 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Mar 03, 2025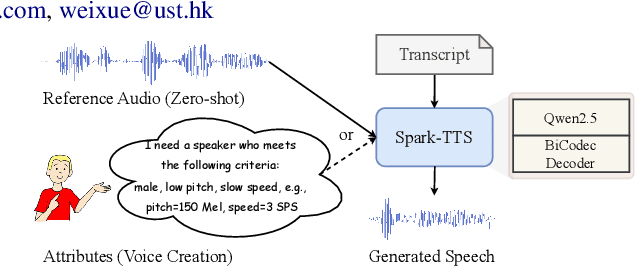
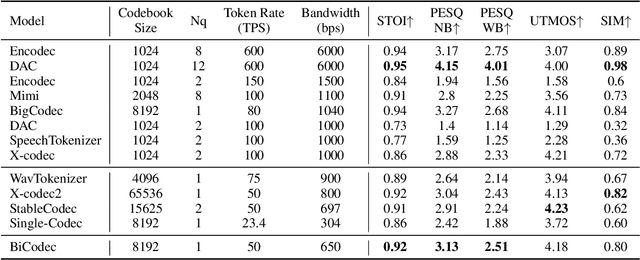
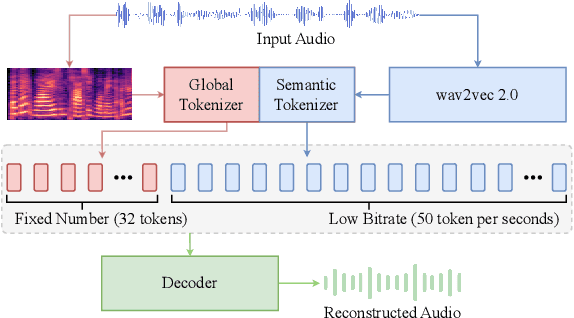
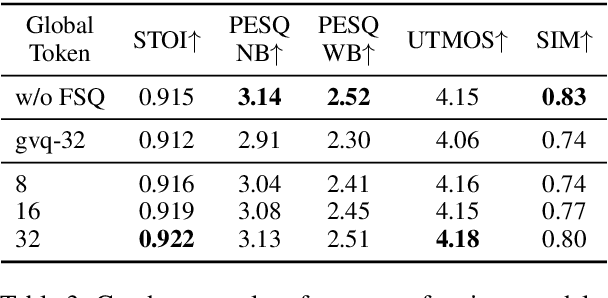
Recent advancements in large language models (LLMs) have driven significant progress in zero-shot text-to-speech (TTS) synthesis. However, existing foundation models rely on multi-stage processing or complex architectures for predicting multiple codebooks, limiting efficiency and integration flexibility. To overcome these challenges, we introduce Spark-TTS, a novel system powered by BiCodec, a single-stream speech codec that decomposes speech into two complementary token types: low-bitrate semantic tokens for linguistic content and fixed-length global tokens for speaker attributes. This disentangled representation, combined with the Qwen2.5 LLM and a chain-of-thought (CoT) generation approach, enables both coarse-grained control (e.g., gender, speaking style) and fine-grained adjustments (e.g., precise pitch values, speaking rate). To facilitate research in controllable TTS, we introduce VoxBox, a meticulously curated 100,000-hour dataset with comprehensive attribute annotations. Extensive experiments demonstrate that Spark-TTS not only achieves state-of-the-art zero-shot voice cloning but also generates highly customizable voices that surpass the limitations of reference-based synthesis. Source code, pre-trained models, and audio samples are available at https://github.com/SparkAudio/Spark-TTS.
CogSimulator: A Model for Simulating User Cognition & Behavior with Minimal Data for Tailored Cognitive Enhancement
Dec 10, 2024The interplay between cognition and gaming, notably through educational games enhancing cognitive skills, has garnered significant attention in recent years. This research introduces the CogSimulator, a novel algorithm for simulating user cognition in small-group settings with minimal data, as the educational game Wordle exemplifies. The CogSimulator employs Wasserstein-1 distance and coordinates search optimization for hyperparameter tuning, enabling precise few-shot predictions in new game scenarios. Comparative experiments with the Wordle dataset illustrate that our model surpasses most conventional machine learning models in mean Wasserstein-1 distance, mean squared error, and mean accuracy, showcasing its efficacy in cognitive enhancement through tailored game design.
