 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Are You Doing? A Closer Look at Controllable Human Video Generation
Mar 06, 2025
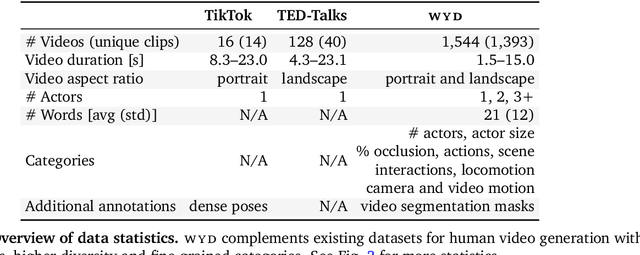
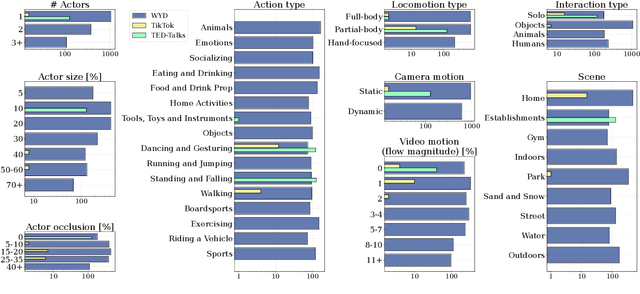
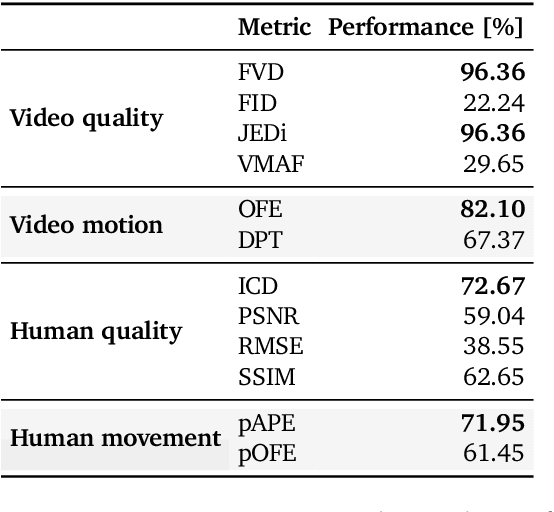
High-quality benchmarks are crucial for driving progress in machine learning research. However, despite the growing interest in video generation, there is no comprehensive dataset to evaluate human generation. Humans can perform a wide variety of actions and interactions, but existing datasets, like TikTok and TED-Talks, lack the diversity and complexity to fully capture the capabilities of video generation models. We close this gap by introducing `What Are You Doing?' (WYD): a new benchmark for fine-grained evaluation of controllable image-to-video generation of humans. WYD consists of 1{,}544 captioned videos that have been meticulously collected and annotated with 56 fine-grained categories. These allow us to systematically measure performance across 9 aspects of human generation, including actions, interactions and motion. We also propose and validate automatic metrics that leverage our annotations and better capture human evaluations. Equipped with our dataset and metrics, we perform in-depth analyses of seven state-of-the-art models in controllable image-to-video generation, showing how WYD provides novel insights about the capabilities of these models. We release our data and code to drive forward progress in human video generation modeling at https://github.com/google-deepmind/wyd-benchmark.
StoryBench: A Multifaceted Benchmark for Continuous Story Visualization
Aug 22, 2023



Generating video stories from text prompts is a complex task. In addition to having high visual quality, videos need to realistically adhere to a sequence of text prompts whilst being consistent throughout the frames. Creating a benchmark for video generation requires data annotated over time, which contrasts with the single caption used often in video datasets. To fill this gap, we collect comprehensive human annotations on three existing datasets, and introduce StoryBench: a new, challenging multi-task benchmark to reliably evaluate forthcoming text-to-video models. Our benchmark includes three video generation tasks of increasing difficulty: action execution, where the next action must be generated starting from a conditioning video; story continuation, where a sequence of actions must be executed starting from a conditioning video; and story generation, where a video must be generated from only text prompts. We evaluate small yet strong text-to-video baselines, and show the benefits of training on story-like data algorithmically generated from existing video captions. Finally, we establish guidelines for human evaluation of video stories, and reaffirm the need of better automatic metrics for video generation. StoryBench aims at encouraging future research efforts in this exciting new area.
