 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
COMISR: Compression-Informed Video Super-Resolution
May 04, 2021

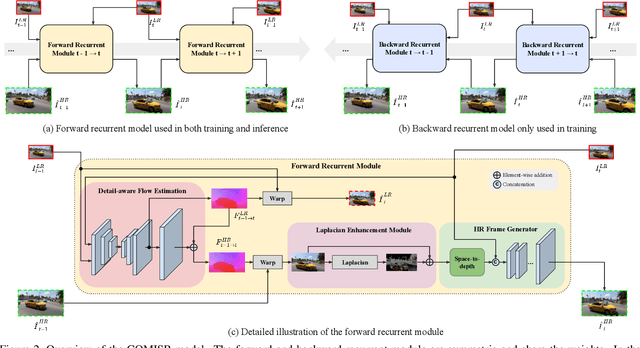
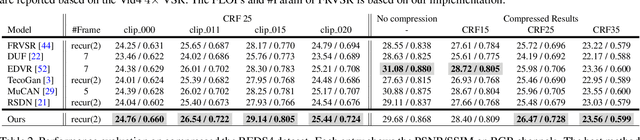
Most video super-resolution methods focus on restoring high-resolution video frames from low-resolution videos without taking into account compression. However, most videos on the web or mobile devices are compressed, and the compression can be severe when the bandwidth is limited. In this paper, we propose a new compression-informed video super-resolution model to restore high-resolution content without introducing artifacts caused by compression. The proposed model consists of three modules for video super-resolution: bi-directional recurrent warping, detail-preserving flow estimation, and Laplacian enhancement. All these three modules are used to deal with compression properties such as the location of the intra-frames in the input and smoothness in the output frames. For thorough performance evaluation, we conducted extensive experiments on standard datasets with a wide range of compression rates, covering many real video use cases. We showed that our method not only recovers high-resolution content on uncompressed frames from the widely-used benchmark datasets, but also achieves state-of-the-art performance in super-resolving compressed videos based on numerous quantitative metrics. We also evaluated the proposed method by simulating streaming from YouTube to demonstrate its effectiveness and robustness.
Efficient Scale-Permuted Backbone with Learned Resource Distribution
Oct 22, 2020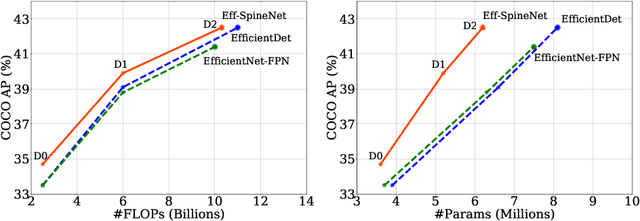
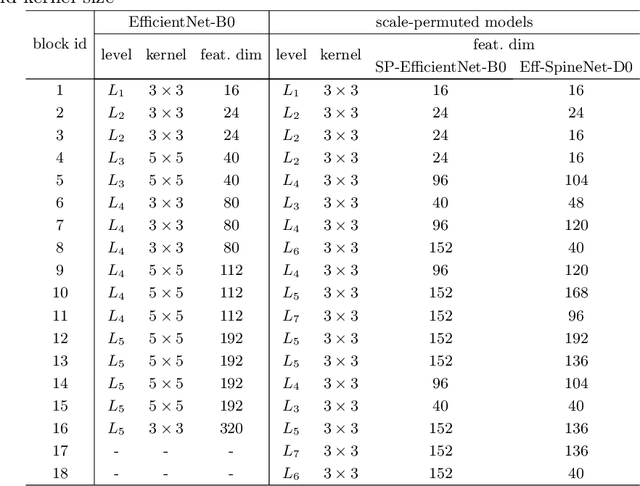
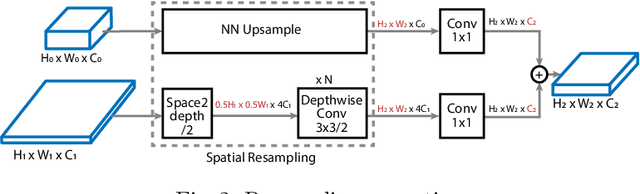

Recently, SpineNet has demonstrated promising results on object detection and image classification over ResNet model. However, it is unclear if the improvement adds up when combining scale-permuted backbone with advanced efficient operations and compound scaling. Furthermore, SpineNet is built with a uniform resource distribution over operations. While this strategy seems to be prevalent for scale-decreased models, it may not be an optimal design for scale-permuted models. In this work, we propose a simple technique to combine efficient operations and compound scaling with a previously learned scale-permuted architecture. We demonstrate the efficiency of scale-permuted model can be further improved by learning a resource distribution over the entire network. The resulting efficient scale-permuted models outperform state-of-the-art EfficientNet-based models on object detection and achieve competitive performance on image classification and semantic segmentation. Code and models will be open-sourced soon.
