 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Adaptive Humanoid Control via Multi-Behavior Distillation and Reinforced Fine-Tuning
Nov 11, 2025Humanoid robots are promising to learn a diverse set of human-like locomotion behaviors, including standing up, walking, running, and jumping. However, existing methods predominantly require training independent policies for each skill, yielding behavior-specific controllers that exhibit limited generalization and brittle performance when deployed on irregular terrains and in diverse situations. To address this challenge, we propose Adaptive Humanoid Control (AHC) that adopts a two-stage framework to learn an adaptive humanoid locomotion controller across different skills and terrains. Specifically, we first train several primary locomotion policies and perform a multi-behavior distillation process to obtain a basic multi-behavior controller, facilitating adaptive behavior switching based on the environment. Then, we perform reinforced fine-tuning by collecting online feedback in performing adaptive behaviors on more diverse terrains, enhancing terrain adaptability for the controller. We conduct experiments in both simulation and real-world experiments in Unitree G1 robots. The results show that our method exhibits strong adaptability across various situations and terrains. Project website: https://ahc-humanoid.github.io.
Adaptive Graph Learning with Transformer for Multi-Reservoir Inflow Prediction
Nov 10, 2025Reservoir inflow prediction is crucial for water resource management, yet existing approaches mainly focus on single-reservoir models that ignore spatial dependencies among interconnected reservoirs. We introduce AdaTrip as an adaptive, time-varying graph learning framework for multi-reservoir inflow forecasting. AdaTrip constructs dynamic graphs where reservoirs are nodes with directed edges reflecting hydrological connections, employing attention mechanisms to automatically identify crucial spatial and temporal dependencies. Evaluation on thirty reservoirs in the Upper Colorado River Basin demonstrates superiority over existing baselines, with improved performance for reservoirs with limited records through parameter sharing. Additionally, AdaTrip provides interpretable attention maps at edge and time-step levels, offering insights into hydrological controls to support operational decision-making. Our code is available at https://github.com/humphreyhuu/AdaTrip.
Decoding Memories: An Efficient Pipeline for Self-Consistency Hallucination Detection
Aug 28, 2025Large language models (LLMs) have demonstrated impressive performance in both research and real-world applications, but they still struggle with hallucination. Existing hallucination detection methods often perform poorly on sentence-level generation or rely heavily on domain-specific knowledge. While self-consistency approaches help address these limitations, they incur high computational costs due to repeated generation. In this paper, we conduct the first study on identifying redundancy in self-consistency methods, manifested as shared prefix tokens across generations, and observe that non-exact-answer tokens contribute minimally to the semantic content. Based on these insights, we propose a novel Decoding Memory Pipeline (DMP) that accelerates generation through selective inference and annealed decoding. Being orthogonal to the model, dataset, decoding strategy, and self-consistency baseline, our DMP consistently improves the efficiency of multi-response generation and holds promise for extension to alignment and reasoning tasks. Extensive experiments show that our method achieves up to a 3x speedup without sacrificing AUROC performance.
Distributed Cross-Channel Hierarchical Aggregation for Foundation Models
Jun 26, 2025Vision-based scientific foundation models hold significant promise for advancing scientific discovery and innovation. This potential stems from their ability to aggregate images from diverse sources such as varying physical groundings or data acquisition systems and to learn spatio-temporal correlations using transformer architectures. However, tokenizing and aggregating images can be compute-intensive, a challenge not fully addressed by current distributed methods. In this work, we introduce the Distributed Cross-Channel Hierarchical Aggregation (D-CHAG) approach designed for datasets with a large number of channels across image modalities. Our method is compatible with any model-parallel strategy and any type of vision transformer architecture, significantly improving computational efficiency. We evaluated D-CHAG on hyperspectral imaging and weather forecasting tasks. When integrated with tensor parallelism and model sharding, our approach achieved up to a 75% reduction in memory usage and more than doubled sustained throughput on up to 1,024 AMD GPUs on the Frontier Supercomputer.
