 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-fidelity Modeling of Full-scale Pressurized Water Reactor Flow Fields for Machine Learning Applications
May 23, 2026This work presents a high-fidelity computational fluid dynamics (CFD) and data-driven modeling framework for assembly-level flow characterization in a four-loop pressurized water reactor (PWR). A full lower-plenum and core-inlet domain was constructed using publicly available geometry and operating conditions, enabling transient simulations with pump-induced swirl boundary conditions. The results show that cold-leg swirl and lower-plenum transport generate strongly heterogeneous assembly-wise inlet flow distributions, particularly near the lower core region, while axial resistance and mixing progressively homogenize the flow at higher elevations. These physics-informed datasets were subsequently used to evaluate machine learning (ML) applications for partial field reconstruction and short-term autoregressive prediction. A 3D convolutional-based inpainting model successfully recon-structed missing assembly-level mass flow rates from partial observations, with errors concentrated in the highly turbulent base (bottom) layer and diminishing significantly in upper layers. Comparative analysis across multiple ML models demon-strates that spatially aware architectures, particularly ConvLSTM, significantly outperform sequence-based (LSTM) and operator-learning (DeepONet) approaches by effectively capturing coupled spatio-temporal dynamics. The study also high-lights key challenges, including the sensitivity of inlet flow predictions to turbulence and mesh resolution, as well as the absence of full-scale experimental validation data. Despite these limitations, the results remain consistent with expected physical behavior. Overall, this work establishes high-fidelity CFD as a critical foundation for developing data-driven surrogates, sparse sensing strategies, and future multiphysics coupling frameworks.
Multifidelity Surrogate Modeling of Depressurized Loss of Forced Cooling in High-temperature Gas Reactors
Mar 14, 2026High-fidelity computational fluid dynamics (CFD) simulations are widely used to analyze nuclear reactor transients, but are computationally expensive when exploring large parameter spaces. Multifidelity surrogate models offer an approach to reduce cost by combining information from simulations of varying resolution. In this work, several multifidelity machine learning methods were evaluated for predicting the time to onset of natural circulation (ONC) and the temperature after ONC for a high-temperature gas reactor (HTGR) depressurized loss of forced cooling transient. A CFD model was developed in Ansys Fluent to generate 1000 simulation samples at each fidelity level, with low and medium-fidelity datasets produced by systematically coarsening the high-fidelity mesh. Multiple surrogate approaches were investigated, including multifidelity Gaussian processes and several neural network architectures, and validated on analytical benchmark functions before application to the ONC dataset. The results show that performance depends strongly on the informativeness of the input variables and the relationship between fidelity levels. Models trained using dominant inputs identified through prior sensitivity analysis consistently outperformed models trained on the full input set. The low- and high-fidelity pairing produced stronger performance than configurations involving medium-fidelity data, and two-fidelity configurations generally matched or exceeded three-fidelity counterparts at equivalent computational cost. Among the methods evaluated, multifidelity GP provided the most robust performance across input configurations, achieving excellent metrics for both time to ONC and temperature after ONC, while neural network approaches achieved comparable accuracy with substantially lower training times.
On the Impact of Language Nuances on Sentiment Analysis with Large Language Models: Paraphrasing, Sarcasm, and Emojis
Apr 08, 2025Large Language Models (LLMs) have demonstrated impressive performance across various tasks, including sentiment analysis. However, data quality--particularly when sourced from social media--can significantly impact their accuracy. This research explores how textual nuances, including emojis and sarcasm, affect sentiment analysis, with a particular focus on improving data quality through text paraphrasing techniques. To address the lack of labeled sarcasm data, the authors created a human-labeled dataset of 5929 tweets that enabled the assessment of LLM in various sarcasm contexts. The results show that when topic-specific datasets, such as those related to nuclear power, are used to finetune LLMs these models are not able to comprehend accurate sentiment in presence of sarcasm due to less diverse text, requiring external interventions like sarcasm removal to boost model accuracy. Sarcasm removal led to up to 21% improvement in sentiment accuracy, as LLMs trained on nuclear power-related content struggled with sarcastic tweets, achieving only 30% accuracy. In contrast, LLMs trained on general tweet datasets, covering a broader range of topics, showed considerable improvements in predicting sentiment for sarcastic tweets (60% accuracy), indicating that incorporating general text data can enhance sarcasm detection. The study also utilized adversarial text augmentation, showing that creating synthetic text variants by making minor changes significantly increased model robustness and accuracy for sarcastic tweets (approximately 85%). Additionally, text paraphrasing of tweets with fragmented language transformed around 40% of the tweets with low-confidence labels into high-confidence ones, improving LLMs sentiment analysis accuracy by 6%.
