 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemiparametric Learning from Open-Set Label Shift Data
Sep 18, 2025We study the open-set label shift problem, where the test data may include a novel class absent from training. This setting is challenging because both the class proportions and the distribution of the novel class are not identifiable without extra assumptions. Existing approaches often rely on restrictive separability conditions, prior knowledge, or computationally infeasible procedures, and some may lack theoretical guarantees. We propose a semiparametric density ratio model framework that ensures identifiability while allowing overlap between novel and known classes. Within this framework, we develop maximum empirical likelihood estimators and confidence intervals for class proportions, establish their asymptotic validity, and design a stable Expectation-Maximization algorithm for computation. We further construct an approximately optimal classifier based on posterior probabilities with theoretical guarantees. Simulations and a real data application confirm that our methods improve both estimation accuracy and classification performance compared with existing approaches.
MedRAG: Enhancing Retrieval-augmented Generation with Knowledge Graph-Elicited Reasoning for Healthcare Copilot
Feb 06, 2025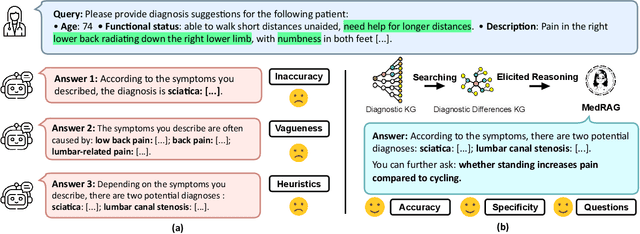

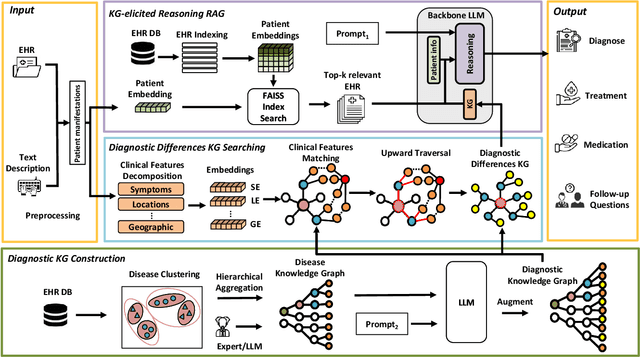

Retrieval-augmented generation (RAG) is a well-suited technique for retrieving privacy-sensitive Electronic Health Records (EHR). It can serve as a key module of the healthcare copilot, helping reduce misdiagnosis for healthcare practitioners and patients. However, the diagnostic accuracy and specificity of existing heuristic-based RAG models used in the medical domain are inadequate, particularly for diseases with similar manifestations. This paper proposes MedRAG, a RAG model enhanced by knowledge graph (KG)-elicited reasoning for the medical domain that retrieves diagnosis and treatment recommendations based on manifestations. MedRAG systematically constructs a comprehensive four-tier hierarchical diagnostic KG encompassing critical diagnostic differences of various diseases. These differences are dynamically integrated with similar EHRs retrieved from an EHR database, and reasoned within a large language model. This process enables more accurate and specific decision support, while also proactively providing follow-up questions to enhance personalized medical decision-making. MedRAG is evaluated on both a public dataset DDXPlus and a private chronic pain diagnostic dataset (CPDD) collected from Tan Tock Seng Hospital, and its performance is compared against various existing RAG methods. Experimental results show that, leveraging the information integration and relational abilities of the KG, our MedRAG provides more specific diagnostic insights and outperforms state-of-the-art models in reducing misdiagnosis rates. Our code will be available at https://github.com/SNOWTEAM2023/MedRAG
CogSimulator: A Model for Simulating User Cognition & Behavior with Minimal Data for Tailored Cognitive Enhancement
Dec 10, 2024The interplay between cognition and gaming, notably through educational games enhancing cognitive skills, has garnered significant attention in recent years. This research introduces the CogSimulator, a novel algorithm for simulating user cognition in small-group settings with minimal data, as the educational game Wordle exemplifies. The CogSimulator employs Wasserstein-1 distance and coordinates search optimization for hyperparameter tuning, enabling precise few-shot predictions in new game scenarios. Comparative experiments with the Wordle dataset illustrate that our model surpasses most conventional machine learning models in mean Wasserstein-1 distance, mean squared error, and mean accuracy, showcasing its efficacy in cognitive enhancement through tailored game design.
IntellectSeeker: A Personalized Literature Management System with the Probabilistic Model and Large Language Model
Dec 10, 2024Faced with the burgeoning volume of academic literature, researchers often need help with uncertain article quality and mismatches in term searches using traditional academic engines. We introduce IntellectSeeker, an innovative and personalized intelligent academic literature management platform to address these challenges. This platform integrates a Large Language Model (LLM)--based semantic enhancement bot with a sophisticated probability model to personalize and streamline literature searches. We adopted the GPT-3.5-turbo model to transform everyday language into professional academic terms across various scenarios using multiple rounds of few-shot learning. This adaptation mainly benefits academic newcomers, effectively bridging the gap between general inquiries and academic terminology. The probabilistic model intelligently filters academic articles to align closely with the specific interests of users, which are derived from explicit needs and behavioral patterns. Moreover, IntellectSeeker incorporates an advanced recommendation system and text compression tools. These features enable intelligent article recommendations based on user interactions and present search results through concise one-line summaries and innovative word cloud visualizations, significantly enhancing research efficiency and user experience. IntellectSeeker offers academic researchers a highly customizable literature management solution with exceptional search precision and matching capabilities. The code can be found here: https://github.com/LuckyBian/ISY5001
A Scalable Real-Time Data Assimilation Framework for Predicting Turbulent Atmosphere Dynamics
Jul 16, 2024



