 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-UP: A Simple and Efficient Mixture-of-Experts CLIP Training Recipe with Sparse Upcycling
Feb 03, 2025



Mixture-of-Experts (MoE) models are crucial for scaling model capacity while controlling inference costs. While integrating MoE into multimodal models like CLIP improves performance, training these models is notoriously challenging and expensive. We propose CLIP-Upcycling (CLIP-UP), an efficient alternative training strategy that converts a pre-trained dense CLIP model into a sparse MoE architecture. Through extensive experimentation with various settings and auxiliary losses, we demonstrate that CLIP-UP significantly reduces training complexity and cost. Remarkably, our sparse CLIP B/16 model, trained with CLIP-UP, outperforms its dense counterpart by 7.2% and 6.6% on COCO and Flickr30k text-to-image Recall@1 benchmarks respectively. It even surpasses the larger CLIP L/14 model on this task while using only 30% of the inference FLOPs. We further demonstrate the generalizability of our training recipe across different scales, establishing sparse upcycling as a practical and scalable approach for building efficient, high-performance CLIP models.
Pooling Pyramid Network for Object Detection
Jul 09, 2018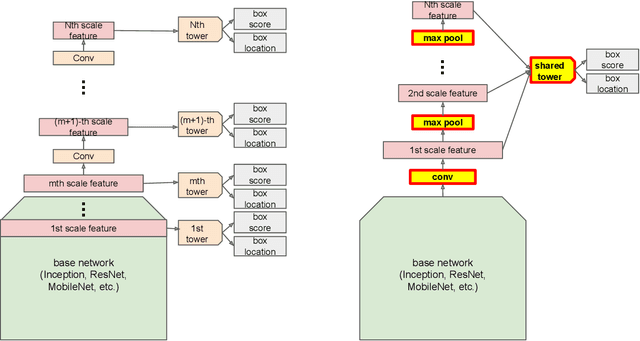

We'd like to share a simple tweak of Single Shot Multibox Detector (SSD) family of detectors, which is effective in reducing model size while maintaining the same quality. We share box predictors across all scales, and replace convolution between scales with max pooling. This has two advantages over vanilla SSD: (1) it avoids score miscalibration across scales; (2) the shared predictor sees the training data over all scales. Since we reduce the number of predictors to one, and trim all convolutions between them, model size is significantly smaller. We empirically show that these changes do not hurt model quality compared to vanilla SSD.
Multiple Instance Curriculum Learning for Weakly Supervised Object Detection
Nov 25, 2017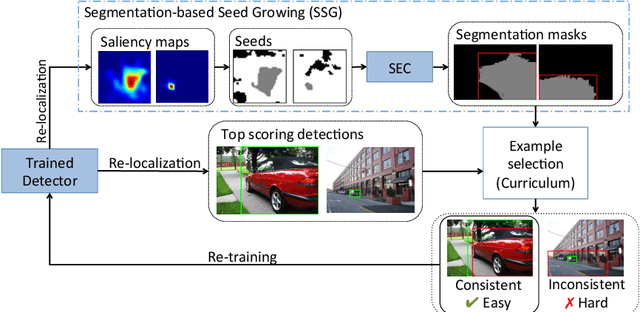