IntellectSeeker: A Personalized Literature Management System with the Probabilistic Model and Large Language Model
Dec 10, 2024Faced with the burgeoning volume of academic literature, researchers often need help with uncertain article quality and mismatches in term searches using traditional academic engines. We introduce IntellectSeeker, an innovative and personalized intelligent academic literature management platform to address these challenges. This platform integrates a Large Language Model (LLM)--based semantic enhancement bot with a sophisticated probability model to personalize and streamline literature searches. We adopted the GPT-3.5-turbo model to transform everyday language into professional academic terms across various scenarios using multiple rounds of few-shot learning. This adaptation mainly benefits academic newcomers, effectively bridging the gap between general inquiries and academic terminology. The probabilistic model intelligently filters academic articles to align closely with the specific interests of users, which are derived from explicit needs and behavioral patterns. Moreover, IntellectSeeker incorporates an advanced recommendation system and text compression tools. These features enable intelligent article recommendations based on user interactions and present search results through concise one-line summaries and innovative word cloud visualizations, significantly enhancing research efficiency and user experience. IntellectSeeker offers academic researchers a highly customizable literature management solution with exceptional search precision and matching capabilities. The code can be found here: https://github.com/LuckyBian/ISY5001
Advancing Music Therapy: Integrating Eastern Five-Element Music Theory and Western Techniques with AI in the Novel Five-Element Harmony System
Dec 09, 2024

In traditional medical practices, music therapy has proven effective in treating various psychological and physiological ailments. Particularly in Eastern traditions, the Five Elements Music Therapy (FEMT), rooted in traditional Chinese medicine, possesses profound cultural significance and unique therapeutic philosophies. With the rapid advancement of Information Technology and Artificial Intelligence, applying these modern technologies to FEMT could enhance the personalization and cultural relevance of the therapy and potentially improve therapeutic outcomes. In this article, we developed a music therapy system for the first time by applying the theory of the five elements in music therapy to practice. This innovative approach integrates advanced Information Technology and Artificial Intelligence with Five-Element Music Therapy (FEMT) to enhance personalized music therapy practices. As traditional music therapy predominantly follows Western methodologies, the unique aspects of Eastern practices, specifically the Five-Element theory from traditional Chinese medicine, should be considered. This system aims to bridge this gap by utilizing computational technologies to provide a more personalized, culturally relevant, and therapeutically effective music therapy experience.
EmoSpeech: A Corpus of Emotionally Rich and Contextually Detailed Speech Annotations
Dec 09, 2024Advances in text-to-speech (TTS) technology have significantly improved the quality of generated speech, closely matching the timbre and intonation of the target speaker. However, due to the inherent complexity of human emotional expression, the development of TTS systems capable of controlling subtle emotional differences remains a formidable challenge. Existing emotional speech databases often suffer from overly simplistic labelling schemes that fail to capture a wide range of emotional states, thus limiting the effectiveness of emotion synthesis in TTS applications. To this end, recent efforts have focussed on building databases that use natural language annotations to describe speech emotions. However, these approaches are costly and require more emotional depth to train robust systems. In this paper, we propose a novel process aimed at building databases by systematically extracting emotion-rich speech segments and annotating them with detailed natural language descriptions through a generative model. This approach enhances the emotional granularity of the database and significantly reduces the reliance on costly manual annotations by automatically augmenting the data with high-level language models. The resulting rich database provides a scalable and economically viable solution for developing a more nuanced and dynamic basis for developing emotionally controlled TTS systems.
FlashSpeech: Efficient Zero-Shot Speech Synthesis
Apr 25, 2024



Recent progress in large-scale zero-shot speech synthesis has been significantly advanced by language models and diffusion models. However, the generation process of both methods is slow and computationally intensive. Efficient speech synthesis using a lower computing budget to achieve quality on par with previous work remains a significant challenge. In this paper, we present FlashSpeech, a large-scale zero-shot speech synthesis system with approximately 5\% of the inference time compared with previous work. FlashSpeech is built on the latent consistency model and applies a novel adversarial consistency training approach that can train from scratch without the need for a pre-trained diffusion model as the teacher. Furthermore, a new prosody generator module enhances the diversity of prosody, making the rhythm of the speech sound more natural. The generation processes of FlashSpeech can be achieved efficiently with one or two sampling steps while maintaining high audio quality and high similarity to the audio prompt for zero-shot speech generation. Our experimental results demonstrate the superior performance of FlashSpeech. Notably, FlashSpeech can be about 20 times faster than other zero-shot speech synthesis systems while maintaining comparable performance in terms of voice quality and similarity. Furthermore, FlashSpeech demonstrates its versatility by efficiently performing tasks like voice conversion, speech editing, and diverse speech sampling. Audio samples can be found in https://flashspeech.github.io/.