 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric GNNs for Charged Particle Tracking at GlueX
May 28, 2025Nuclear physics experiments are aimed at uncovering the fundamental building blocks of matter. The experiments involve high-energy collisions that produce complex events with many particle trajectories. Tracking charged particles resulting from collisions in the presence of a strong magnetic field is critical to enable the reconstruction of particle trajectories and precise determination of interactions. It is traditionally achieved through combinatorial approaches that scale worse than linearly as the number of hits grows. Since particle hit data naturally form a 3-dimensional point cloud and can be structured as graphs, Graph Neural Networks (GNNs) emerge as an intuitive and effective choice for this task. In this study, we evaluate the GNN model for track finding on the data from the GlueX experiment at Jefferson Lab. We use simulation data to train the model and test on both simulation and real GlueX measurements. We demonstrate that GNN-based track finding outperforms the currently used traditional method at GlueX in terms of segment-based efficiency at a fixed purity while providing faster inferences. We show that the GNN model can achieve significant speedup by processing multiple events in batches, which exploits the parallel computation capability of Graphical Processing Units (GPUs). Finally, we compare the GNN implementation on GPU and FPGA and describe the trade-off.
Outlook Towards Deployable Continual Learning for Particle Accelerators
Apr 04, 2025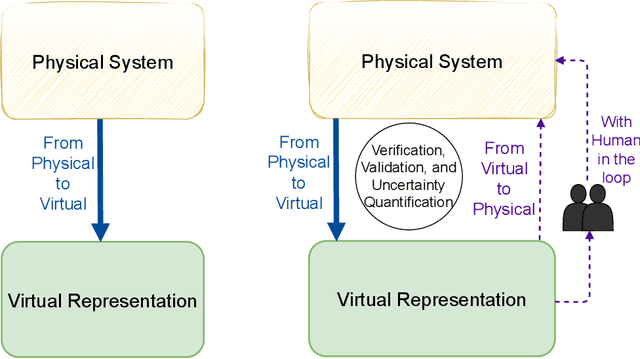
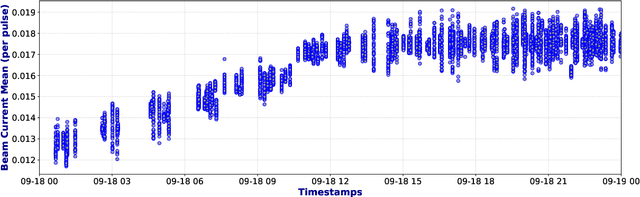
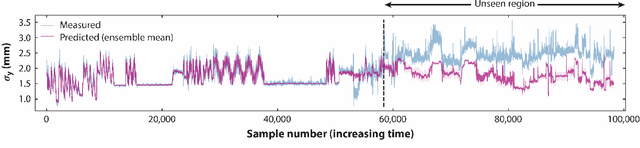
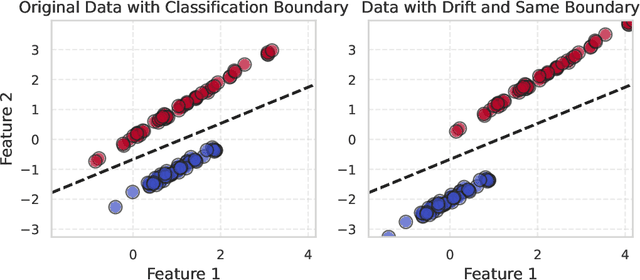
Particle Accelerators are high power complex machines. To ensure uninterrupted operation of these machines, thousands of pieces of equipment need to be synchronized, which requires addressing many challenges including design, optimization and control, anomaly detection and machine protection. With recent advancements, Machine Learning (ML) holds promise to assist in more advance prognostics, optimization, and control. While ML based solutions have been developed for several applications in particle accelerators, only few have reached deployment and even fewer to long term usage, due to particle accelerator data distribution drifts caused by changes in both measurable and non-measurable parameters. In this paper, we identify some of the key areas within particle accelerators where continual learning can allow maintenance of ML model performance with distribution drifts. Particularly, we first discuss existing applications of ML in particle accelerators, and their limitations due to distribution drift. Next, we review existing continual learning techniques and investigate their potential applications to address data distribution drifts in accelerators. By identifying the opportunities and challenges in applying continual learning, this paper seeks to open up the new field and inspire more research efforts towards deployable continual learning for particle accelerators.