Phenaki: Variable Length Video Generation From Open Domain Textual Description
Oct 05, 2022
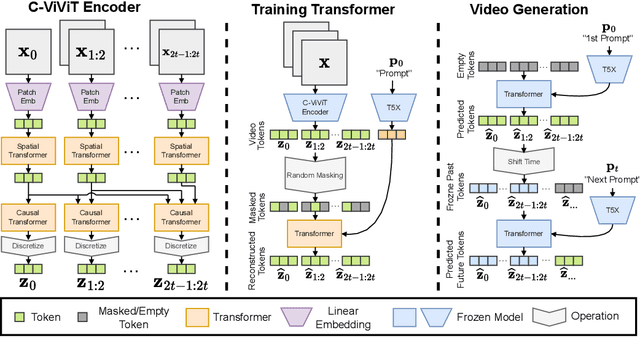


We present Phenaki, a model capable of realistic video synthesis, given a sequence of textual prompts. Generating videos from text is particularly challenging due to the computational cost, limited quantities of high quality text-video data and variable length of videos. To address these issues, we introduce a new model for learning video representation which compresses the video to a small representation of discrete tokens. This tokenizer uses causal attention in time, which allows it to work with variable-length videos. To generate video tokens from text we are using a bidirectional masked transformer conditioned on pre-computed text tokens. The generated video tokens are subsequently de-tokenized to create the actual video. To address data issues, we demonstrate how joint training on a large corpus of image-text pairs as well as a smaller number of video-text examples can result in generalization beyond what is available in the video datasets. Compared to the previous video generation methods, Phenaki can generate arbitrary long videos conditioned on a sequence of prompts (i.e. time variable text or a story) in open domain. To the best of our knowledge, this is the first time a paper studies generating videos from time variable prompts. In addition, compared to the per-frame baselines, the proposed video encoder-decoder computes fewer tokens per video but results in better spatio-temporal consistency.
When adversarial examples are excusable
Apr 25, 2022


Neural networks work remarkably well in practice and theoretically they can be universal approximators. However, they still make mistakes and a specific type of them called adversarial errors seem inexcusable to humans. In this work, we analyze both test errors and adversarial errors on a well controlled but highly non-linear visual classification problem. We find that, when approximating training on infinite data, test errors tend to be close to the ground truth decision boundary. Qualitatively speaking these are also more difficult for a human. By contrast, adversarial examples can be found almost everywhere and are often obvious mistakes. However, when we constrain adversarial examples to the manifold, we observe a 90\% reduction in adversarial errors. If we inflate the manifold by training with Gaussian noise we observe a similar effect. In both cases, the remaining adversarial errors tend to be close to the ground truth decision boundary. Qualitatively, the remaining adversarial errors are similar to test errors on difficult examples. They do not have the customary quality of being inexcusable mistakes.
Resource-Constrained Neural Architecture Search on Tabular Datasets
Apr 15, 2022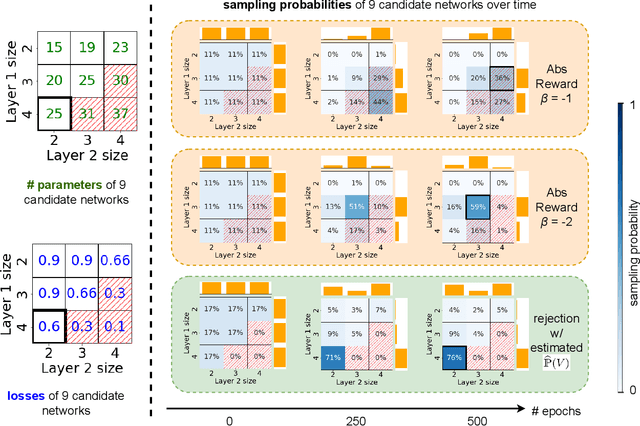
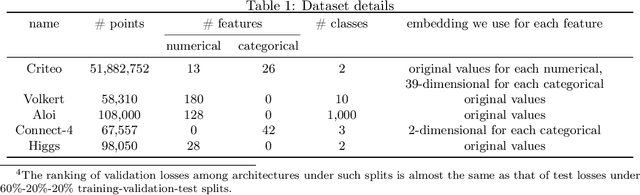
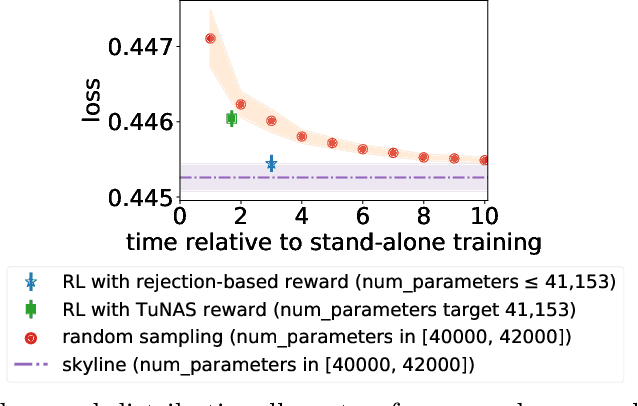
