 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTALAN: Task-Aligned Latent Adaptation Networks for Targeted Post-Training of Large Language Models
Jun 05, 2026Targeted post-training aims to improve reasoning, math, and code without degrading strengths. Low-rank adapters are efficient but task-global; activation interventions are input-aware but often require separate probes, vectors, or inference-time steering. We introduce TALAN (Task-Aligned Latent Adaptation Networks), a sequence-conditioned latent side path inserted into a transformer's residual stream and co-trained with a low-rank adapter in one SFT loop. TALAN compresses the active sequence into latent memory, remixes it into token-level perturbations, and writes them back through a controlled residual update. It is configured along six axes: insertion location, memory size, mixer, writeback rule, trainability scope, and gradient scale. Across four Qwen3-family backbones and four STEM/code benchmarks, TALAN improves matched LoRA and DoRA baselines. With LoRA, it yields a +1.41 point cross-model mean gain, positive on all four backbones and non-negative on all 16 model-benchmark cells. With DoRA, it yields a +1.85 point mean gain, positive on all backbones and on 13 of 16 cells. Paired seed checks support positive average effects but show nontrivial variance, so we treat them as sensitivity checks. Cost is small: <1% trainable parameters relative to the backbone and 1.01-1.02x inference overhead versus matched LoRA. A Llama-3.2-1B transfer probe is also positive under LoRA and rsLoRA across seven paired seeds, supporting a transfer beyond Qwen. Internal-state analyses suggest TALAN is a small complementary activation intervention. The matched adapter update is 80-1,700x larger than the TALAN perturbation, yet their directions have near-zero cosine; per-layer measurements show this small orthogonal perturbation propagates and amplifies through depth. TALAN offers a practical platform for studying steerable activation-level adaptation within standard adapter-based post-training.
LoopFM: Learning frOm HistOrical RePresentations of Foundation Model for Recommendation
May 28, 2026Knowledge distillation (KD) transfers a single scalar prediction from a large foundation model (FM) to compact vertical models (VMs), suffering from diminishing transfer ratio -- the fraction of FM improvement captured by the VM -- as a single scalar cannot convey the rich intermediate knowledge that larger FMs learn. To address this bottleneck, we propose LoopFM (Learning frOm HistOrical ReP*resentations of FM), a framework that opens a high-bandwidth transfer channel by structuring FM intermediate embeddings as input features (e.g., user history sequence) for downstream VMs, without requiring real-time FM inference at serving and architectural coupling between FM and VM. We provide a theoretical framework for LoopFM with a gain decomposition and transfer-ratio analysis. On three public benchmarks, LoopFM demonstrates strong AUC improvements (e.g., 6\%+ on TaobaoAd) and complementary knowledge transfer capability with KD. On industrial-scale systems (billions of examples, trillion-parameter FMs), LoopFM approximately doubles the knowledge transfer ratio on top of KD, delivering a +0.5\% conversion improvement in Y1H1, and a +1.03\% and +1.22\% conversion improvement from two individual launches respectively in Y1H2.
SOLARIS: Speculative Offloading of Latent-bAsed Representation for Inference Scaling
Apr 13, 2026Recent advances in recommendation scaling laws have led to foundation models of unprecedented complexity. While these models offer superior performance, their computational demands make real-time serving impractical, often forcing practitioners to rely on knowledge distillation-compromising serving quality for efficiency. To address this challenge, we present SOLARIS (Speculative Offloading of Latent-bAsed Representation for Inference Scaling), a novel framework inspired by speculative decoding. SOLARIS proactively precomputes user-item interaction embeddings by predicting which user-item pairs are likely to appear in future requests, and asynchronously generating their foundation model representations ahead of time. This approach decouples the costly foundation model inference from the latency-critical serving path, enabling real-time knowledge transfer from models previously considered too expensive for online use. Deployed across Meta's advertising system serving billions of daily requests, SOLARIS achieves 0.67% revenue-driving top-line metrics gain, demonstrating its effectiveness at scale.
Meta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Dec 15, 2025The rapidly evolving landscape of products, surfaces, policies, and regulations poses significant challenges for deploying state-of-the-art recommendation models at industry scale, primarily due to data fragmentation across domains and escalating infrastructure costs that hinder sustained quality improvements. To address this challenge, we propose Lattice, a recommendation framework centered around model space redesign that extends Multi-Domain, Multi-Objective (MDMO) learning beyond models and learning objectives. Lattice addresses these challenges through a comprehensive model space redesign that combines cross-domain knowledge sharing, data consolidation, model unification, distillation, and system optimizations to achieve significant improvements in both quality and cost-efficiency. Our deployment of Lattice at Meta has resulted in 10% revenue-driving top-line metrics gain, 11.5% user satisfaction improvement, 6% boost in conversion rate, with 20% capacity saving.
