 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSR: A Light-Weight Super-Resolution Method
Feb 27, 2023A light-weight super-resolution (LSR) method from a single image targeting mobile applications is proposed in this work. LSR predicts the residual image between the interpolated low-resolution (ILR) and high-resolution (HR) images using a self-supervised framework. To lower the computational complexity, LSR does not adopt the end-to-end optimization deep networks. It consists of three modules: 1) generation of a pool of rich and diversified representations in the neighborhood of a target pixel via unsupervised learning, 2) selecting a subset from the representation pool that is most relevant to the underlying super-resolution task automatically via supervised learning, 3) predicting the residual of the target pixel via regression. LSR has low computational complexity and reasonable model size so that it can be implemented on mobile/edge platforms conveniently. Besides, it offers better visual quality than classical exemplar-based methods in terms of PSNR/SSIM measures.
GENHOP: An Image Generation Method Based on Successive Subspace Learning
Oct 07, 2022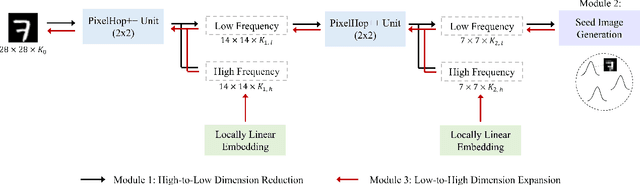
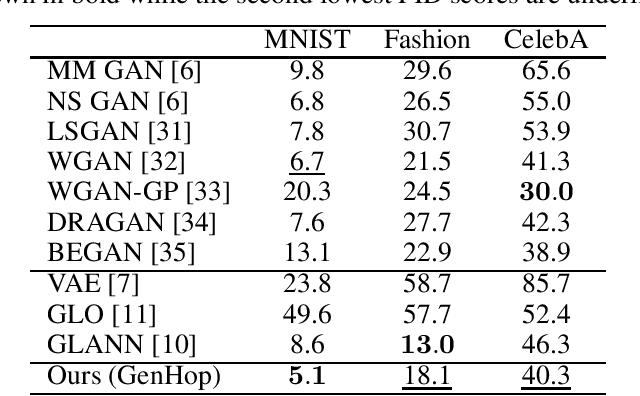
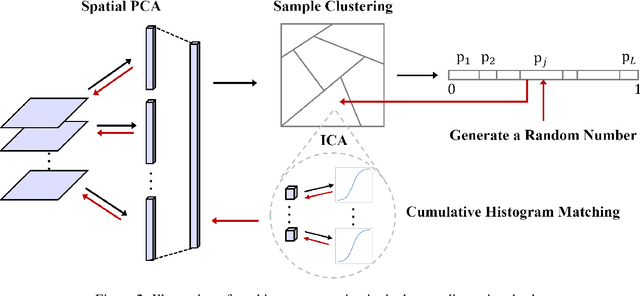
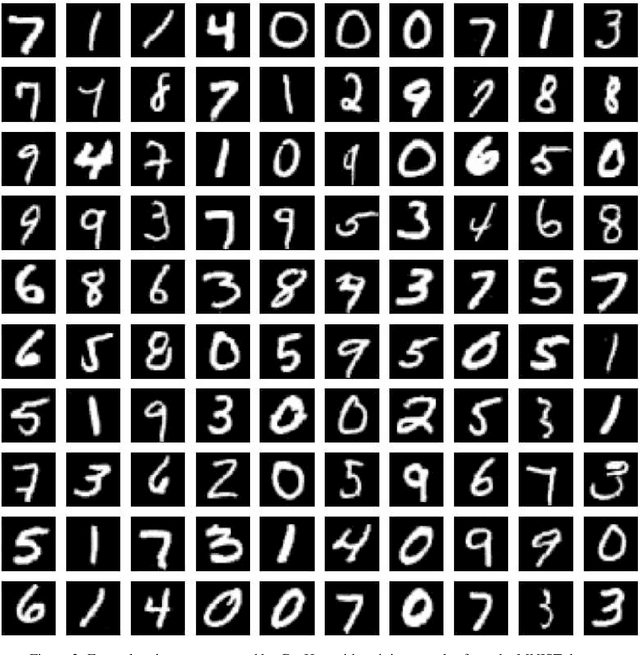
Being different from deep-learning-based (DL-based) image generation methods, a new image generative model built upon successive subspace learning principle is proposed and named GenHop (an acronym of Generative PixelHop) in this work. GenHop consists of three modules: 1) high-to-low dimension reduction, 2) seed image generation, and 3) low-to-high dimension expansion. In the first module, it builds a sequence of high-to-low dimensional subspaces through a sequence of whitening processes, each of which contains samples of joint-spatial-spectral representation. In the second module, it generates samples in the lowest dimensional subspace. In the third module, it finds a proper high-dimensional sample for a seed image by adding details back via locally linear embedding (LLE) and a sequence of coloring processes. Experiments show that GenHop can generate visually pleasant images whose FID scores are comparable or even better than those of DL-based generative models for MNIST, Fashion-MNIST and CelebA datasets.
TGHop: An Explainable, Efficient and Lightweight Method for Texture Generation
Jul 08, 2021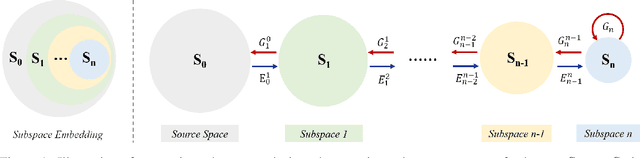
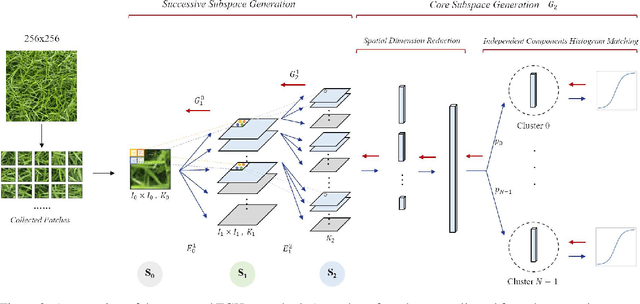

