 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Motion Prediction via Learning Local Structure Representations and Temporal Dependencies
Feb 20, 2019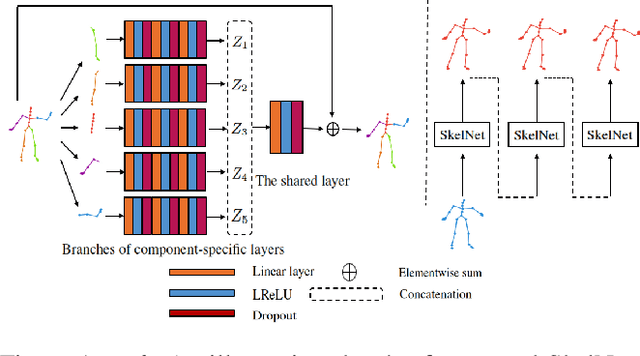
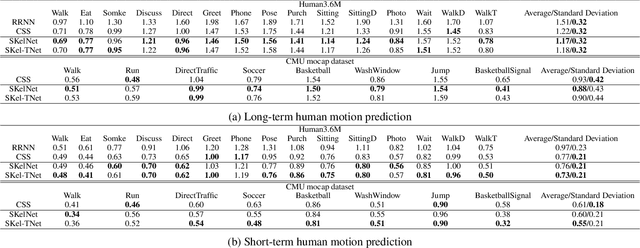
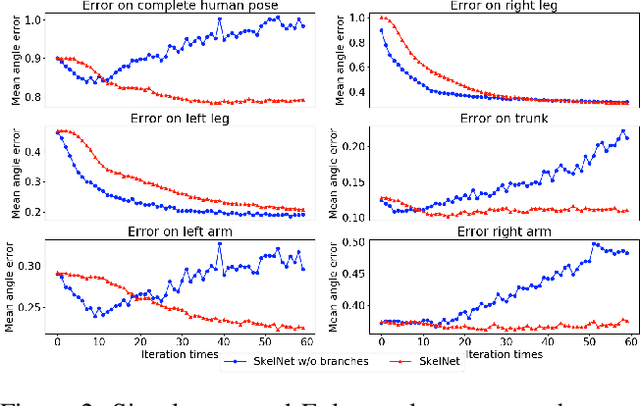
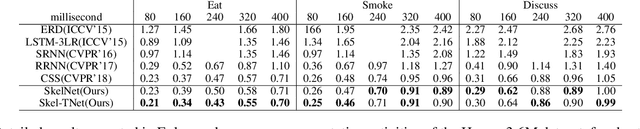
Human motion prediction from motion capture data is a classical problem in the computer vision, and conventional methods take the holistic human body as input. These methods ignore the fact that, in various human activities, different body components (limbs and the torso) have distinctive characteristics in terms of the moving pattern. In this paper, we argue local representations on different body components should be learned separately and, based on such idea, propose a network, Skeleton Network (SkelNet), for long-term human motion prediction. Specifically, at each time-step, local structure representations of input (human body) are obtained via SkelNet's branches of component-specific layers, then the shared layer uses local spatial representations to predict the future human pose. Our SkelNet is the first to use local structure representations for predicting the human motion. Then, for short-term human motion prediction, we propose the second network, named as Skeleton Temporal Network (Skel-TNet). Skel-TNet consists of three components: SkelNet and a Recurrent Neural Network, they have advantages in learning spatial and temporal dependencies for predicting human motion, respectively; a feed-forward network that outputs the final estimation. Our methods achieve promising results on the Human3.6M dataset and the CMU motion capture dataset.
Towards Visible and Thermal Drone Monitoring with Convolutional Neural Networks
Dec 19, 2018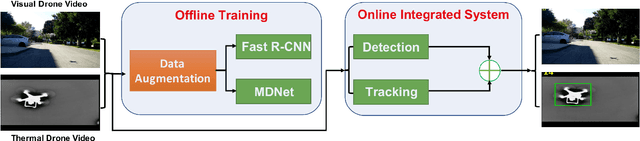



This paper reports a visible and thermal drone monitoring system that integrates deep-learning-based detection and tracking modules. The biggest challenge in adopting deep learning methods for drone detection is the paucity of training drone images especially thermal drone images. To address this issue, we develop two data augmentation techniques. One is a model-based drone augmentation technique that automatically generates visible drone images with a bounding box label on the drone's location. The other is exploiting an adversarial data augmentation methodology to create thermal drone images. To track a small flying drone, we utilize the residual information between consecutive image frames. Finally, we present an integrated detection and tracking system that outperforms the performance of each individual module containing detection or tracking only. The experiments show that even being trained on synthetic data, the proposed system performs well on real-world drone images with complex background. The USC drone detection and tracking dataset with user labeled bounding boxes is available to the public.
Unsupervised Video Object Segmentation with Distractor-Aware Online Adaptation
Dec 19, 2018