Opening the Black-Box: Symbolic Regression with Kolmogorov-Arnold Networks for Energy Applications
Apr 04, 2025While most modern machine learning methods offer speed and accuracy, few promise interpretability or explainability -- two key features necessary for highly sensitive industries, like medicine, finance, and engineering. Using eight datasets representative of one especially sensitive industry, nuclear power, this work compares a traditional feedforward neural network (FNN) to a Kolmogorov-Arnold Network (KAN). We consider not only model performance and accuracy, but also interpretability through model architecture and explainability through a post-hoc SHAP analysis. In terms of accuracy, we find KANs and FNNs comparable across all datasets, when output dimensionality is limited. KANs, which transform into symbolic equations after training, yield perfectly interpretable models while FNNs remain black-boxes. Finally, using the post-hoc explainability results from Kernel SHAP, we find that KANs learn real, physical relations from experimental data, while FNNs simply produce statistically accurate results. Overall, this analysis finds KANs a promising alternative to traditional machine learning methods, particularly in applications requiring both accuracy and comprehensibility.
Nuclear Microreactor Control with Deep Reinforcement Learning
Mar 31, 2025The economic feasibility of nuclear microreactors will depend on minimizing operating costs through advancements in autonomous control, especially when these microreactors are operating alongside other types of energy systems (e.g., renewable energy). This study explores the application of deep reinforcement learning (RL) for real-time drum control in microreactors, exploring performance in regard to load-following scenarios. By leveraging a point kinetics model with thermal and xenon feedback, we first establish a baseline using a single-output RL agent, then compare it against a traditional proportional-integral-derivative (PID) controller. This study demonstrates that RL controllers, including both single- and multi-agent RL (MARL) frameworks, can achieve similar or even superior load-following performance as traditional PID control across a range of load-following scenarios. In short transients, the RL agent was able to reduce the tracking error rate in comparison to PID. Over extended 300-minute load-following scenarios in which xenon feedback becomes a dominant factor, PID maintained better accuracy, but RL still remained within a 1% error margin despite being trained only on short-duration scenarios. This highlights RL's strong ability to generalize and extrapolate to longer, more complex transients, affording substantial reductions in training costs and reduced overfitting. Furthermore, when control was extended to multiple drums, MARL enabled independent drum control as well as maintained reactor symmetry constraints without sacrificing performance -- an objective that standard single-agent RL could not learn. We also found that, as increasing levels of Gaussian noise were added to the power measurements, the RL controllers were able to maintain lower error rates than PID, and to do so with less control effort.
