 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Motion Prediction via Learning Local Structure Representations and Temporal Dependencies
Paper and Code
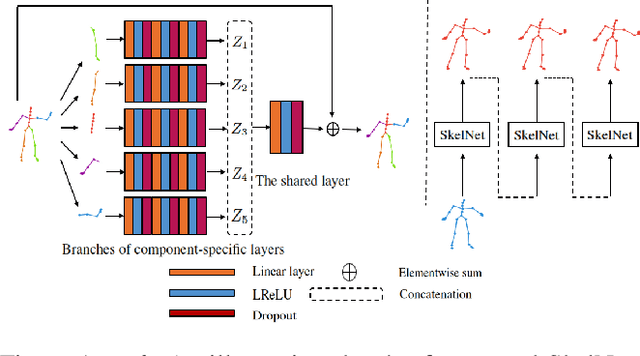
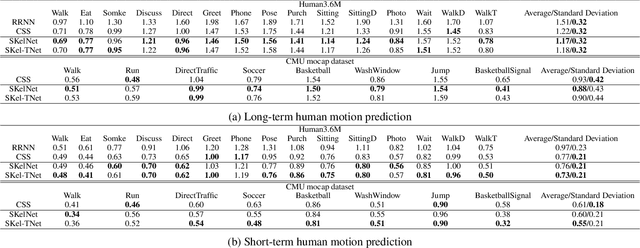
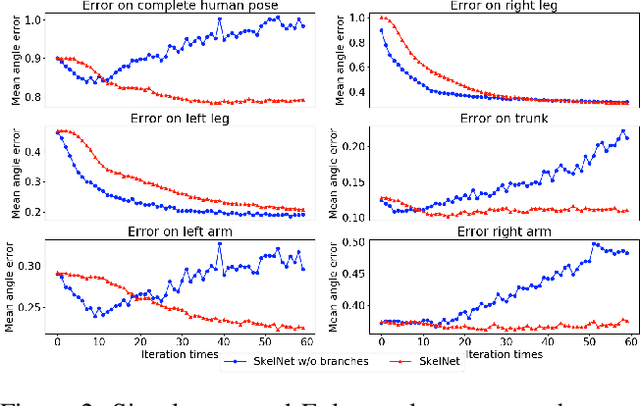
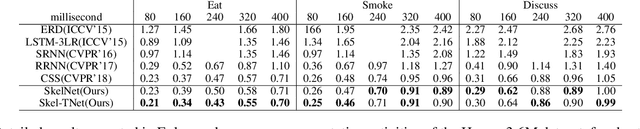
Human motion prediction from motion capture data is a classical problem in the computer vision, and conventional methods take the holistic human body as input. These methods ignore the fact that, in various human activities, different body components (limbs and the torso) have distinctive characteristics in terms of the moving pattern. In this paper, we argue local representations on different body components should be learned separately and, based on such idea, propose a network, Skeleton Network (SkelNet), for long-term human motion prediction. Specifically, at each time-step, local structure representations of input (human body) are obtained via SkelNet's branches of component-specific layers, then the shared layer uses local spatial representations to predict the future human pose. Our SkelNet is the first to use local structure representations for predicting the human motion. Then, for short-term human motion prediction, we propose the second network, named as Skeleton Temporal Network (Skel-TNet). Skel-TNet consists of three components: SkelNet and a Recurrent Neural Network, they have advantages in learning spatial and temporal dependencies for predicting human motion, respectively; a feed-forward network that outputs the final estimation. Our methods achieve promising results on the Human3.6M dataset and the CMU motion capture dataset.