An explainable, efficient and lightweight method for texture generation, called TGHop (an acronym of Texture Generation PixelHop), is proposed in this work. Although synthesis of visually pleasant texture can be achieved by deep neural networks, the associated models are large in size, difficult to explain in theory, and computationally expensive in training. In contrast, TGHop is small in its model size, mathematically transparent, efficient in training and inference, and able to generate high quality texture. Given an exemplary texture, TGHop first crops many sample patches out of it to form a collection of sample patches called the source. Then, it analyzes pixel statistics of samples from the source and obtains a sequence of fine-to-coarse subspaces for these patches by using the PixelHop++ framework. To generate texture patches with TGHop, we begin with the coarsest subspace, which is called the core, and attempt to generate samples in each subspace by following the distribution of real samples. Finally, texture patches are stitched to form texture images of a large size. It is demonstrated by experimental results that TGHop can generate texture images of superior quality with a small model size and at a fast speed.
Noise-Aware Texture-Preserving Low-Light Enhancement
Sep 02, 2020
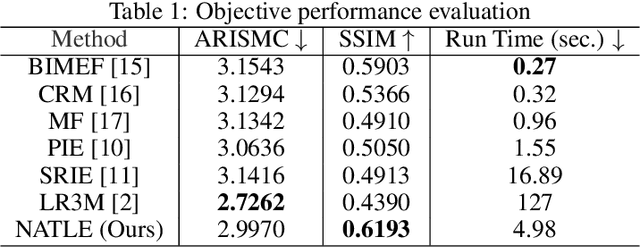


A simple and effective low-light image enhancement method based on a noise-aware texture-preserving retinex model is proposed in this work. The new method, called NATLE, attempts to strike a balance between noise removal and natural texture preservation through a low-complexity solution. Its cost function includes an estimated piece-wise smooth illumination map and a noise-free texture-preserving reflectance map. Afterwards, illumination is adjusted to form the enhanced image together with the reflectance map. Extensive experiments are conducted on common low-light image enhancement datasets to demonstrate the superior performance of NATLE.
NITES: A Non-Parametric Interpretable Texture Synthesis Method
Sep 02, 2020



A non-parametric interpretable texture synthesis method, called the NITES method, is proposed in this work. Although automatic synthesis of visually pleasant texture can be achieved by deep neural networks nowadays, the associated generation models are mathematically intractable and their training demands higher computational cost. NITES offers a new texture synthesis solution to address these shortcomings. NITES is mathematically transparent and efficient in training and inference. The input is a single exemplary texture image. The NITES method crops out patches from the input and analyzes the statistical properties of these texture patches to obtain their joint spatial-spectral representations. Then, the probabilistic distributions of samples in the joint spatial-spectral spaces are characterized. Finally, numerous texture images that are visually similar to the exemplary texture image can be generated automatically. Experimental results are provided to show the superior quality of generated texture images and efficiency of the proposed NITES method in terms of both training and inference time.