 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-Level Prompt Optimization for Multimodal LLM-as-a-Judge
Feb 11, 2026Large language models (LLMs) have become widely adopted as automated judges for evaluating AI-generated content. Despite their success, aligning LLM-based evaluations with human judgments remains challenging. While supervised fine-tuning on human-labeled data can improve alignment, it is costly and inflexible, requiring new training for each task or dataset. Recent progress in auto prompt optimization (APO) offers a more efficient alternative by automatically improving the instructions that guide LLM judges. However, existing APO methods primarily target text-only evaluations and remain underexplored in multimodal settings. In this work, we study auto prompt optimization for multimodal LLM-as-a-judge, particularly for evaluating AI-generated images. We identify a key bottleneck: multimodal models can only process a limited number of visual examples due to context window constraints, which hinders effective trial-and-error prompt refinement. To overcome this, we propose BLPO, a bi-level prompt optimization framework that converts images into textual representations while preserving evaluation-relevant visual cues. Our bi-level optimization approach jointly refines the judge prompt and the I2T prompt to maintain fidelity under limited context budgets. Experiments on four datasets and three LLM judges demonstrate the effectiveness of our method.
Advancing Music Therapy: Integrating Eastern Five-Element Music Theory and Western Techniques with AI in the Novel Five-Element Harmony System
Dec 09, 2024

In traditional medical practices, music therapy has proven effective in treating various psychological and physiological ailments. Particularly in Eastern traditions, the Five Elements Music Therapy (FEMT), rooted in traditional Chinese medicine, possesses profound cultural significance and unique therapeutic philosophies. With the rapid advancement of Information Technology and Artificial Intelligence, applying these modern technologies to FEMT could enhance the personalization and cultural relevance of the therapy and potentially improve therapeutic outcomes. In this article, we developed a music therapy system for the first time by applying the theory of the five elements in music therapy to practice. This innovative approach integrates advanced Information Technology and Artificial Intelligence with Five-Element Music Therapy (FEMT) to enhance personalized music therapy practices. As traditional music therapy predominantly follows Western methodologies, the unique aspects of Eastern practices, specifically the Five-Element theory from traditional Chinese medicine, should be considered. This system aims to bridge this gap by utilizing computational technologies to provide a more personalized, culturally relevant, and therapeutically effective music therapy experience.
EmoSpeech: A Corpus of Emotionally Rich and Contextually Detailed Speech Annotations
Dec 09, 2024