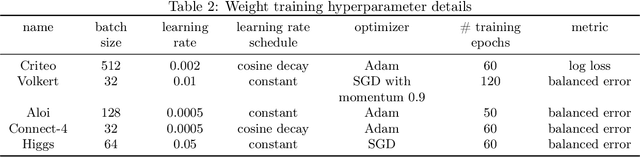
The best neural architecture for a given machine learning problem depends on many factors: not only the complexity and structure of the dataset, but also on resource constraints including latency, compute, energy consumption, etc. Neural architecture search (NAS) for tabular datasets is an important but under-explored problem. Previous NAS algorithms designed for image search spaces incorporate resource constraints directly into the reinforcement learning rewards. In this paper, we argue that search spaces for tabular NAS pose considerable challenges for these existing reward-shaping methods, and propose a new reinforcement learning (RL) controller to address these challenges. Motivated by rejection sampling, when we sample candidate architectures during a search, we immediately discard any architecture that violates our resource constraints. We use a Monte-Carlo-based correction to our RL policy gradient update to account for this extra filtering step. Results on several tabular datasets show TabNAS, the proposed approach, efficiently finds high-quality models that satisfy the given resource constraints.
Discovering Multi-Hardware Mobile Models via Architecture Search
Aug 18, 2020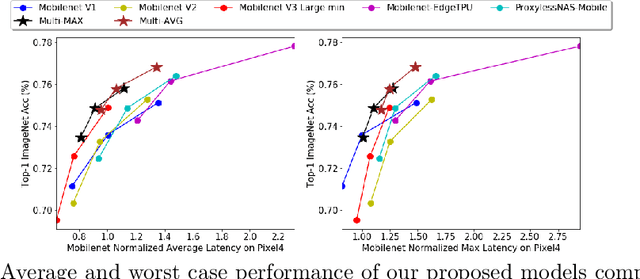

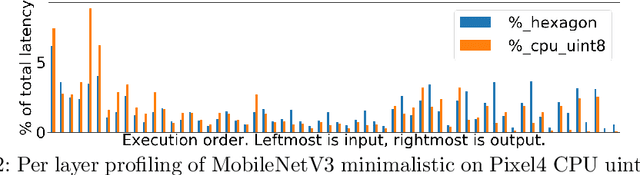
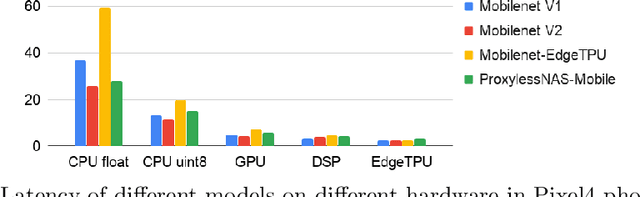
Developing efficient models for mobile phones or other on-device deployments has been a popular topic in both industry and academia. In such scenarios, it is often convenient to deploy the same model on a diverse set of hardware devices owned by different end users to minimize the costs of development, deployment and maintenance. Despite the importance, designing a single neural network that can perform well on multiple devices is difficult as each device has its own specialty and restrictions: A model optimized for one device may not perform well on another. While most existing work proposes different models optimized for each single hardware, this paper is the first which explores the problem of finding a single model that performs well on multiple hardware. Specifically, we leverage architecture search to help us find the best model, where given a set of diverse hardware to optimize for, we first introduce a multi-hardware search space that is compatible with all examined hardware. Then, to measure the performance of a neural network over multiple hardware, we propose metrics that can characterize the overall latency performance in an average case and worst case scenario. With the multi-hardware search space and new metrics applied to Pixel4 CPU, GPU, DSP and EdgeTPU, we found models that perform on par or better than state-of-the-art (SOTA) models on each of our target accelerators and generalize well on many un-targeted hardware. Comparing with single-hardware searches, multi-hardware search gives a better trade-off between computation cost and model performance.