Multi-objective Combinatorial Methodology for Nuclear Reactor Site Assessment: A Case Study for the United States
Dec 12, 2024
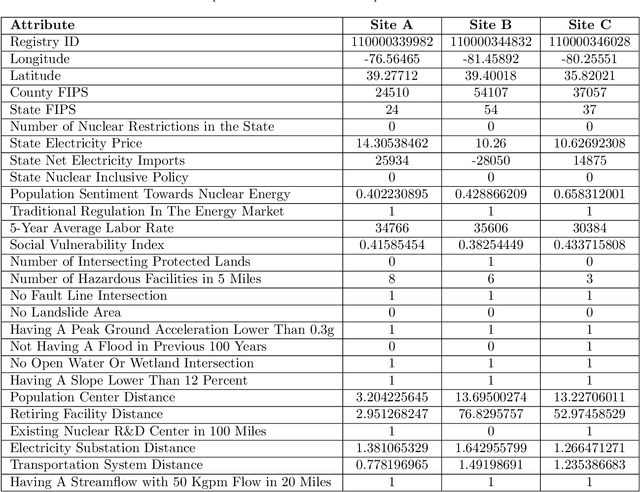
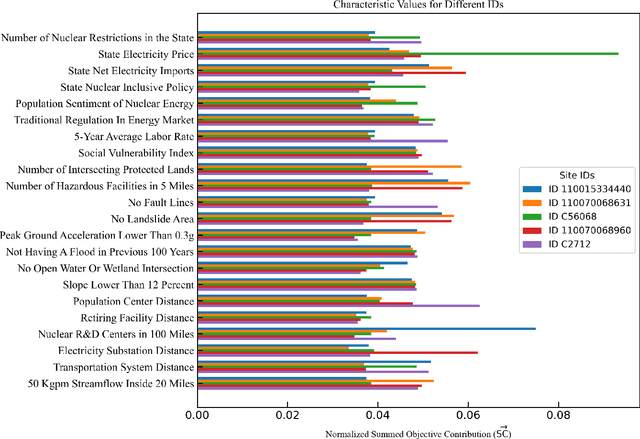
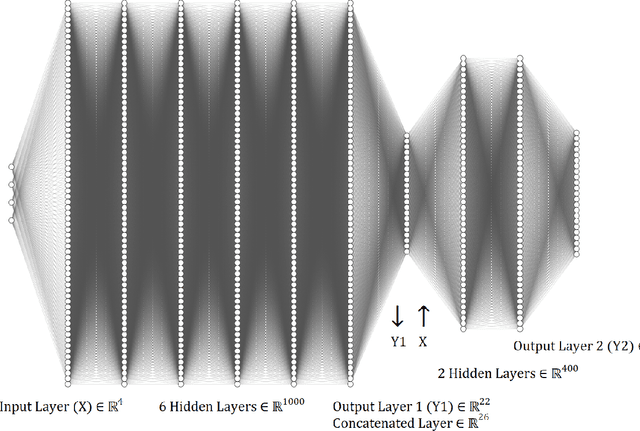
As the global demand for clean energy intensifies to achieve sustainability and net-zero carbon emission goals, nuclear energy stands out as a reliable solution. However, fully harnessing its potential requires overcoming key challenges, such as the high capital costs associated with nuclear power plants (NPPs). One promising strategy to mitigate these costs involves repurposing sites with existing infrastructure, including coal power plant (CPP) locations, which offer pre-built facilities and utilities. Additionally, brownfield sites - previously developed or underutilized lands often impacted by industrial activity - present another compelling alternative. These sites typically feature valuable infrastructure that can significantly reduce the costs of NPP development. This study introduces a novel multi-objective optimization methodology, leveraging combinatorial search to evaluate over 30,000 potential NPP sites in the United States. Our approach addresses gaps in the current practice of assigning pre-determined weights to each site attribute that could lead to bias in the ranking. Each site is assigned a performance-based score, derived from a detailed combinatorial analysis of its site attributes. The methodology generates a comprehensive database comprising site locations (inputs), attributes (outputs), site score (outputs), and the contribution of each attribute to the site score (outputs). We then use this database to train a machine learning neural network model, enabling rapid predictions of nuclear siting suitability across any location in the contiguous United States.