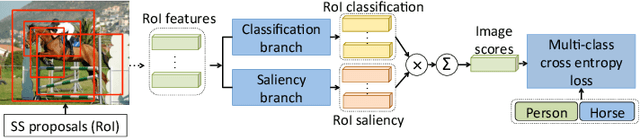

When supervising an object detector with weakly labeled data, most existing approaches are prone to trapping in the discriminative object parts, e.g., finding the face of a cat instead of the full body, due to lacking the supervision on the extent of full objects. To address this challenge, we incorporate object segmentation into the detector training, which guides the model to correctly localize the full objects. We propose the multiple instance curriculum learning (MICL) method, which injects curriculum learning (CL) into the multiple instance learning (MIL) framework. The MICL method starts by automatically picking the easy training examples, where the extent of the segmentation masks agree with detection bounding boxes. The training set is gradually expanded to include harder examples to train strong detectors that handle complex images. The proposed MICL method with segmentation in the loop outperforms the state-of-the-art weakly supervised object detectors by a substantial margin on the PASCAL VOC datasets.
Do We Need More Training Data?
Mar 05, 2015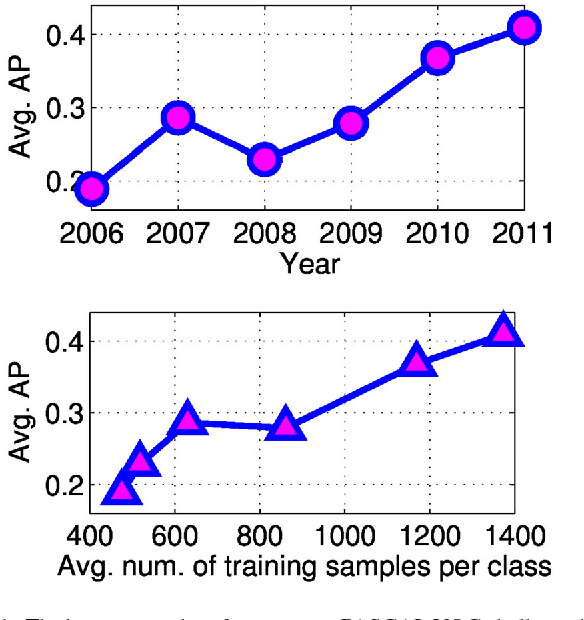
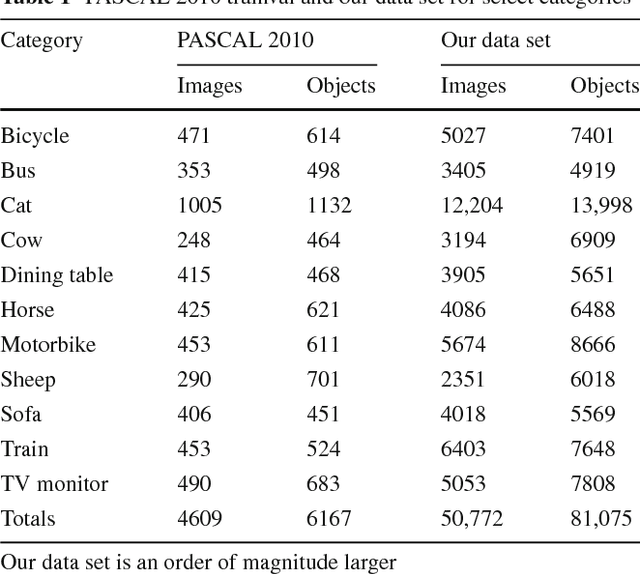
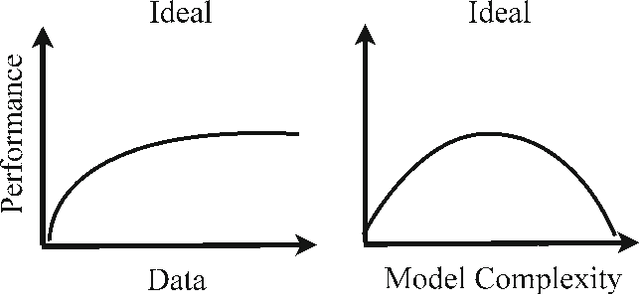
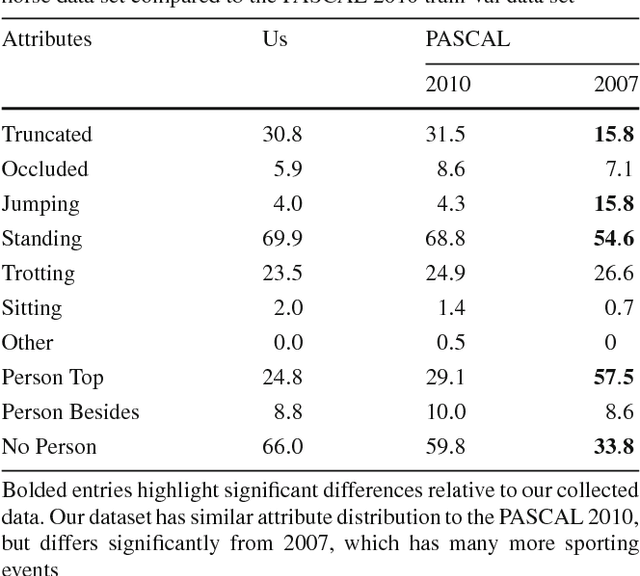
Datasets for training object recognition systems are steadily increasing in size. This paper investigates the question of whether existing detectors will continue to improve as data grows, or saturate in performance due to limited model complexity and the Bayes risk associated with the feature spaces in which they operate. We focus on the popular paradigm of discriminatively trained templates defined on oriented gradient features. We investigate the performance of mixtures of templates as the number of mixture components and the amount of training data grows. Surprisingly, even with proper treatment of regularization and "outliers", the performance of classic mixture models appears to saturate quickly ($\sim$10 templates and $\sim$100 positive training examples per template). This is not a limitation of the feature space as compositional mixtures that share template parameters via parts and that can synthesize new templates not encountered during training yield significantly better performance. Based on our analysis, we conjecture that the greatest gains in detection performance will continue to derive from improved representations and learning algorithms that can make efficient use of large datasets.