Advances in text-to-speech (TTS) technology have significantly improved the quality of generated speech, closely matching the timbre and intonation of the target speaker. However, due to the inherent complexity of human emotional expression, the development of TTS systems capable of controlling subtle emotional differences remains a formidable challenge. Existing emotional speech databases often suffer from overly simplistic labelling schemes that fail to capture a wide range of emotional states, thus limiting the effectiveness of emotion synthesis in TTS applications. To this end, recent efforts have focussed on building databases that use natural language annotations to describe speech emotions. However, these approaches are costly and require more emotional depth to train robust systems. In this paper, we propose a novel process aimed at building databases by systematically extracting emotion-rich speech segments and annotating them with detailed natural language descriptions through a generative model. This approach enhances the emotional granularity of the database and significantly reduces the reliance on costly manual annotations by automatically augmenting the data with high-level language models. The resulting rich database provides a scalable and economically viable solution for developing a more nuanced and dynamic basis for developing emotionally controlled TTS systems.
PEDENet: Image Anomaly Localization via Patch Embedding and Density Estimation
Oct 29, 2021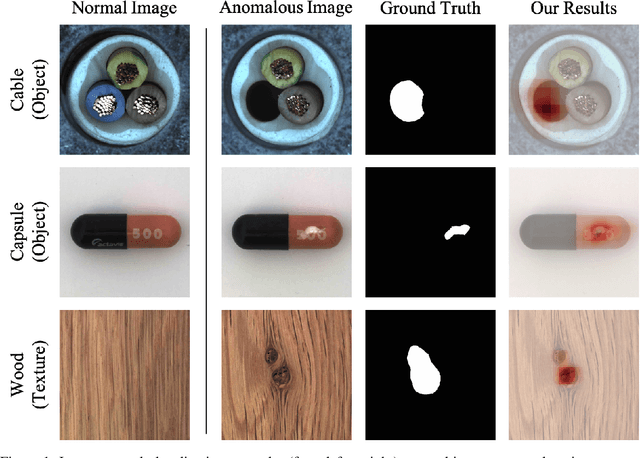
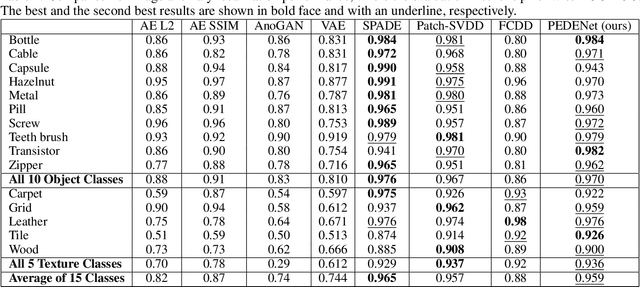
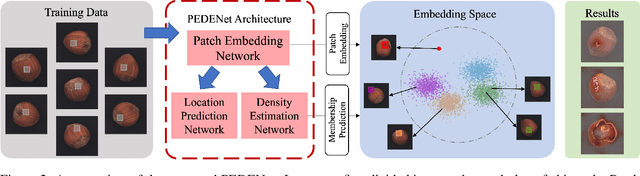
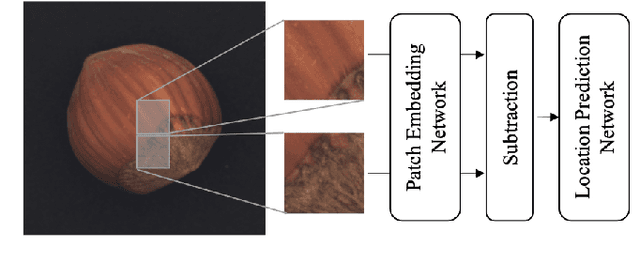
A neural network targeting at unsupervised image anomaly localization, called the PEDENet, is proposed in this work. PEDENet contains a patch embedding (PE) network, a density estimation (DE) network, and an auxiliary network called the location prediction (LP) network. The PE network takes local image patches as input and performs dimension reduction to get low-dimensional patch embeddings via a deep encoder structure. Being inspired by the Gaussian Mixture Model (GMM), the DE network takes those patch embeddings and then predicts the cluster membership of an embedded patch. The sum of membership probabilities is used as a loss term to guide the learning process. The LP network is a Multi-layer Perception (MLP), which takes embeddings from two neighboring patches as input and predicts their relative location. The performance of the proposed PEDENet is evaluated extensively and benchmarked with that of state-of-the-art methods.
Geo-DefakeHop: High-Performance Geographic Fake Image Detection
Oct 19, 2021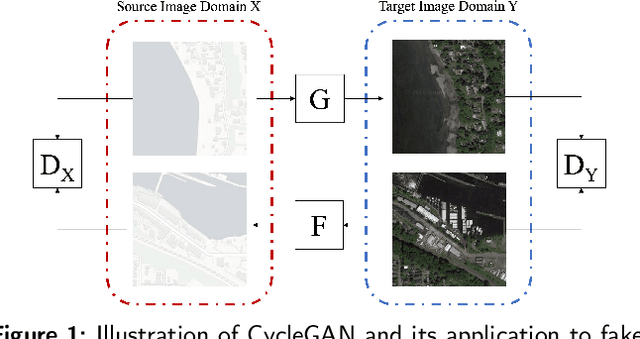
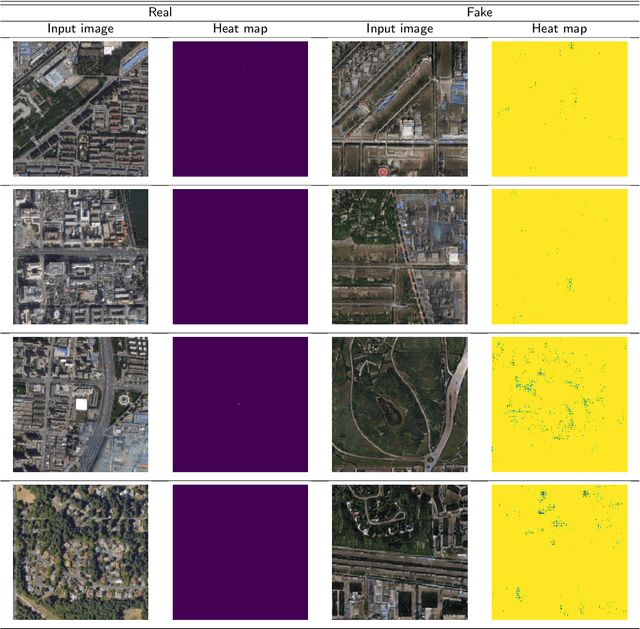
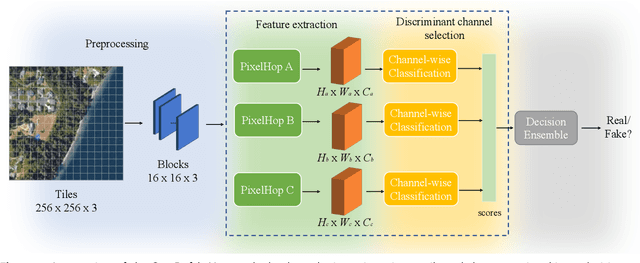