Can weight sharing outperform random architecture search? An investigation with TuNAS
Aug 13, 2020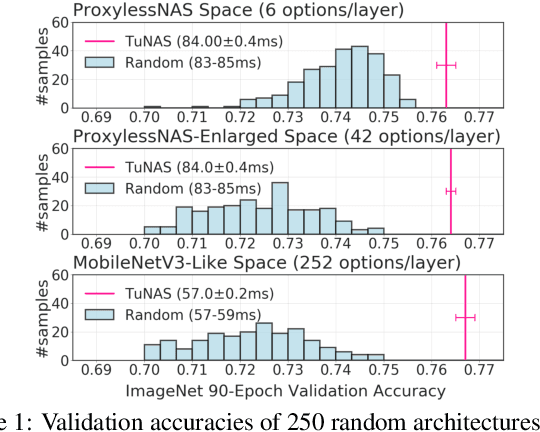


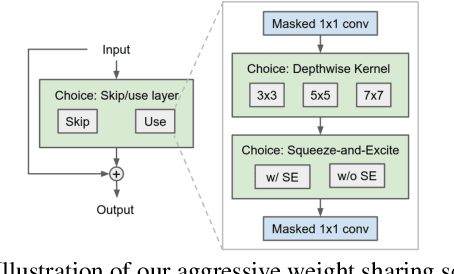
Efficient Neural Architecture Search methods based on weight sharing have shown good promise in democratizing Neural Architecture Search for computer vision models. There is, however, an ongoing debate whether these efficient methods are significantly better than random search. Here we perform a thorough comparison between efficient and random search methods on a family of progressively larger and more challenging search spaces for image classification and detection on ImageNet and COCO. While the efficacies of both methods are problem-dependent, our experiments demonstrate that there are large, realistic tasks where efficient search methods can provide substantial gains over random search. In addition, we propose and evaluate techniques which improve the quality of searched architectures and reduce the need for manual hyper-parameter tuning. Source code and experiment data are available at https://github.com/google-research/google-research/tree/master/tunas
* Published at CVPR 2020
MobileDets: Searching for Object Detection Architectures for Mobile Accelerators
Apr 30, 2020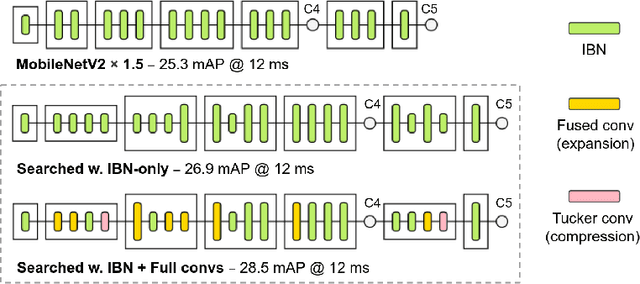
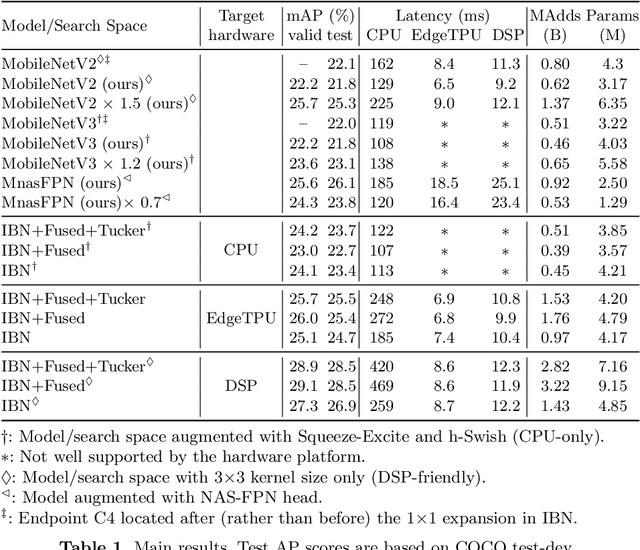
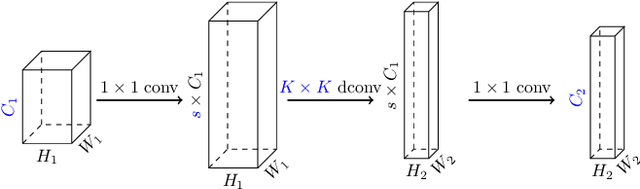
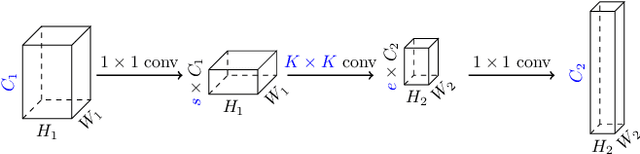
Inverted bottleneck layers, which are built upon depthwise convolutions, have been the predominant building blocks in state-of-the-art object detection models on mobile devices. In this work, we question the optimality of this design pattern over a broad range of mobile accelerators by revisiting the usefulness of regular