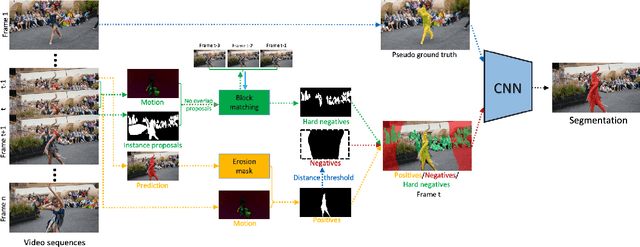

Unsupervised video object segmentation is a crucial application in video analysis without knowing any prior information about the objects. It becomes tremendously challenging when multiple objects occur and interact in a given video clip. In this paper, a novel unsupervised video object segmentation approach via distractor-aware online adaptation (DOA) is proposed. DOA models spatial-temporal consistency in video sequences by capturing background dependencies from adjacent frames. Instance proposals are generated by the instance segmentation network for each frame and then selected by motion information as hard negatives if they exist and positives. To adopt high-quality hard negatives, the block matching algorithm is then applied to preceding frames to track the associated hard negatives. General negatives are also introduced in case that there are no hard negatives in the sequence and experiments demonstrate both kinds of negatives (distractors) are complementary. Finally, we conduct DOA using the positive, negative, and hard negative masks to update the foreground/background segmentation. The proposed approach achieves state-of-the-art results on two benchmark datasets, DAVIS 2016 and FBMS-59 datasets.
Design Pseudo Ground Truth with Motion Cue for Unsupervised Video Object Segmentation
Dec 13, 2018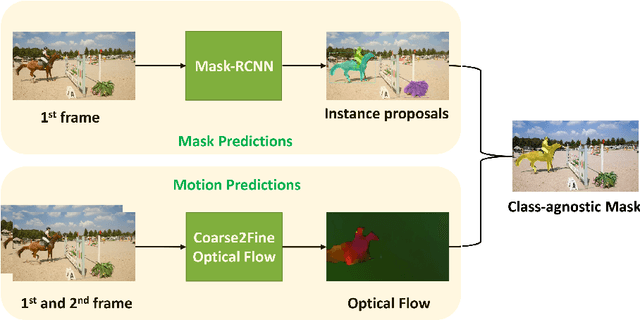


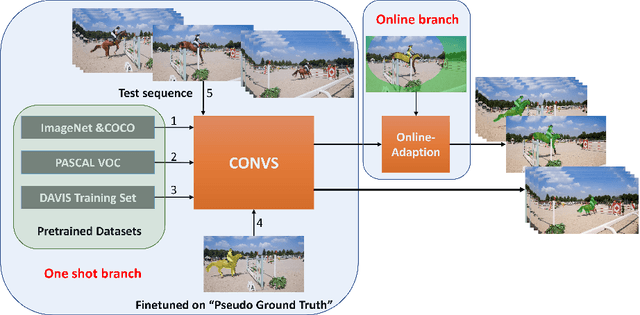
One major technique debt in video object segmentation is to label the object masks for training instances. As a result, we propose to prepare inexpensive, yet high quality pseudo ground truth corrected with motion cue for video object segmentation training. Our method conducts semantic segmentation using instance segmentation networks and, then, selects the segmented object of interest as the pseudo ground truth based on the motion information. Afterwards, the pseudo ground truth is exploited to finetune the pretrained objectness network to facilitate object segmentation in the remaining frames of the video. We show that the pseudo ground truth could effectively improve the segmentation performance. This straightforward unsupervised video object segmentation method is more efficient than existing methods. Experimental results on DAVIS and FBMS show that the proposed method outperforms state-of-the-art unsupervised segmentation methods on various benchmark datasets. And the category-agnostic pseudo ground truth has great potential to extend to multiple arbitrary object tracking.
A Deep Learning Approach to Drone Monitoring
Dec 04, 2017