ORBIT-2: Scaling Exascale Vision Foundation Models for Weather and Climate Downscaling
May 07, 2025



Sparse observations and coarse-resolution climate models limit effective regional decision-making, underscoring the need for robust downscaling. However, existing AI methods struggle with generalization across variables and geographies and are constrained by the quadratic complexity of Vision Transformer (ViT) self-attention. We introduce ORBIT-2, a scalable foundation model for global, hyper-resolution climate downscaling. ORBIT-2 incorporates two key innovations: (1) Residual Slim ViT (Reslim), a lightweight architecture with residual learning and Bayesian regularization for efficient, robust prediction; and (2) TILES, a tile-wise sequence scaling algorithm that reduces self-attention complexity from quadratic to linear, enabling long-sequence processing and massive parallelism. ORBIT-2 scales to 10 billion parameters across 32,768 GPUs, achieving up to 1.8 ExaFLOPS sustained throughput and 92-98% strong scaling efficiency. It supports downscaling to 0.9 km global resolution and processes sequences up to 4.2 billion tokens. On 7 km resolution benchmarks, ORBIT-2 achieves high accuracy with R^2 scores in the range of 0.98 to 0.99 against observation data.
GenAI4UQ: A Software for Inverse Uncertainty Quantification Using Conditional Generative Models
Dec 09, 2024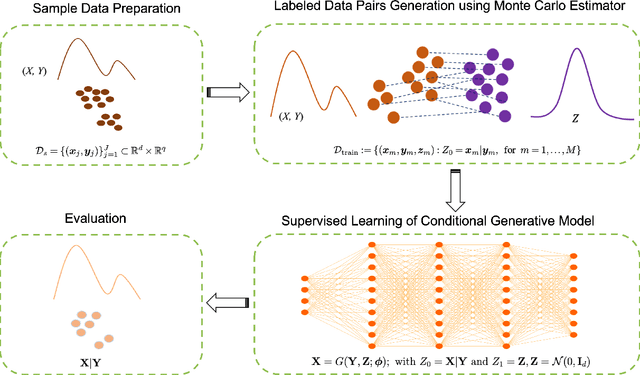
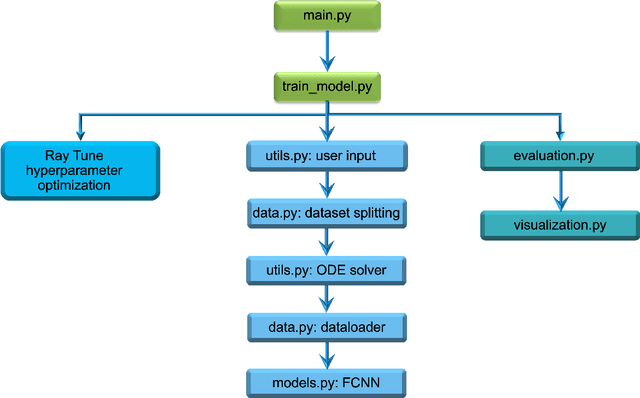
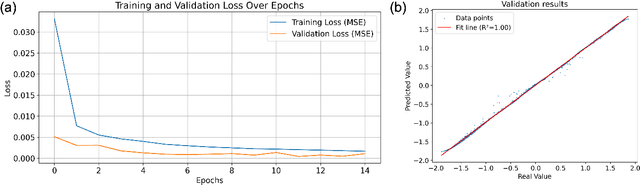

We introduce GenAI4UQ, a software package for inverse uncertainty quantification in model calibration, parameter estimation, and ensemble forecasting in scientific applications. GenAI4UQ leverages a generative artificial intelligence (AI) based conditional modeling framework to address the limitations of traditional inverse modeling techniques, such as Markov Chain Monte Carlo methods. By replacing computationally intensive iterative processes with a direct, learned mapping, GenAI4UQ enables efficient calibration of model input parameters and generation of output predictions directly from observations. The software's design allows for rapid ensemble forecasting with robust uncertainty quantification, while maintaining high computational and storage efficiency. GenAI4UQ simplifies the model training process through built-in auto-tuning of hyperparameters, making it accessible to users with varying levels of expertise. Its conditional generative framework ensures versatility, enabling applicability across a wide range of scientific domains. At its core, GenAI4UQ transforms the paradigm of inverse modeling by providing a fast, reliable, and user-friendly solution. It empowers researchers and practitioners to quickly estimate parameter distributions and generate model predictions for new observations, facilitating efficient decision-making and advancing the state of uncertainty quantification in computational modeling. (The code and data are available at https://github.com/patrickfan/GenAI4UQ).