C2AL: Cohort-Contrastive Auxiliary Learning for Large-scale Recommendation Systems
Oct 02, 2025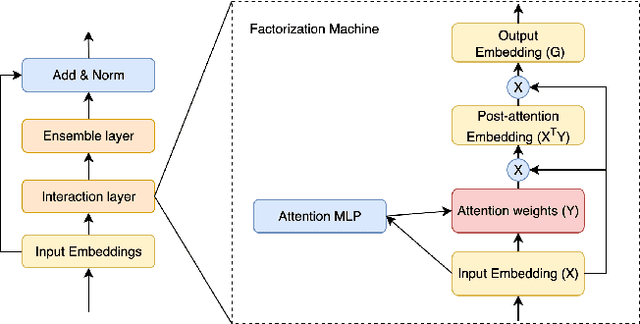
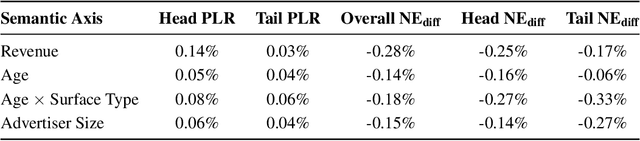
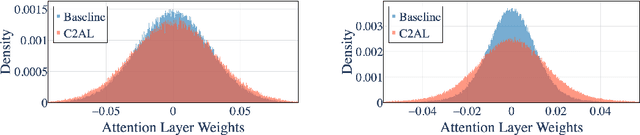

Training large-scale recommendation models under a single global objective implicitly assumes homogeneity across user populations. However, real-world data are composites of heterogeneous cohorts with distinct conditional distributions. As models increase in scale and complexity and as more data is used for training, they become dominated by central distribution patterns, neglecting head and tail regions. This imbalance limits the model's learning ability and can result in inactive attention weights or dead neurons. In this paper, we reveal how the attention mechanism can play a key role in factorization machines for shared embedding selection, and propose to address this challenge by analyzing the substructures in the dataset and exposing those with strong distributional contrast through auxiliary learning. Unlike previous research, which heuristically applies weighted labels or multi-task heads to mitigate such biases, we leverage partially conflicting auxiliary labels to regularize the shared representation. This approach customizes the learning process of attention layers to preserve mutual information with minority cohorts while improving global performance. We evaluated C2AL on massive production datasets with billions of data points each for six SOTA models. Experiments show that the factorization machine is able to capture fine-grained user-ad interactions using the proposed method, achieving up to a 0.16% reduction in normalized entropy overall and delivering gains exceeding 0.30% on targeted minority cohorts.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
An Integrated Sensing and Communications System Based on Affine Frequency Division Multiplexing
Jan 31, 2025



This paper proposes an integrated sensing and communications (ISAC) system based on affine frequency division multiplexing (AFDM) waveform. To this end, a metric set is designed according to not only the maximum tolerable delay/Doppler, but also the weighted spectral efficiency as well as the outage/error probability of sensing and communications. This enables the analytical investigation of the performance trade-offs of AFDM-ISAC system using the derived analytical relation among metrics and AFDM waveform parameters. Moreover, by revealing that delay and the integral/fractional parts of normalized Doppler can be decoupled in the affine Fourier transform-Doppler domain, an efficient estimation method is proposed for our AFDM-ISAC system, whose unambiguous Doppler can break through the limitation of subcarrier spacing. Theoretical analyses and numerical results verify that our proposed AFDM-ISAC system may significantly enlarge unambiguous delay/Doppler while possessing good spectral efficiency and peak-to-sidelobe level ratio in high-mobility scenarios.
