 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBIRD-PCC: Bi-directional Range Image-based Deep LiDAR Point Cloud Compression
Mar 09, 2023



The large amount of data collected by LiDAR sensors brings the issue of LiDAR point cloud compression (PCC). Previous works on LiDAR PCC have used range image representations and followed the predictive coding paradigm to create a basic prototype of a coding framework. However, their prediction methods give an inaccurate result due to the negligence of invalid pixels in range images and the omission of future frames in the time step. Moreover, their handcrafted design of residual coding methods could not fully exploit spatial redundancy. To remedy this, we propose a coding framework BIRD-PCC. Our prediction module is aware of the coordinates of invalid pixels in range images and takes a bidirectional scheme. Also, we introduce a deep-learned residual coding module that can further exploit spatial redundancy within a residual frame. Experiments conducted on SemanticKITTI and KITTI-360 datasets show that BIRD-PCC outperforms other methods in most bitrate conditions and generalizes well to unseen environments.
LSR: A Light-Weight Super-Resolution Method
Feb 27, 2023A light-weight super-resolution (LSR) method from a single image targeting mobile applications is proposed in this work. LSR predicts the residual image between the interpolated low-resolution (ILR) and high-resolution (HR) images using a self-supervised framework. To lower the computational complexity, LSR does not adopt the end-to-end optimization deep networks. It consists of three modules: 1) generation of a pool of rich and diversified representations in the neighborhood of a target pixel via unsupervised learning, 2) selecting a subset from the representation pool that is most relevant to the underlying super-resolution task automatically via supervised learning, 3) predicting the residual of the target pixel via regression. LSR has low computational complexity and reasonable model size so that it can be implemented on mobile/edge platforms conveniently. Besides, it offers better visual quality than classical exemplar-based methods in terms of PSNR/SSIM measures.
Fine-Grained Visual Recognition with Batch Confusion Norm
Oct 28, 2019
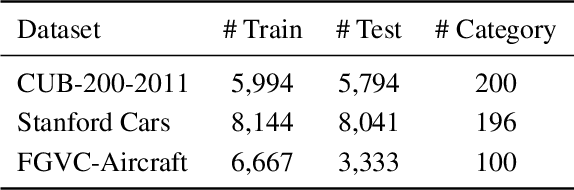
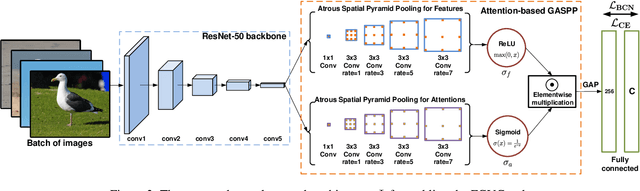
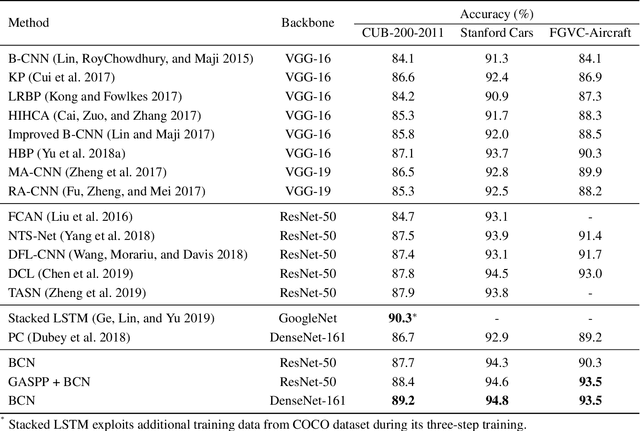
We introduce a regularization concept based on the proposed Batch Confusion Norm (BCN) to address Fine-Grained Visual Classification (FGVC). The FGVC problem is notably characterized by its two intriguing properties, significant inter-class similarity and intra-class variations, which cause learning an effective FGVC classifier a challenging task. Inspired by the use of pairwise confusion energy as a regularization mechanism, we develop the BCN technique to improve the FGVC learning by imposing class prediction confusion on each training batch, and consequently alleviate the possible overfitting due to exploring image feature of fine details. In addition, our method is implemented with an attention gated CNN model, boosted by the incorporation of Atrous Spatial Pyramid Pooling (ASPP) to extract discriminative features and proper attentions. To demonstrate the usefulness of our method, we report state-of-the-art results on several benchmark FGVC datasets, along with comprehensive ablation comparisons.
Unsupervised Video Object Segmentation with Distractor-Aware Online Adaptation
Dec 19, 2018

