 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFin-R1: A Large Language Model for Financial Reasoning through Reinforcement Learning
Mar 21, 2025



Reasoning large language models are rapidly evolving across various domains. However, their capabilities in handling complex financial tasks still require in-depth exploration. In this paper, we introduce Fin-R1, a reasoning large language model specifically designed for the financial sector. Fin-R1 is built using a two-stage architecture, leveraging a financial reasoning dataset distilled and processed based on DeepSeek-R1. Through supervised fine-tuning (SFT) and reinforcement learning (RL) training, it demonstrates performance close to DeepSeek-R1 with a parameter size of 7 billion across a range of financial reasoning tasks. It achieves the state-of-the-art (SOTA) in the FinQA and ConvFinQA tasks between those LLMs in our evaluation, surpassing larger models in other tasks as well. Fin-R1 showcases strong reasoning and decision-making capabilities, providing solutions to various problems encountered in the financial domain. Our code is available at https://github.com/SUFE-AIFLM-Lab/Fin-R1.
IntellectSeeker: A Personalized Literature Management System with the Probabilistic Model and Large Language Model
Dec 10, 2024Faced with the burgeoning volume of academic literature, researchers often need help with uncertain article quality and mismatches in term searches using traditional academic engines. We introduce IntellectSeeker, an innovative and personalized intelligent academic literature management platform to address these challenges. This platform integrates a Large Language Model (LLM)--based semantic enhancement bot with a sophisticated probability model to personalize and streamline literature searches. We adopted the GPT-3.5-turbo model to transform everyday language into professional academic terms across various scenarios using multiple rounds of few-shot learning. This adaptation mainly benefits academic newcomers, effectively bridging the gap between general inquiries and academic terminology. The probabilistic model intelligently filters academic articles to align closely with the specific interests of users, which are derived from explicit needs and behavioral patterns. Moreover, IntellectSeeker incorporates an advanced recommendation system and text compression tools. These features enable intelligent article recommendations based on user interactions and present search results through concise one-line summaries and innovative word cloud visualizations, significantly enhancing research efficiency and user experience. IntellectSeeker offers academic researchers a highly customizable literature management solution with exceptional search precision and matching capabilities. The code can be found here: https://github.com/LuckyBian/ISY5001
Adaptive DNN Surgery for Selfish Inference Acceleration with On-demand Edge Resource
Jun 21, 2023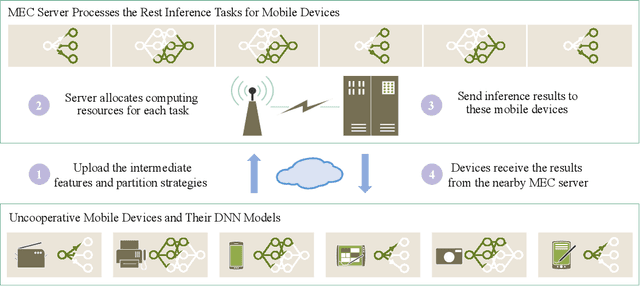
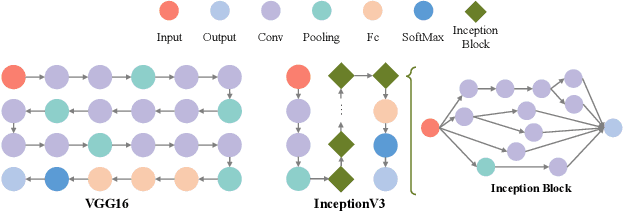
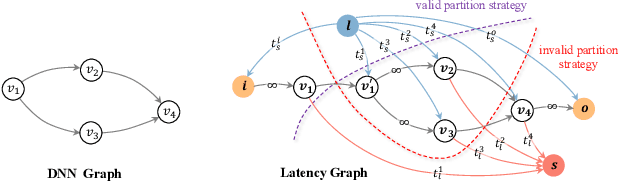
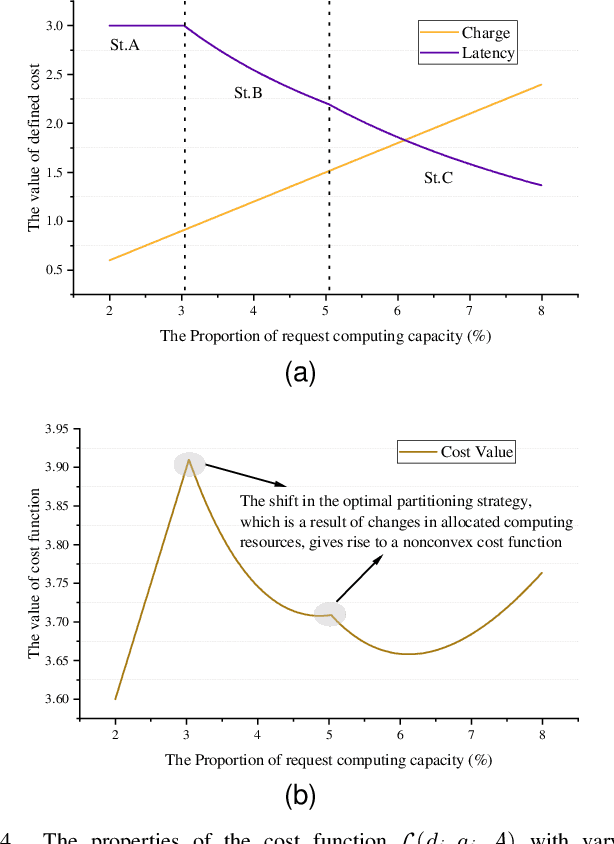
Deep Neural Networks (DNNs) have significantly improved the accuracy of intelligent applications on mobile devices. DNN surgery, which partitions DNN processing between mobile devices and multi-access edge computing (MEC) servers, can enable real-time inference despite the computational limitations of mobile devices. However, DNN surgery faces a critical challenge: determining the optimal computing resource demand from the server and the corresponding partition strategy, while considering both inference latency and MEC server usage costs. This problem is compounded by two factors: (1) the finite computing capacity of the MEC server, which is shared among multiple devices, leading to inter-dependent demands, and (2) the shift in modern DNN architecture from chains to directed acyclic graphs (DAGs), which complicates potential solutions. In this paper, we introduce a novel Decentralized DNN Surgery (DDS) framework. We formulate the partition strategy as a min-cut and propose a resource allocation game to adaptively schedule the demands of mobile devices in an MEC environment. We prove the existence of a Nash Equilibrium (NE), and develop an iterative algorithm to efficiently reach the NE for each device. Our extensive experiments demonstrate that DDS can effectively handle varying MEC scenarios, achieving up to 1.25$\times$ acceleration compared to the state-of-the-art algorithm.