Recommendations for Comprehensive and Independent Evaluation of Machine Learning-Based Earth System Models
Oct 24, 2024Machine learning (ML) is a revolutionary technology with demonstrable applications across multiple disciplines. Within the Earth science community, ML has been most visible for weather forecasting, producing forecasts that rival modern physics-based models. Given the importance of deepening our understanding and improving predictions of the Earth system on all time scales, efforts are now underway to develop forecasting models into Earth-system models (ESMs), capable of representing all components of the coupled Earth system (or their aggregated behavior) and their response to external changes. Modeling the Earth system is a much more difficult problem than weather forecasting, not least because the model must represent the alternate (e.g., future) coupled states of the system for which there are no historical observations. Given that the physical principles that enable predictions about the response of the Earth system are often not explicitly coded in these ML-based models, demonstrating the credibility of ML-based ESMs thus requires us to build evidence of their consistency with the physical system. To this end, this paper puts forward five recommendations to enhance comprehensive, standardized, and independent evaluation of ML-based ESMs to strengthen their credibility and promote their wider use.
ExoTST: Exogenous-Aware Temporal Sequence Transformer for Time Series Prediction
Oct 16, 2024



Accurate long-term predictions are the foundations for many machine learning applications and decision-making processes. Traditional time series approaches for prediction often focus on either autoregressive modeling, which relies solely on past observations of the target ``endogenous variables'', or forward modeling, which considers only current covariate drivers ``exogenous variables''. However, effectively integrating past endogenous and past exogenous with current exogenous variables remains a significant challenge. In this paper, we propose ExoTST, a novel transformer-based framework that effectively incorporates current exogenous variables alongside past context for improved time series prediction. To integrate exogenous information efficiently, ExoTST leverages the strengths of attention mechanisms and introduces a novel cross-temporal modality fusion module. This module enables the model to jointly learn from both past and current exogenous series, treating them as distinct modalities. By considering these series separately, ExoTST provides robustness and flexibility in handling data uncertainties that arise from the inherent distribution shift between historical and current exogenous variables. Extensive experiments on real-world carbon flux datasets and time series benchmarks demonstrate ExoTST's superior performance compared to state-of-the-art baselines, with improvements of up to 10\% in prediction accuracy. Moreover, ExoTST exhibits strong robustness against missing values and noise in exogenous drivers, maintaining consistent performance in real-world situations where these imperfections are common.
A Scalable Real-Time Data Assimilation Framework for Predicting Turbulent Atmosphere Dynamics
Jul 16, 2024



The weather and climate domains are undergoing a significant transformation thanks to advances in AI-based foundation models such as FourCastNet, GraphCast, ClimaX and Pangu-Weather. While these models show considerable potential, they are not ready yet for operational use in weather forecasting or climate prediction. This is due to the lack of a data assimilation method as part of their workflow to enable the assimilation of incoming Earth system observations in real time. This limitation affects their effectiveness in predicting complex atmospheric phenomena such as tropical cyclones and atmospheric rivers. To overcome these obstacles, we introduce a generic real-time data assimilation framework and demonstrate its end-to-end performance on the Frontier supercomputer. This framework comprises two primary modules: an ensemble score filter (EnSF), which significantly outperforms the state-of-the-art data assimilation method, namely, the Local Ensemble Transform Kalman Filter (LETKF); and a vision transformer-based surrogate capable of real-time adaptation through the integration of observational data. The ViT surrogate can represent either physics-based models or AI-based foundation models. We demonstrate both the strong and weak scaling of our framework up to 1024 GPUs on the Exascale supercomputer, Frontier. Our results not only illustrate the framework's exceptional scalability on high-performance computing systems, but also demonstrate the importance of supercomputers in real-time data assimilation for weather and climate predictions. Even though the proposed framework is tested only on a benchmark surface quasi-geostrophic (SQG) turbulence system, it has the potential to be combined with existing AI-based foundation models, making it suitable for future operational implementations.
ORBIT: Oak Ridge Base Foundation Model for Earth System Predictability
Apr 23, 2024Earth system predictability is challenged by the complexity of environmental dynamics and the multitude of variables involved. Current AI foundation models, although advanced by leveraging large and heterogeneous data, are often constrained by their size and data integration, limiting their effectiveness in addressing the full range of Earth system prediction challenges. To overcome these limitations, we introduce the Oak Ridge Base Foundation Model for Earth System Predictability (ORBIT), an advanced vision-transformer model that scales up to 113 billion parameters using a novel hybrid tensor-data orthogonal parallelism technique. As the largest model of its kind, ORBIT surpasses the current climate AI foundation model size by a thousandfold. Performance scaling tests conducted on the Frontier supercomputer have demonstrated that ORBIT achieves 230 to 707 PFLOPS, with scaling efficiency maintained at 78% to 96% across 24,576 AMD GPUs. These breakthroughs establish new advances in AI-driven climate modeling and demonstrate promise to significantly improve the Earth system predictability.