Harnessing the Power of Gradient-Based Simulations for Multi-Objective Optimization in Particle Accelerators
Nov 07, 2024


Particle accelerator operation requires simultaneous optimization of multiple objectives. Multi-Objective Optimization (MOO) is particularly challenging due to trade-offs between the objectives. Evolutionary algorithms, such as genetic algorithm (GA), have been leveraged for many optimization problems, however, they do not apply to complex control problems by design. This paper demonstrates the power of differentiability for solving MOO problems using a Deep Differentiable Reinforcement Learning (DDRL) algorithm in particle accelerators. We compare DDRL algorithm with Model Free Reinforcement Learning (MFRL), GA and Bayesian Optimization (BO) for simultaneous optimization of heat load and trip rates in the Continuous Electron Beam Accelerator Facility (CEBAF). The underlying problem enforces strict constraints on both individual states and actions as well as cumulative (global) constraint for energy requirements of the beam. A physics-based surrogate model based on real data is developed. This surrogate model is differentiable and allows back-propagation of gradients. The results are evaluated in the form of a Pareto-front for two objectives. We show that the DDRL outperforms MFRL, BO, and GA on high dimensional problems.
Hydra: Computer Vision for Data Quality Monitoring
Mar 01, 2024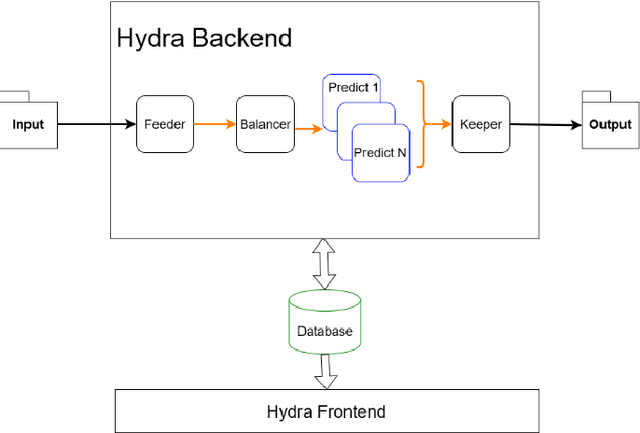
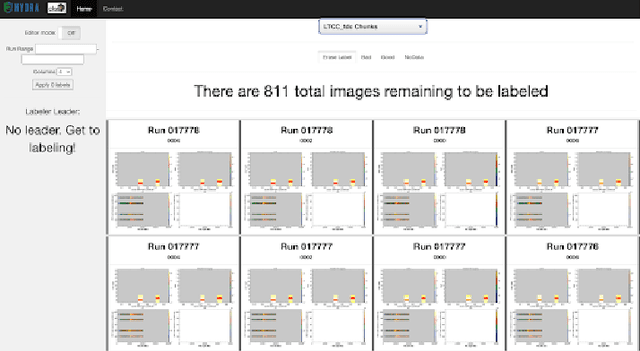
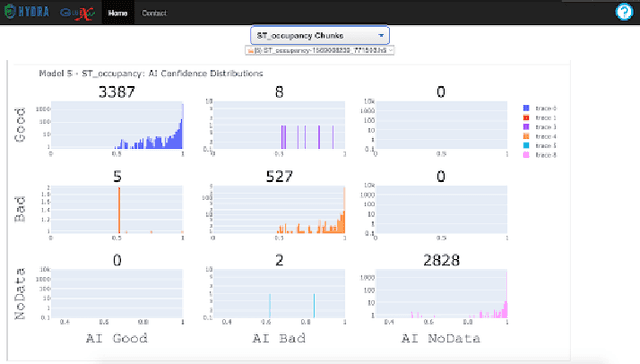
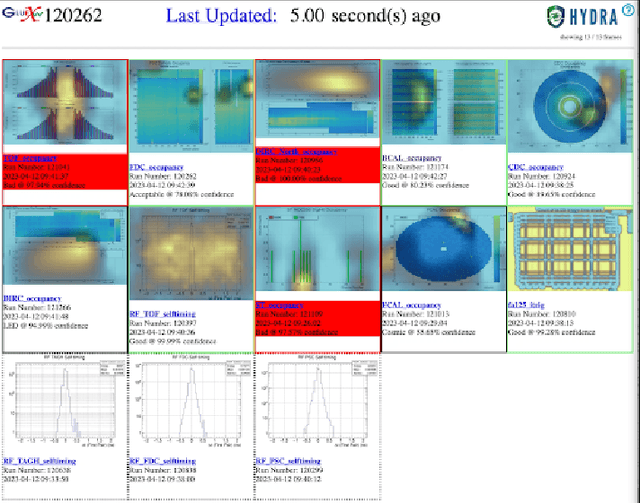
Hydra is a system which utilizes computer vision to perform near real time data quality management, initially developed for Hall-D in 2019. Since then, it has been deployed across all experimental halls at Jefferson Lab, with the CLAS12 collaboration in Hall-B being the first outside of GlueX to fully utilize Hydra. The system comprises back end processes that manage the models, their inferences, and the data flow. The front-end components, accessible via web pages, allow detector experts and shift crews to view and interact with the system. This talk will give an overview of the Hydra system as well as highlight significant developments in Hydra's feature set, acute challenges with operating Hydra in all halls, and lessons learned along the way.