BigNAS: Scaling Up Neural Architecture Search with Big Single-Stage Models
Mar 24, 2020
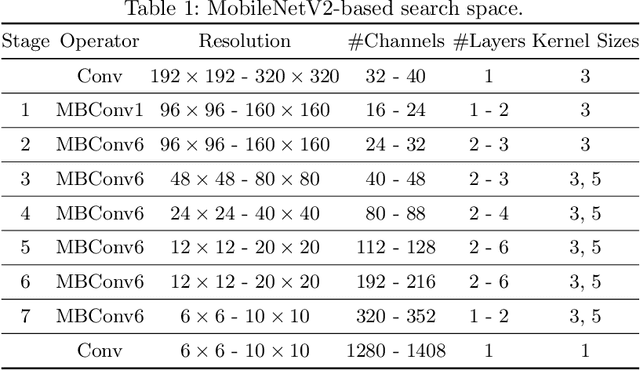
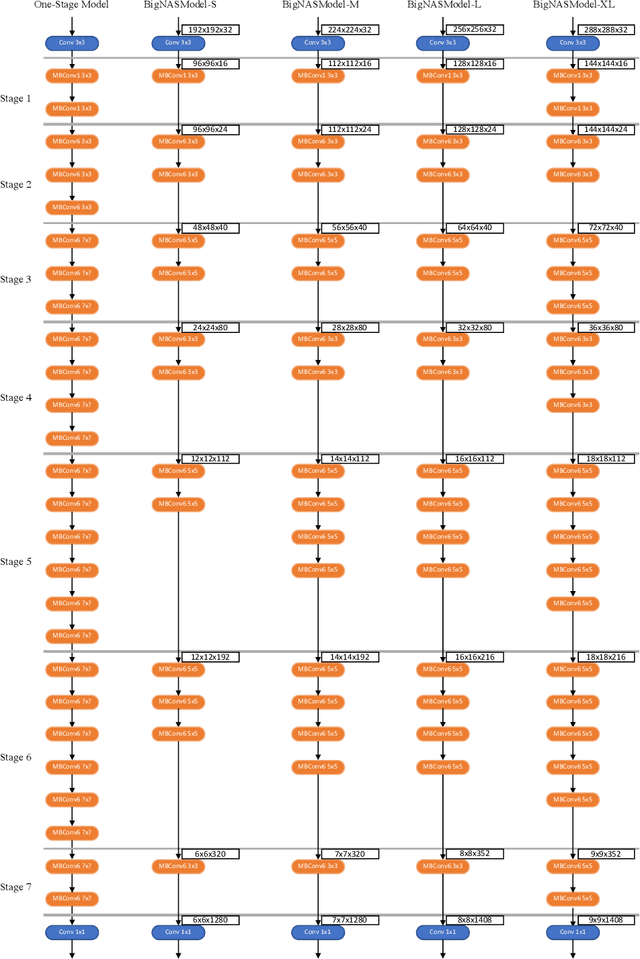
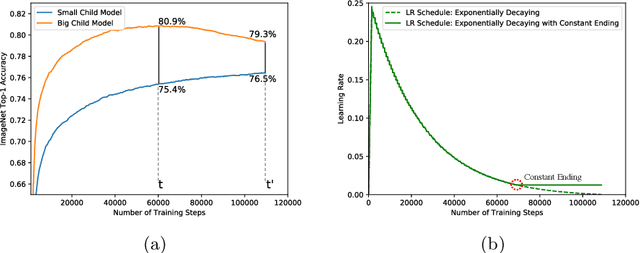
Neural architecture search (NAS) has shown promising results discovering models that are both accurate and fast. For NAS, training a one-shot model has become a popular strategy to rank the relative quality of different architectures (child models) using a single set of shared weights. However, while one-shot model weights can effectively rank different network architectures, the absolute accuracies from these shared weights are typically far below those obtained from stand-alone training. To compensate, existing methods assume that the weights must be retrained, finetuned, or otherwise post-processed after the search is completed. These steps significantly increase the compute requirements and complexity of the architecture search and model deployment. In this work, we propose BigNAS, an approach that challenges the conventional wisdom that post-processing of the weights is necessary to get good prediction accuracies. Without extra retraining or post-processing steps, we are able to train a single set of shared weights on ImageNet and use these weights to obtain child models whose sizes range from 200 to 1000 MFLOPs. Our discovered model family, BigNASModels, achieve top-1 accuracies ranging from 76.5% to 80.9%, surpassing state-of-the-art models in this range including EfficientNets and Once-for-All networks without extra retraining or post-processing. We present ablative study and analysis to further understand the proposed BigNASModels.
SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization
Dec 10, 2019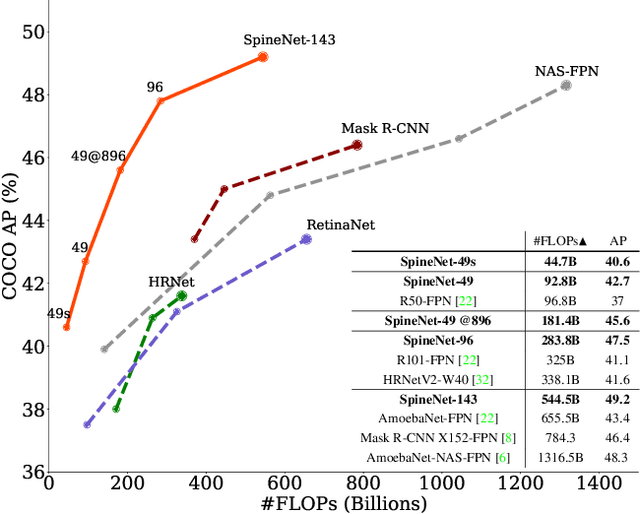
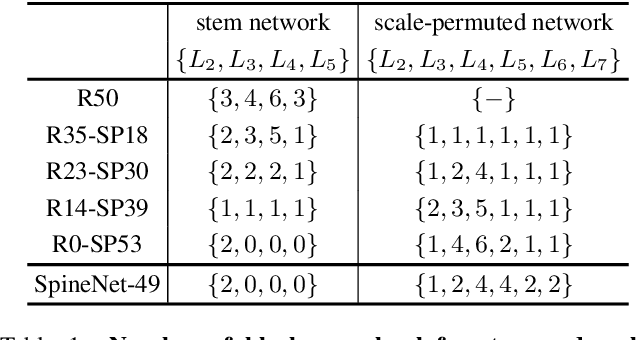
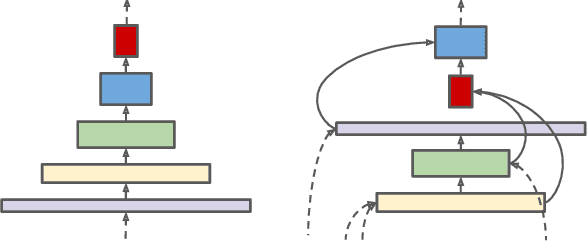
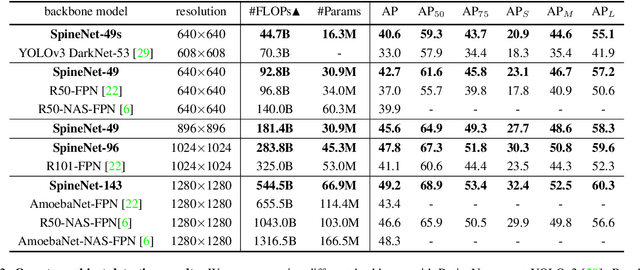
Convolutional neural networks typically encode an input image into a series of intermediate features with decreasing resolutions. While this structure is suited to classification tasks, it does not perform well for tasks requiring simultaneous recognition and localization (e.g., object detection). The encoder-decoder architectures are proposed to resolve this by applying a decoder network onto a backbone model designed for classification tasks. In this paper, we argue that encoder-decoder architecture is ineffective in generating strong multi-scale features because of the scale-decreased backbone. We propose SpineNet, a backbone with scale-permuted intermediate features and cross-scale connections that is learned on an object detection task by Neural Architecture Search. SpineNet achieves state-of-the-art performance of one-stage object detector on COCO with 60% less computation, and outperforms ResNet-FPN counterparts by 6% AP. SpineNet architecture can transfer to classification tasks, achieving 6% top-1 accuracy improvement on a challenging iNaturalist fine-grained dataset.
Pooling Pyramid Network for Object Detection
Jul 09, 2018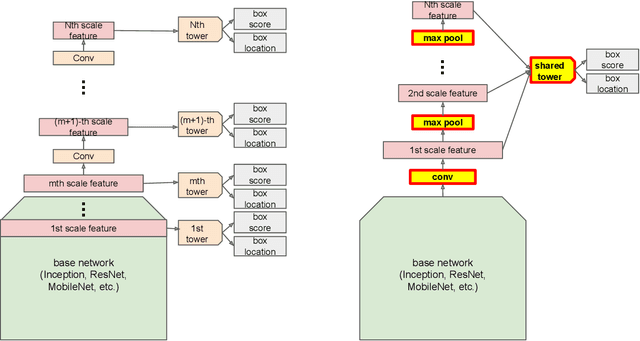

We'd like to share a simple tweak of Single Shot Multibox Detector (SSD) family of detectors, which is effective in reducing model size while maintaining the same quality. We share box predictors across all scales, and replace convolution between scales with max pooling. This has two advantages over vanilla SSD: (1) it avoids score miscalibration across scales; (2) the shared predictor sees the training data over all scales. Since we reduce the number of predictors to one, and trim all convolutions between them, model size is significantly smaller. We empirically show that these changes do not hurt model quality compared to vanilla SSD.