Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePooling Pyramid Network for Object Detection
Paper and Code
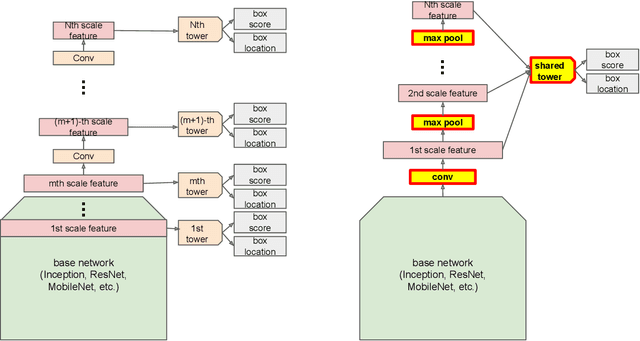

We'd like to share a simple tweak of Single Shot Multibox Detector (SSD) family of detectors, which is effective in reducing model size while maintaining the same quality. We share box predictors across all scales, and replace convolution between scales with max pooling. This has two advantages over vanilla SSD: (1) it avoids score miscalibration across scales; (2) the shared predictor sees the training data over all scales. Since we reduce the number of predictors to one, and trim all convolutions between them, model size is significantly smaller. We empirically show that these changes do not hurt model quality compared to vanilla SSD.
View paper on