The weather and climate domains are undergoing a significant transformation thanks to advances in AI-based foundation models such as FourCastNet, GraphCast, ClimaX and Pangu-Weather. While these models show considerable potential, they are not ready yet for operational use in weather forecasting or climate prediction. This is due to the lack of a data assimilation method as part of their workflow to enable the assimilation of incoming Earth system observations in real time. This limitation affects their effectiveness in predicting complex atmospheric phenomena such as tropical cyclones and atmospheric rivers. To overcome these obstacles, we introduce a generic real-time data assimilation framework and demonstrate its end-to-end performance on the Frontier supercomputer. This framework comprises two primary modules: an ensemble score filter (EnSF), which significantly outperforms the state-of-the-art data assimilation method, namely, the Local Ensemble Transform Kalman Filter (LETKF); and a vision transformer-based surrogate capable of real-time adaptation through the integration of observational data. The ViT surrogate can represent either physics-based models or AI-based foundation models. We demonstrate both the strong and weak scaling of our framework up to 1024 GPUs on the Exascale supercomputer, Frontier. Our results not only illustrate the framework's exceptional scalability on high-performance computing systems, but also demonstrate the importance of supercomputers in real-time data assimilation for weather and climate predictions. Even though the proposed framework is tested only on a benchmark surface quasi-geostrophic (SQG) turbulence system, it has the potential to be combined with existing AI-based foundation models, making it suitable for future operational implementations.
Positive and Unlabeled Data: Model, Estimation, Inference, and Classification
Jul 13, 2024



This study introduces a new approach to addressing positive and unlabeled (PU) data through the double exponential tilting model (DETM). Traditional methods often fall short because they only apply to selected completely at random (SCAR) PU data, where the labeled positive and unlabeled positive data are assumed to be from the same distribution. In contrast, our DETM's dual structure effectively accommodates the more complex and underexplored selected at random PU data, where the labeled and unlabeled positive data can be from different distributions. We rigorously establish the theoretical foundations of DETM, including identifiability, parameter estimation, and asymptotic properties. Additionally, we move forward to statistical inference by developing a goodness-of-fit test for the SCAR condition and constructing confidence intervals for the proportion of positive instances in the target domain. We leverage an approximated Bayes classifier for classification tasks, demonstrating DETM's robust performance in prediction. Through theoretical insights and practical applications, this study highlights DETM as a comprehensive framework for addressing the challenges of PU data.
ORBIT: Oak Ridge Base Foundation Model for Earth System Predictability
Apr 23, 2024Earth system predictability is challenged by the complexity of environmental dynamics and the multitude of variables involved. Current AI foundation models, although advanced by leveraging large and heterogeneous data, are often constrained by their size and data integration, limiting their effectiveness in addressing the full range of Earth system prediction challenges. To overcome these limitations, we introduce the Oak Ridge Base Foundation Model for Earth System Predictability (ORBIT), an advanced vision-transformer model that scales up to 113 billion parameters using a novel hybrid tensor-data orthogonal parallelism technique. As the largest model of its kind, ORBIT surpasses the current climate AI foundation model size by a thousandfold. Performance scaling tests conducted on the Frontier supercomputer have demonstrated that ORBIT achieves 230 to 707 PFLOPS, with scaling efficiency maintained at 78% to 96% across 24,576 AMD GPUs. These breakthroughs establish new advances in AI-driven climate modeling and demonstrate promise to significantly improve the Earth system predictability.
DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies
Oct 11, 2023



In the upcoming decade, deep learning may revolutionize the natural sciences, enhancing our capacity to model and predict natural occurrences. This could herald a new era of scientific exploration, bringing significant advancements across sectors from drug development to renewable energy. To answer this call, we present DeepSpeed4Science initiative (deepspeed4science.ai) which aims to build unique capabilities through AI system technology innovations to help domain experts to unlock today's biggest science mysteries. By leveraging DeepSpeed's current technology pillars (training, inference and compression) as base technology enablers, DeepSpeed4Science will create a new set of AI system technologies tailored for accelerating scientific discoveries by addressing their unique complexity beyond the common technical approaches used for accelerating generic large language models (LLMs). In this paper, we showcase the early progress we made with DeepSpeed4Science in addressing two of the critical system challenges in structural biology research.
PI3NN: Prediction intervals from three independently trained neural networks
Aug 05, 2021

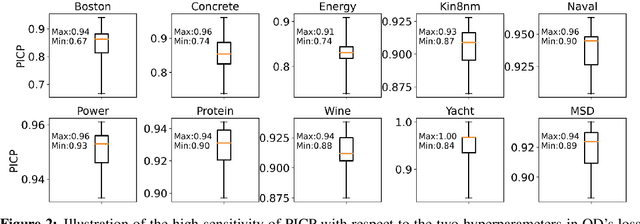
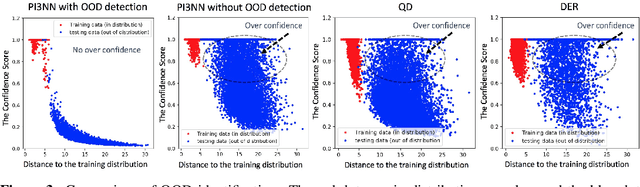
We propose a novel prediction interval method to learn prediction mean values, lower and upper bounds of prediction intervals from three independently trained neural networks only using the standard mean squared error (MSE) loss, for uncertainty quantification in regression tasks. Our method requires no distributional assumption on data, does not introduce unusual hyperparameters to either the neural network models or the loss function. Moreover, our method can effectively identify out-of-distribution samples and reasonably quantify their uncertainty. Numerical experiments on benchmark regression problems show that our method outperforms the state-of-the-art methods with respect to predictive uncertainty quality, robustness, and identification of out-of-distribution samples.