Evaluating DTW Measures via a Synthesis Framework for Time-Series Data
Feb 14, 2024



Time-series data originate from various applications that describe specific observations or quantities of interest over time. Their analysis often involves the comparison across different time-series data sequences, which in turn requires the alignment of these sequences. Dynamic Time Warping (DTW) is the standard approach to achieve an optimal alignment between two temporal signals. Different variations of DTW have been proposed to address various needs for signal alignment or classifications. However, a comprehensive evaluation of their performance in these time-series data processing tasks is lacking. Most DTW measures perform well on certain types of time-series data without a clear explanation of the reason. To address that, we propose a synthesis framework to model the variation between two time-series data sequences for comparison. Our synthesis framework can produce a realistic initial signal and deform it with controllable variations that mimic real-world scenarios. With this synthesis framework, we produce a large number of time-series sequence pairs with different but known variations, which are used to assess the performance of a number of well-known DTW measures for the tasks of alignment and classification. We report their performance on different variations and suggest the proper DTW measure to use based on the type of variations between two time-series sequences. This is the first time such a guideline is presented for selecting a proper DTW measure. To validate our conclusion, we apply our findings to real-world applications, i.e., the detection of the formation top for the oil and gas industry and the pattern search in streamlines for flow visualization.
Uncertainty Aware Deep Learning for Particle Accelerators
Sep 25, 2023

Standard deep learning models for classification and regression applications are ideal for capturing complex system dynamics. However, their predictions can be arbitrarily inaccurate when the input samples are not similar to the training data. Implementation of distance aware uncertainty estimation can be used to detect these scenarios and provide a level of confidence associated with their predictions. In this paper, we present results from using Deep Gaussian Process Approximation (DGPA) methods for errant beam prediction at Spallation Neutron Source (SNS) accelerator (classification) and we provide an uncertainty aware surrogate model for the Fermi National Accelerator Lab (FNAL) Booster Accelerator Complex (regression).
Distance Preserving Machine Learning for Uncertainty Aware Accelerator Capacitance Predictions
Jul 05, 2023Providing accurate uncertainty estimations is essential for producing reliable machine learning models, especially in safety-critical applications such as accelerator systems. Gaussian process models are generally regarded as the gold standard method for this task, but they can struggle with large, high-dimensional datasets. Combining deep neural networks with Gaussian process approximation techniques have shown promising results, but dimensionality reduction through standard deep neural network layers is not guaranteed to maintain the distance information necessary for Gaussian process models. We build on previous work by comparing the use of the singular value decomposition against a spectral-normalized dense layer as a feature extractor for a deep neural Gaussian process approximation model and apply it to a capacitance prediction problem for the High Voltage Converter Modulators in the Oak Ridge Spallation Neutron Source. Our model shows improved distance preservation and predicts in-distribution capacitance values with less than 1% error.