A drone monitoring system that integrates deep-learning-based detection and tracking modules is proposed in this work. The biggest challenge in adopting deep learning methods for drone detection is the limited amount of training drone images. To address this issue, we develop a model-based drone augmentation technique that automatically generates drone images with a bounding box label on drone's location. To track a small flying drone, we utilize the residual information between consecutive image frames. Finally, we present an integrated detection and tracking system that outperforms the performance of each individual module containing detection or tracking only. The experiments show that, even being trained on synthetic data, the proposed system performs well on real world drone images with complex background. The USC drone detection and tracking dataset with user labeled bounding boxes is available to the public.
Deep 3D Face Identification
Mar 30, 2017
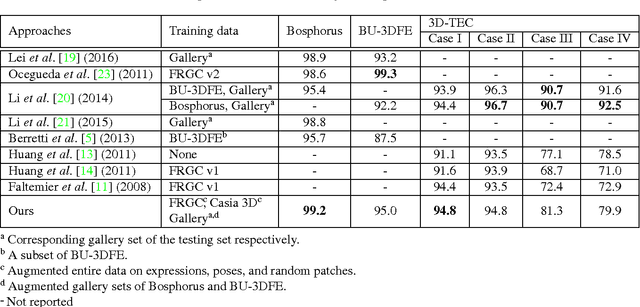
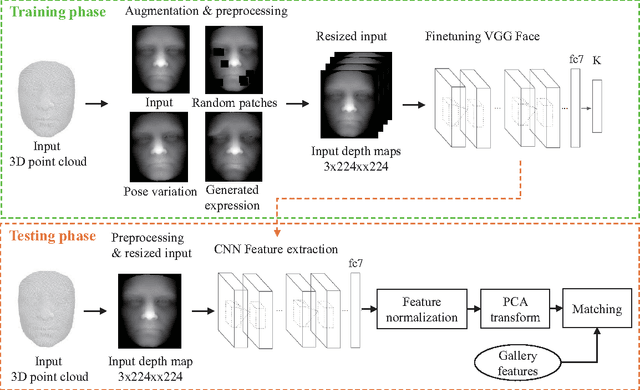
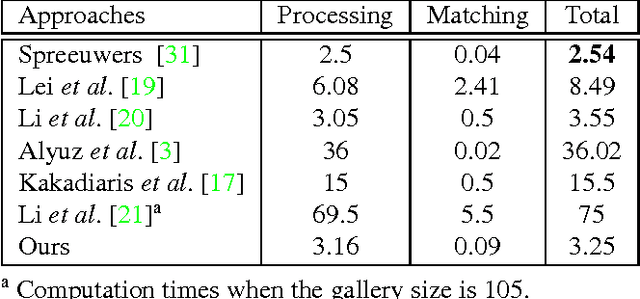
We propose a novel 3D face recognition algorithm using a deep convolutional neural network (DCNN) and a 3D augmentation technique. The performance of 2D face recognition algorithms has significantly increased by leveraging the representational power of deep neural networks and the use of large-scale labeled training data. As opposed to 2D face recognition, training discriminative deep features for 3D face recognition is very difficult due to the lack of large-scale 3D face datasets. In this paper, we show that transfer learning from a CNN trained on 2D face images can effectively work for 3D face recognition by fine-tuning the CNN with a relatively small number of 3D facial scans. We also propose a 3D face augmentation technique which synthesizes a number of different facial expressions from a single 3D face scan. Our proposed method shows excellent recognition results on Bosphorus, BU-3DFE, and 3D-TEC datasets, without using hand-crafted features. The 3D identification using our deep features also scales well for large databases.
Pooling Faces: Template based Face Recognition with Pooled Face Images
Jul 06, 2016

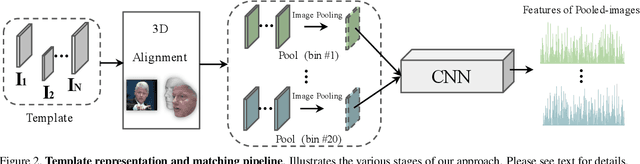
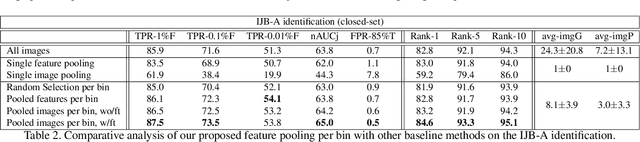
We propose a novel approach to template based face recognition. Our dual goal is to both increase recognition accuracy and reduce the computational and storage costs of template matching. To do this, we leverage on an approach which was proven effective in many other domains, but, to our knowledge, never fully explored for face images: average pooling of face photos. We show how (and why!) the space of a template's images can be partitioned and then pooled based on image quality and head pose and the effect this has on accuracy and template size. We perform extensive tests on the IJB-A and Janus CS2 template based face identification and verification benchmarks. These show that not only does our approach outperform published state of the art despite requiring far fewer cross template comparisons, but also, surprisingly, that image pooling performs on par with deep feature pooling.
Face Recognition Using Deep Multi-Pose Representations
Mar 23, 2016


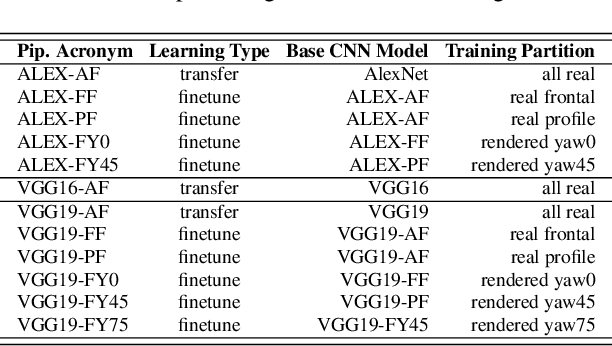
We introduce our method and system for face recognition using multiple pose-aware deep learning models. In our representation, a face image is processed by several pose-specific deep convolutional neural network (CNN) models to generate multiple pose-specific features. 3D rendering is used to generate multiple face poses from the input image. Sensitivity of the recognition system to pose variations is reduced since we use an ensemble of pose-specific CNN features. The paper presents extensive experimental results on the effect of landmark detection, CNN layer selection and pose model selection on the performance of the recognition pipeline. Our novel representation achieves better results than the state-of-the-art on IARPA's CS2 and NIST's IJB-A in both verification and identification (i.e. search) tasks.