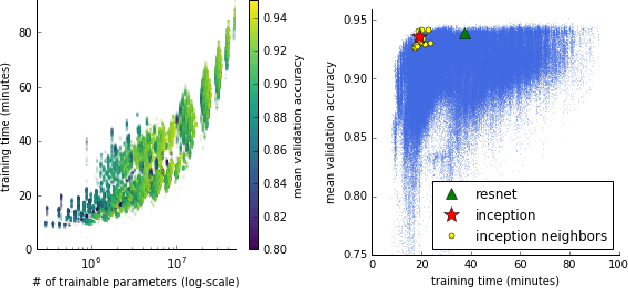
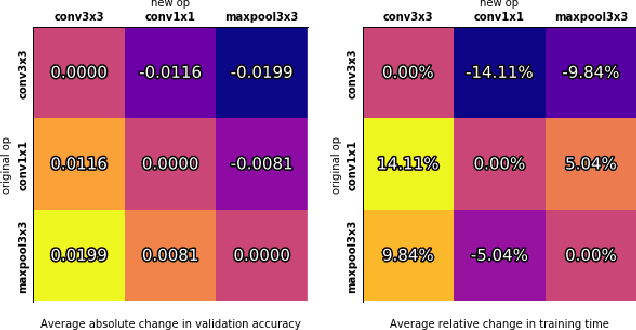
Recent advances in neural architecture search (NAS) demand tremendous computational resources. This makes it difficult to reproduce experiments and imposes a barrier-to-entry to researchers without access to large-scale computation. We aim to ameliorate these problems by introducing NAS-Bench-101, the first public architecture dataset for NAS research. To build NAS-Bench-101, we carefully constructed a compact, yet expressive, search space, exploiting graph isomorphisms to identify 423k unique convolutional architectures. We trained and evaluated all of these architectures multiple times on CIFAR-10 and compiled the results into a large dataset. All together, NAS-Bench-101 contains the metrics of over 5 million models, the largest dataset of its kind thus far. This allows researchers to evaluate the quality of a diverse range of models in milliseconds by querying the pre-computed dataset. We demonstrate its utility by analyzing the dataset as a whole and by benchmarking a range of architecture optimization algorithms.
Large-Batch Training for LSTM and Beyond
Jan 24, 2019

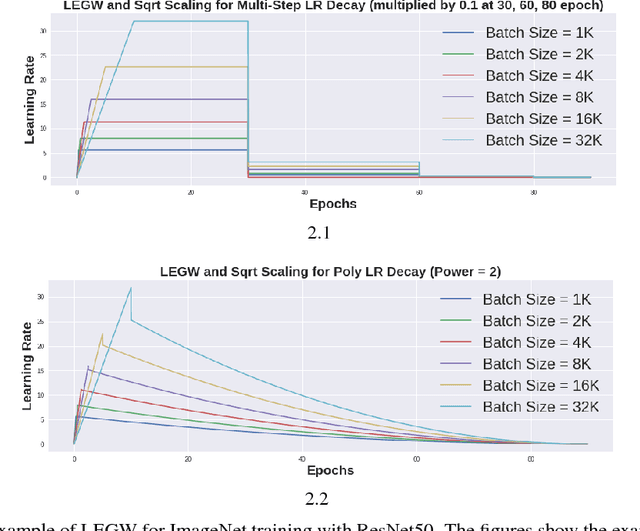
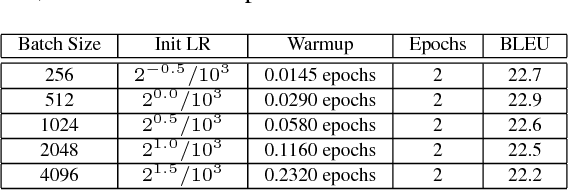
Large-batch training approaches have enabled researchers to utilize large-scale distributed processing and greatly accelerate deep-neural net (DNN) training. For example, by scaling the batch size from 256 to 32K, researchers have been able to reduce the training time of ResNet50 on ImageNet from 29 hours to 2.2 minutes (Ying et al., 2018). In this paper, we propose a new approach called linear-epoch gradual-warmup (LEGW) for better large-batch training. With LEGW, we are able to conduct large-batch training for both CNNs and RNNs with the Sqrt Scaling scheme. LEGW enables Sqrt Scaling scheme to be useful in practice and as a result we achieve much better results than the Linear Scaling learning rate scheme. For LSTM applications, we are able to scale the batch size by a factor of 64 without losing accuracy and without tuning the hyper-parameters. For CNN applications, LEGW is able to achieve the same accuracy even as we scale the batch size to 32K. LEGW works better than previous large-batch auto-tuning techniques. LEGW achieves a 5.3X average speedup over the baselines for four LSTM-based applications on the same hardware. We also provide some theoretical explanations for LEGW.
Image Classification at Supercomputer Scale
Dec 02, 2018
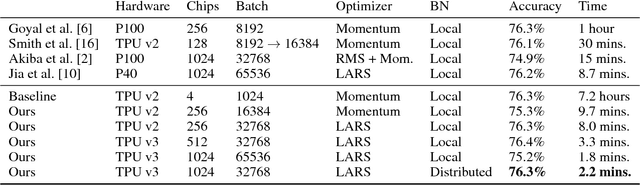