convolutions. We achieve substantial improvements in the latency-accuracy trade-off by incorporating regular convolutions in the search space, and effectively placing them in the network via neural architecture search. We obtain a family of object detection models, MobileDets, that achieve state-of-the-art results across mobile accelerators. On the COCO object detection task, MobileDets outperform MobileNetV3+SSDLite by 1.7 mAP at comparable mobile CPU inference latencies. MobileDets also outperform MobileNetV2+SSDLite by 1.9 mAP on mobile CPUs, 3.7 mAP on EdgeTPUs and 3.4 mAP on DSPs while running equally fast. Moreover, MobileDets are comparable with the state-of-the-art MnasFPN on mobile CPUs even without using the feature pyramid, and achieve better mAP scores on both EdgeTPUs and DSPs with up to 2X speedup.
BigNAS: Scaling Up Neural Architecture Search with Big Single-Stage Models
Mar 24, 2020
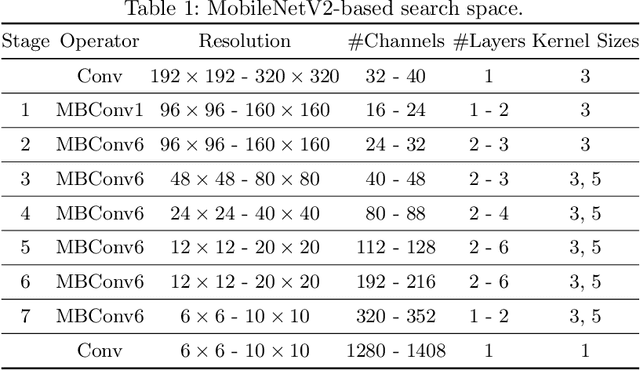
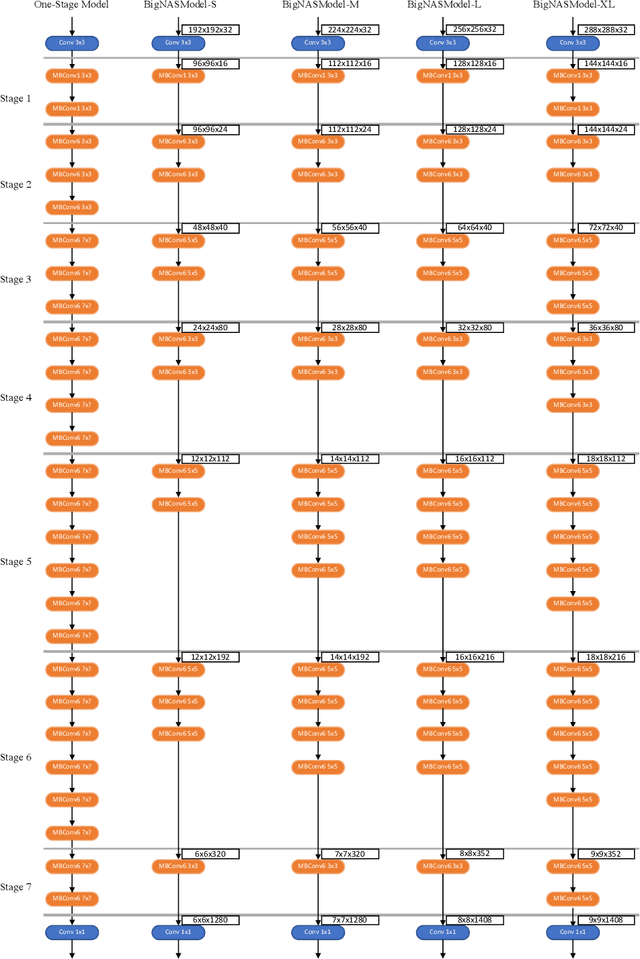
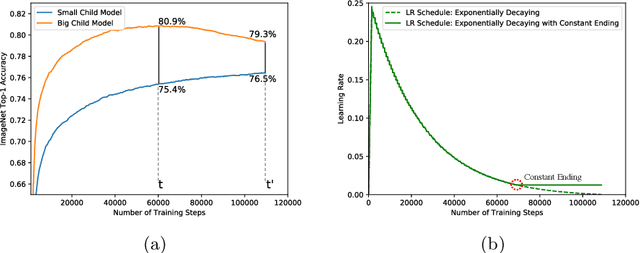
Neural architecture search (NAS) has shown promising results discovering models that are both accurate and fast. For NAS, training a one-shot model has become a popular strategy to rank the relative quality of different architectures (child models) using a single set of shared weights. However, while one-shot model weights can effectively rank different network architectures, the absolute accuracies from these shared weights are typically far below those obtained from stand-alone training. To compensate, existing methods assume that the weights must be retrained, finetuned, or otherwise post-processed after the search is completed. These steps significantly increase the compute requirements and complexity of the architecture