Multistep Criticality Search and Power Shaping in Microreactors with Reinforcement Learning
Jun 22, 2024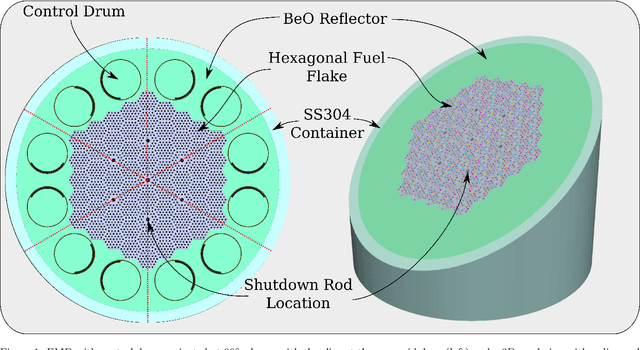
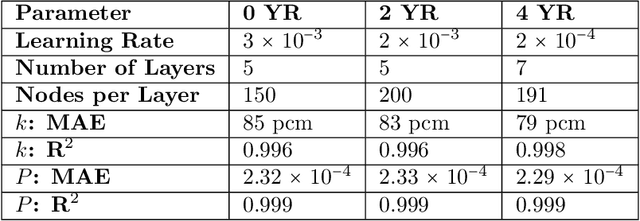
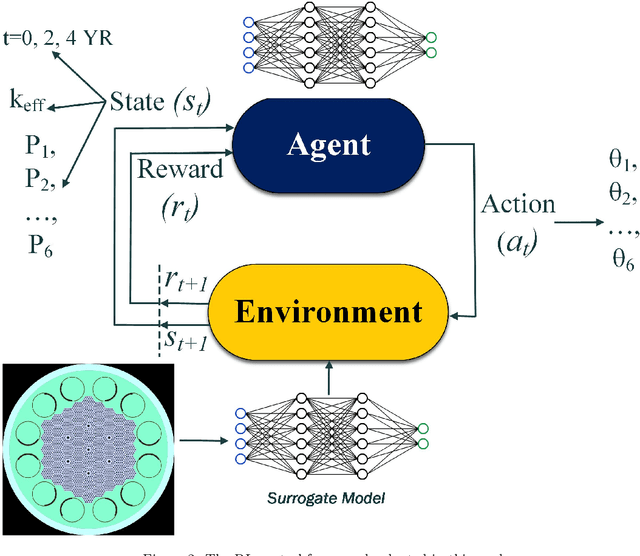
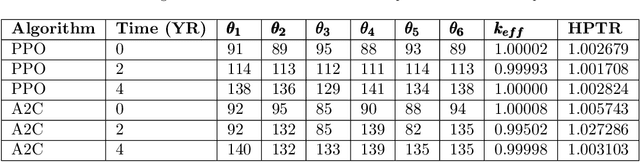
Reducing operation and maintenance costs is a key objective for advanced reactors in general and microreactors in particular. To achieve this reduction, developing robust autonomous control algorithms is essential to ensure safe and autonomous reactor operation. Recently, artificial intelligence and machine learning algorithms, specifically reinforcement learning (RL) algorithms, have seen rapid increased application to control problems, such as plasma control in fusion tokamaks and building energy management. In this work, we introduce the use of RL for intelligent control in nuclear microreactors. The RL agent is trained using proximal policy optimization (PPO) and advantage actor-critic (A2C), cutting-edge deep RL techniques, based on a high-fidelity simulation of a microreactor design inspired by the Westinghouse eVinci\textsuperscript{TM} design. We utilized a Serpent model to generate data on drum positions, core criticality, and core power distribution for training a feedforward neural network surrogate model. This surrogate model was then used to guide a PPO and A2C control policies in determining the optimal drum position across various reactor burnup states, ensuring critical core conditions and symmetrical power distribution across all six core portions. The results demonstrate the excellent performance of PPO in identifying optimal drum positions, achieving a hextant power tilt ratio of approximately 1.002 (within the limit of $<$ 1.02) and maintaining criticality within a 10 pcm range. A2C did not provide as competitive of a performance as PPO in terms of performance metrics for all burnup steps considered in the cycle. Additionally, the results highlight the capability of well-trained RL control policies to quickly identify control actions, suggesting a promising approach for enabling real-time autonomous control through digital twins.