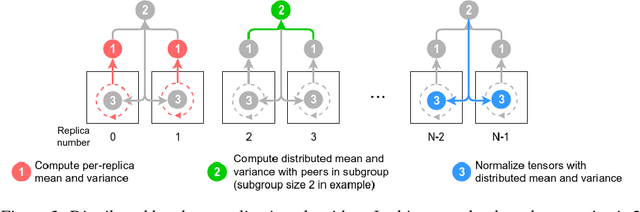
Deep learning is extremely computationally intensive, and hardware vendors have responded by building faster accelerators in large clusters. Training deep learning models at petaFLOPS scale requires overcoming both algorithmic and systems software challenges. In this paper, we discuss three systems-related optimizations: (1) distributed batch normalization to control per-replica batch sizes, (2) input pipeline optimizations to sustain model throughput, and (3) 2-D torus all-reduce to speed up gradient summation. We combine these optimizations to train ResNet-50 on ImageNet to 76.3% accuracy in 2.2 minutes on a 1024-chip TPU v3 Pod with a training throughput of over 1.05 million images/second and no accuracy drop.
Don't Decay the Learning Rate, Increase the Batch Size
Feb 24, 2018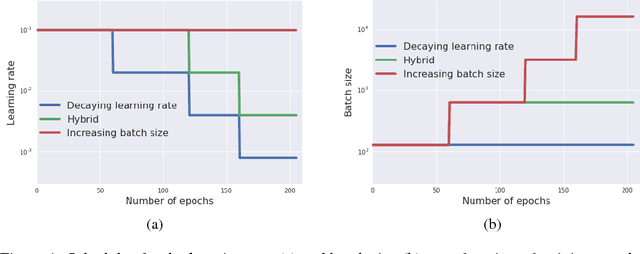

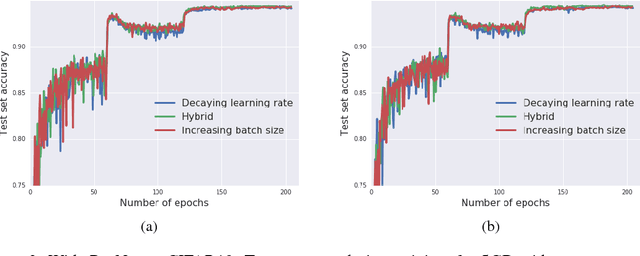
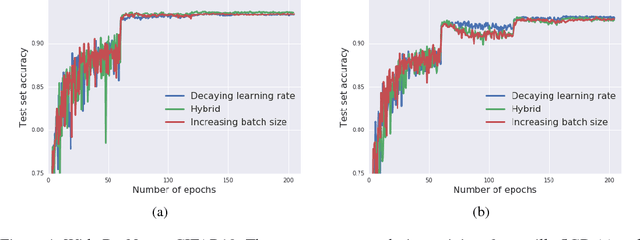
It is common practice to decay the learning rate. Here we show one can usually obtain the same learning curve on both training and test sets by instead increasing the batch size during training. This procedure is successful for stochastic gradient descent (SGD), SGD with momentum, Nesterov momentum, and Adam. It reaches equivalent test accuracies after the same number of training epochs, but with fewer parameter updates, leading to greater parallelism and shorter training times. We can further reduce the number of parameter updates by increasing the learning rate $\epsilon$ and scaling the batch size $B \propto \epsilon$. Finally, one can increase the momentum coefficient $m$ and scale $B \propto 1/(1-m)$, although this tends to slightly reduce the test accuracy. Crucially, our techniques allow us to repurpose existing training schedules for large batch training with no hyper-parameter tuning. We train ResNet-50 on ImageNet to $76.1\%$ validation accuracy in under 30 minutes.
Depth-Adaptive Computational Policies for Efficient Visual Tracking
Jan 01, 2018


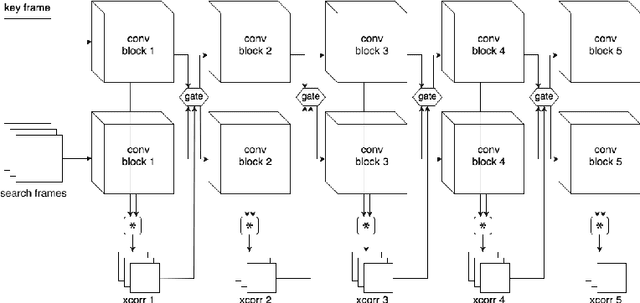
Current convolutional neural networks algorithms for video object tracking spend the same amount of computation for each object and video frame. However, it is harder to track an object in some frames than others, due to the varying amount of clutter, scene complexity, amount of motion, and object's distinctiveness against its background. We propose a depth-adaptive convolutional Siamese network that performs video tracking adaptively at multiple neural network depths. Parametric gating functions are trained to control the depth of the convolutional feature extractor by minimizing a joint loss of computational cost and tracking error. Our network achieves accuracy comparable to the state-of-the-art on the VOT2016 benchmark. Furthermore, our adaptive depth computation achieves higher accuracy for a given computational cost than traditional fixed-structure neural networks. The presented framework extends to other tasks that use convolutional neural networks and enables trading speed for accuracy at runtime.