search and model deployment. In this work, we propose BigNAS, an approach that challenges the conventional wisdom that post-processing of the weights is necessary to get good prediction accuracies. Without extra retraining or post-processing steps, we are able to train a single set of shared weights on ImageNet and use these weights to obtain child models whose sizes range from 200 to 1000 MFLOPs. Our discovered model family, BigNASModels, achieve top-1 accuracies ranging from 76.5% to 80.9%, surpassing state-of-the-art models in this range including EfficientNets and Once-for-All networks without extra retraining or post-processing. We present ablative study and analysis to further understand the proposed BigNASModels.
Neural Predictor for Neural Architecture Search
Dec 02, 2019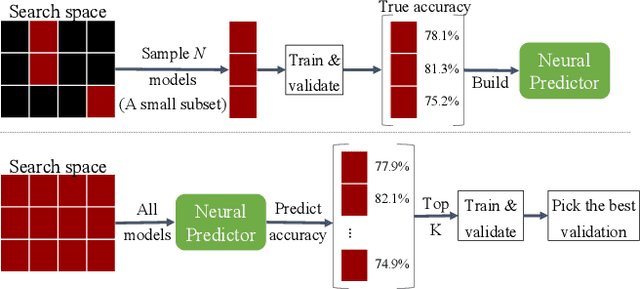
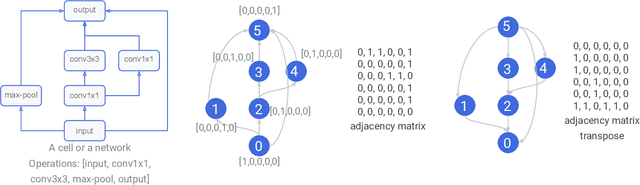
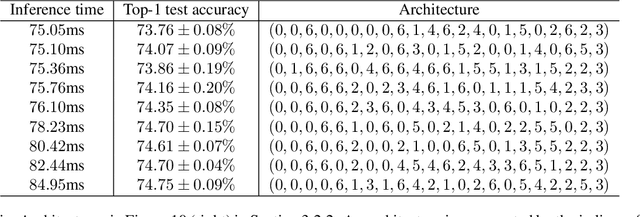
Neural Architecture Search methods are effective but often use complex algorithms to come up with the best architecture. We propose an approach with three basic steps that is conceptually much simpler. First we train N random architectures to generate N (architecture, validation accuracy) pairs and use them to train a regression model that predicts accuracy based on the architecture. Next, we use this regression model to predict the validation accuracies of a large number of random architectures. Finally, we train the top-K predicted architectures and deploy the model with the best validation result. While this approach seems simple, it is more than 20 times as sample efficient as Regularized Evolution on the NASBench-101 benchmark and can compete on ImageNet with more complex approaches based on weight sharing, such as ProxylessNAS.