Multi-Satellite Cooperative Networks: Joint Hybrid Beamforming and User Scheduling Design
Oct 12, 2023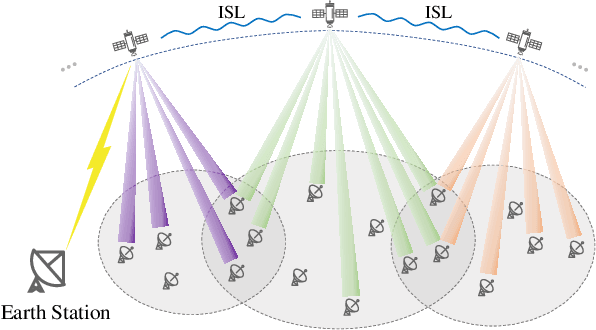
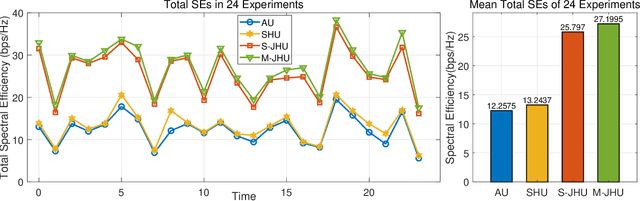
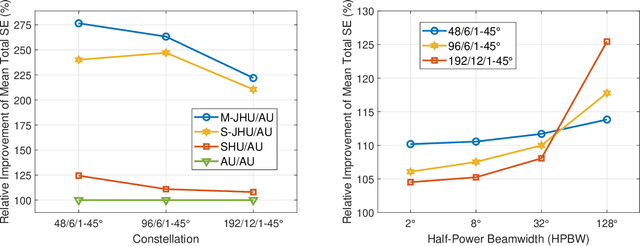
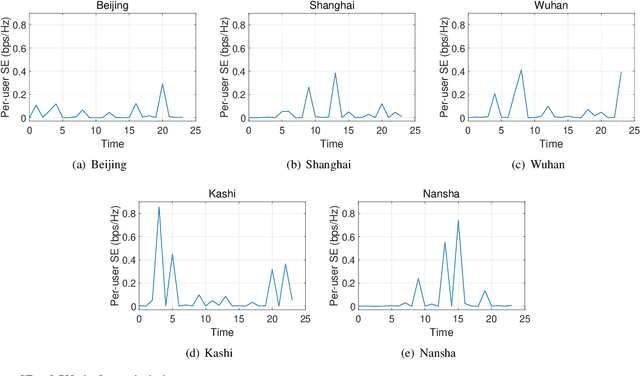
In this paper, we consider a cooperative communication network where multiple low-Earth-orbit satellites provide services for ground users (GUs) (at the same time and on the same frequency). The multi-satellite cooperative network has great potential for satellite communications due to its dense configuration, extensive coverage, and large spectral efficiency. However, the communication and computational resources on satellites are usually restricted. Therefore, considering the limitation of the on-board radio-frequency chains of satellites, we first propose a hybrid beamforming method consisting of analog beamforming for beam alignment and digital beamforming for interference mitigation. Then, to establish appropriate connections between the satellites and GUs, we propose a low-complexity heuristic user scheduling algorithm which determines the connections according to the total spectral efficiency increment of the multi-satellite cooperative network. Next, considering the intrinsic connection between beamforming and user scheduling, a joint hybrid beamforming and user scheduling (JHU) scheme is proposed to dramatically improve the performance of the multi-satellite cooperative network. In addition to the single-connection scenario, we also consider the multi-connection case using the JHU scheme. Moreover, simulations are conducted to compare the proposed schemes with representative baselines and to analyze the key factors influencing the performance of the multi-satellite cooperative network.
Towards the Better Ranking Consistency: A Multi-task Learning Framework for Early Stage Ads Ranking
Jul 12, 2023



Dividing ads ranking system into retrieval, early, and final stages is a common practice in large scale ads recommendation to balance the efficiency and accuracy. The early stage ranking often uses efficient models to generate candidates out of a set of retrieved ads. The candidates are then fed into a more computationally intensive but accurate final stage ranking system to produce the final ads recommendation. As the early and final stage ranking use different features and model architectures because of system constraints, a serious ranking consistency issue arises where the early stage has a low ads recall, i.e., top ads in the final stage are ranked low in the early stage. In order to pass better ads from the early to the final stage ranking, we propose a multi-task learning framework for early stage ranking to capture multiple final stage ranking components (i.e. ads clicks and ads quality events) and their task relations. With our multi-task learning framework, we can not only achieve serving cost saving from the model consolidation, but also improve the ads recall and ranking consistency. In the online A/B testing, our framework achieves significantly higher click-through rate (CTR), conversion rate (CVR), total value and better ads-quality (e.g. reduced ads cross-out rate) in a large scale industrial ads ranking system.
Joint Hybrid Beamforming and User Scheduling for Multi-Satellite Cooperative Networks
Jan 13, 2023



In this paper, we consider a cooperative communication network where multiple satellites provide services for ground users (GUs) (at the same time and on the same frequency). The communication and computational resources on satellites are usually restricted and the satellite-GU link determination affects the communication performance significantly when multiple satellites provide services for multiple GUs in a collaborative manner. Therefore, considering the limitation of the on-board radio-frequency chains, we first propose a hybrid beamforming method consisting of analog beamforming for beam alignment and digital beamforming for interference mitigation. Then, to establish appropriate connections between satellites and GUs, we propose a heuristic user scheduling algorithm which determines the connections according to the total spectral efficiency (SE) increment of the multi-satellite cooperative network. Next, a joint hybrid beamforming and user scheduling scheme is proposed to dramatically improve the performance of the multi-satellite cooperative network. Moreover, simulations are conducted to compare the proposed schemes with representative baselines and analyze the key factors influencing the performance of the multi-satellite cooperative network. It is shown that the proposed joint beamforming and user scheduling approach can provide 47.2% SE improvement on average as compared with its non-joint counterpart.