Multi-module based CVAE to predict HVCM faults in the SNS accelerator
Apr 20, 2023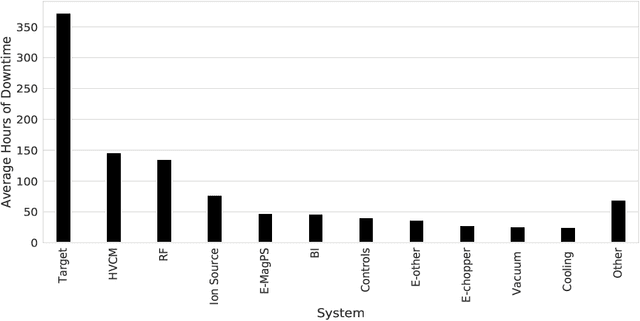



We present a multi-module framework based on Conditional Variational Autoencoder (CVAE) to detect anomalies in the power signals coming from multiple High Voltage Converter Modulators (HVCMs). We condition the model with the specific modulator type to capture different representations of the normal waveforms and to improve the sensitivity of the model to identify a specific type of fault when we have limited samples for a given module type. We studied several neural network (NN) architectures for our CVAE model and evaluated the model performance by looking at their loss landscape for stability and generalization. Our results for the Spallation Neutron Source (SNS) experimental data show that the trained model generalizes well to detecting multiple fault types for several HVCM module types. The results of this study can be used to improve the HVCM reliability and overall SNS uptime
Uncertainty aware anomaly detection to predict errant beam pulses in the SNS accelerator
Oct 22, 2021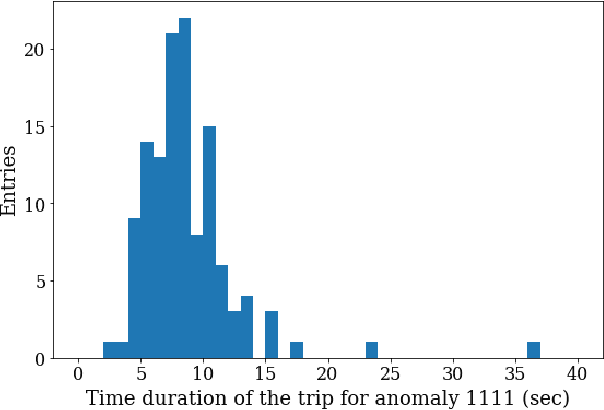
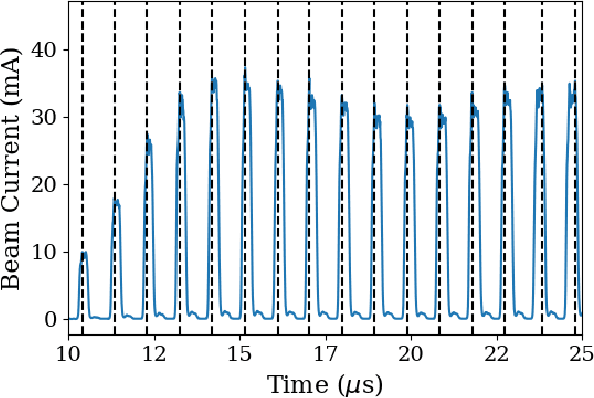
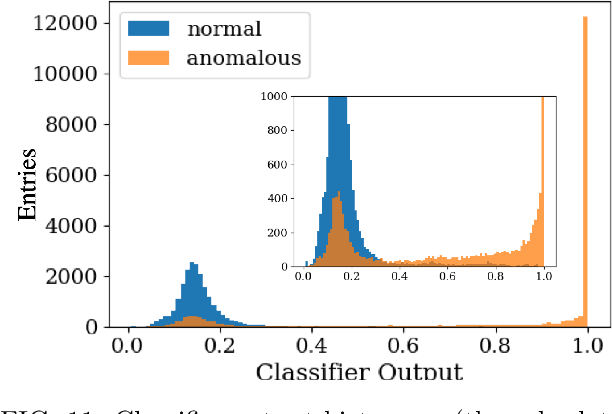
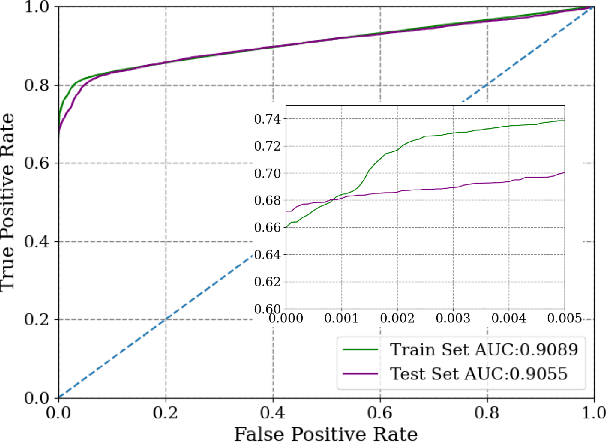
High-power particle accelerators are complex machines with thousands of pieces of equipmentthat are frequently running at the cutting edge of technology. In order to improve the day-to-dayoperations and maximize the delivery of the science, new analytical techniques are being exploredfor anomaly detection, classification, and prognostications. As such, we describe the applicationof an uncertainty aware Machine Learning method, the Siamese neural network model, to predictupcoming errant beam pulses using the data from a single monitoring device. By predicting theupcoming failure, we can stop the accelerator before damage occurs. We describe the acceleratoroperation, related Machine Learning research, the prediction performance required to abort beamwhile maintaining operations, the monitoring device and its data, and the Siamese method andits results. These results show that the researched method can be applied to improve acceleratoroperations.