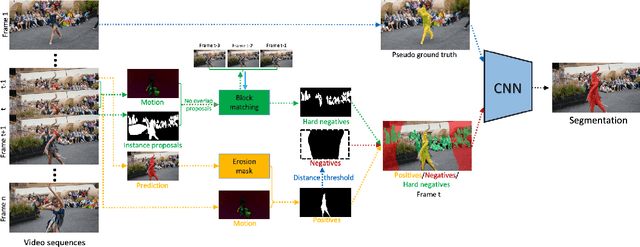

Unsupervised video object segmentation is a crucial application in video analysis without knowing any prior information about the objects. It becomes tremendously challenging when multiple objects occur and interact in a given video clip. In this paper, a novel unsupervised video object segmentation approach via distractor-aware online adaptation (DOA) is proposed. DOA models spatial-temporal consistency in video sequences by capturing background dependencies from adjacent frames. Instance proposals are generated by the instance segmentation network for each frame and then selected by motion information as hard negatives if they exist and positives. To adopt high-quality hard negatives, the block matching algorithm is then applied to preceding frames to track the associated hard negatives. General negatives are also introduced in case that there are no hard negatives in the sequence and experiments demonstrate both kinds of negatives (distractors) are complementary. Finally, we conduct DOA using the positive, negative, and hard negative masks to update the foreground/background segmentation. The proposed approach achieves state-of-the-art results on two benchmark datasets, DAVIS 2016 and FBMS-59 datasets.
Design Pseudo Ground Truth with Motion Cue for Unsupervised Video Object Segmentation
Dec 13, 2018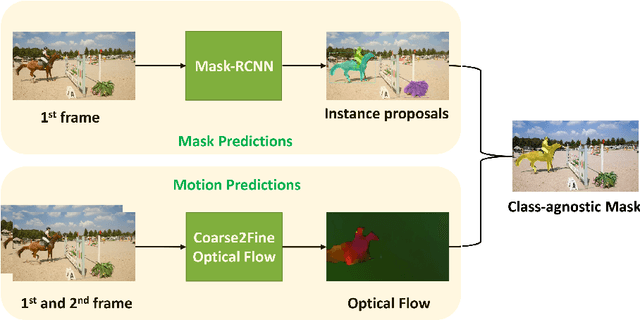


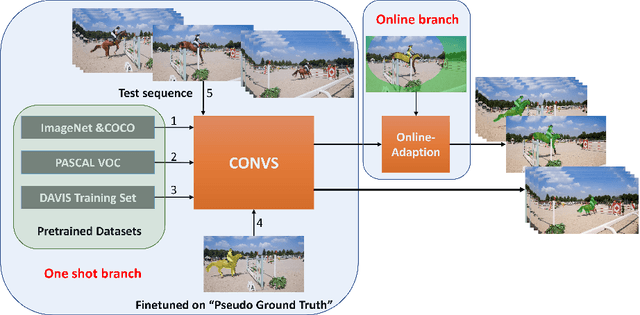
One major technique debt in video object segmentation is to label the object masks for training instances. As a result, we propose to prepare inexpensive, yet high quality pseudo ground truth corrected with motion cue for video object segmentation training. Our method conducts semantic segmentation using instance segmentation networks and, then, selects the segmented object of interest as the pseudo ground truth based on the motion information. Afterwards, the pseudo ground truth is exploited to finetune the pretrained objectness network to facilitate object segmentation in the remaining frames of the video. We show that the pseudo ground truth could effectively improve the segmentation performance. This straightforward unsupervised video object segmentation method is more efficient than existing methods. Experimental results on DAVIS and FBMS show that the proposed method outperforms state-of-the-art unsupervised segmentation methods on various benchmark datasets. And the category-agnostic pseudo ground truth has great potential to extend to multiple arbitrary object tracking.