A robust fake satellite image detection method, called Geo-DefakeHop, is proposed in this work. Geo-DefakeHop is developed based on the parallel subspace learning (PSL) methodology. PSL maps the input image space into several feature subspaces using multiple filter banks. By exploring response differences of different channels between real and fake images for a filter bank, Geo-DefakeHop learns the most discriminant channels and uses their soft decision scores as features. Then, Geo-DefakeHop selects a few discriminant features from each filter bank and ensemble them to make a final binary decision. Geo-DefakeHop offers a light-weight high-performance solution to fake satellite images detection. Its model size is analyzed, which ranges from 0.8 to 62K parameters. Furthermore, it is shown by experimental results that it achieves an F1-score higher than 95\% under various common image manipulations such as resizing, compression and noise corruption.
TGHop: An Explainable, Efficient and Lightweight Method for Texture Generation
Jul 08, 2021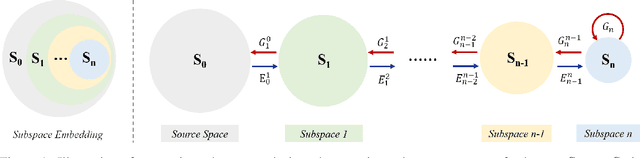
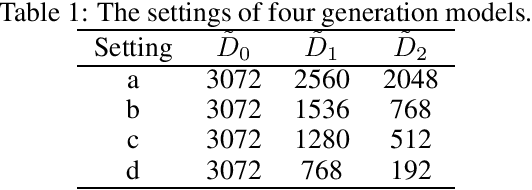
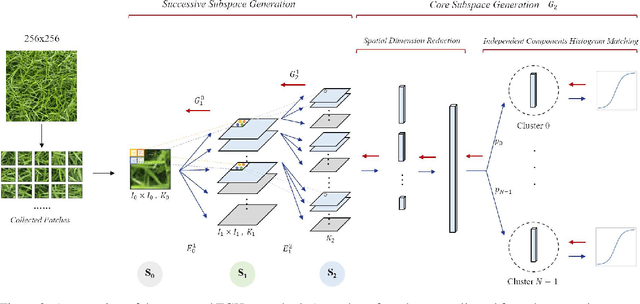

An explainable, efficient and lightweight method for texture generation, called TGHop (an acronym of Texture Generation PixelHop), is proposed in this work. Although synthesis of visually pleasant texture can be achieved by deep neural networks, the associated models are large in size, difficult to explain in theory, and computationally expensive in training. In contrast, TGHop is small in its model size, mathematically transparent, efficient in training and inference, and able to generate high quality texture. Given an exemplary texture, TGHop first crops many sample patches out of it to form a collection of sample patches called the source. Then, it analyzes pixel statistics of samples from the source and obtains a sequence of fine-to-coarse subspaces for these patches by using the PixelHop++ framework. To generate texture patches with TGHop, we begin with the coarsest subspace, which is called the core, and attempt to generate samples in each subspace by following the distribution of real samples. Finally, texture patches are stitched to form texture images of a large size. It is demonstrated by experimental results that TGHop can generate texture images of superior quality with a small model size and at a fast speed.
AnomalyHop: An SSL-based Image Anomaly Localization Method
May 08, 2021

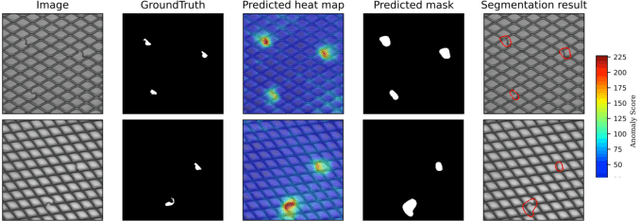
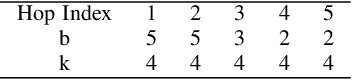
An image anomaly localization method based on the successive subspace learning (SSL) framework, called AnomalyHop, is proposed in this work. AnomalyHop consists of three modules: 1) feature extraction via successive subspace learning (SSL), 2) normality feature distributions modeling via Gaussian models, and 3) anomaly map generation and fusion. Comparing with state-of-the-art image anomaly localization methods based on deep neural networks (DNNs), AnomalyHop is mathematically transparent, easy to train, and fast in its inference speed. Besides, its area under the ROC curve (ROC-AUC) performance on the MVTec AD dataset is 95.9%, which is among the best of several benchmarking methods. Our codes are publicly available at Github.
Dynamic Texture Synthesis by Incorporating Long-range Spatial and Temporal Correlations
Apr 14, 2021

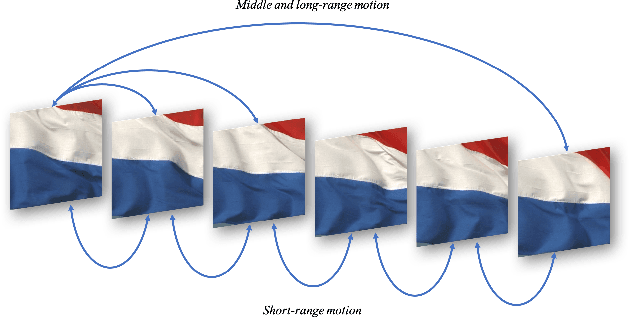

The main challenge of dynamic texture synthesis lies in how to maintain spatial and temporal consistency in synthesized videos. The major drawback of existing dynamic texture synthesis models comes from poor treatment of the long-range texture correlation and motion information. To address this problem, we incorporate a new loss term, called the Shifted Gram loss, to capture the structural and long-range correlation of the reference texture video. Furthermore, we introduce a frame sampling strategy to exploit long-period motion across multiple frames. With these two new techniques, the application scope of existing texture synthesis models can be extended. That is, they can synthesize not only homogeneous but also structured dynamic texture patterns. Thorough experimental results are provided to demonstrate that our proposed dynamic texture synthesis model offers state-of-the-art visual performance.
Unsupervised Video Object Segmentation with Distractor-Aware Online Adaptation
Dec 19, 2018

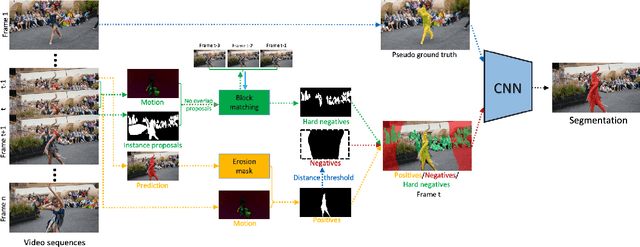

Unsupervised video object segmentation is a crucial application in video analysis without knowing any prior information about the objects. It becomes tremendously challenging when multiple objects occur and interact in a given video clip. In this paper, a novel unsupervised video object segmentation approach via distractor-aware online adaptation (DOA) is proposed. DOA models spatial-temporal consistency in video sequences by capturing background dependencies from adjacent frames. Instance proposals are generated by the instance segmentation network for each frame and then selected by motion information as hard negatives if they exist and positives. To adopt high-quality hard negatives, the block matching algorithm is then applied to preceding frames to track the associated hard negatives. General negatives are also introduced in case that there are no hard negatives in the sequence and experiments demonstrate both kinds of negatives (distractors) are complementary. Finally, we conduct DOA using the positive, negative, and hard negative masks to update the foreground/background segmentation. The proposed approach achieves state-of-the-art results on two benchmark datasets, DAVIS 2016 and FBMS-59 datasets.