Distance Preserving Machine Learning for Uncertainty Aware Accelerator Capacitance Predictions
Jul 05, 2023Providing accurate uncertainty estimations is essential for producing reliable machine learning models, especially in safety-critical applications such as accelerator systems. Gaussian process models are generally regarded as the gold standard method for this task, but they can struggle with large, high-dimensional datasets. Combining deep neural networks with Gaussian process approximation techniques have shown promising results, but dimensionality reduction through standard deep neural network layers is not guaranteed to maintain the distance information necessary for Gaussian process models. We build on previous work by comparing the use of the singular value decomposition against a spectral-normalized dense layer as a feature extractor for a deep neural Gaussian process approximation model and apply it to a capacitance prediction problem for the High Voltage Converter Modulators in the Oak Ridge Spallation Neutron Source. Our model shows improved distance preservation and predicts in-distribution capacitance values with less than 1% error.
Multi-module based CVAE to predict HVCM faults in the SNS accelerator
Apr 20, 2023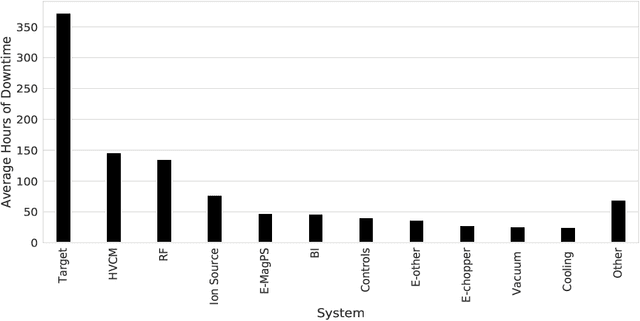



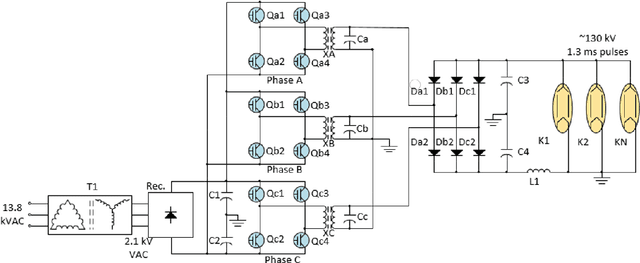
We present a multi-module framework based on Conditional Variational Autoencoder (CVAE) to detect anomalies in the power signals coming from multiple High Voltage Converter Modulators (HVCMs). We condition the model with the specific modulator type to capture different representations of the normal waveforms and to improve the sensitivity of the model to identify a specific type of fault when we have limited samples for a given module type. We studied several neural network (NN) architectures for our CVAE model and evaluated the model performance by looking at their loss landscape for stability and generalization. Our results for the Spallation Neutron Source (SNS) experimental data show that the trained model generalizes well to detecting multiple fault types for several HVCM module types. The results of this study can be used to improve the HVCM reliability and overall SNS uptime
Fault Prognosis in Particle Accelerator Power Electronics Using Ensemble Learning
Sep 30, 2022


Early fault detection and fault prognosis are crucial to ensure efficient and safe operations of complex engineering systems such as the Spallation Neutron Source (SNS) and its power electronics (high voltage converter modulators). Following an advanced experimental facility setup that mimics SNS operating conditions, the authors successfully conducted 21 fault prognosis experiments, where fault precursors are introduced in the system to a degree enough to cause degradation in the waveform signals, but not enough to reach a real fault. Nine different machine learning techniques based on ensemble trees, convolutional neural networks, support vector machines, and hierarchical voting ensembles are proposed to detect the fault precursors. Although all 9 models have shown a perfect and identical performance during the training and testing phase, the performance of most models has decreased in the prognosis phase once they got exposed to real-world data from the 21 experiments. The hierarchical voting ensemble, which features multiple layers of diverse models, maintains a distinguished performance in early detection of the fault precursors with 95% success rate (20/21 tests), followed by adaboost and extremely randomized trees with 52% and 48% success rates, respectively. The support vector machine models were the worst with only 24% success rate (5/21 tests). The study concluded that a successful implementation of machine learning in the SNS or particle accelerator power systems would require a major upgrade in the controller and the data acquisition system to facilitate streaming and handling big data for the machine learning models. In addition, this study shows that the best performing models were diverse and based on the ensemble concept to reduce the bias and hyperparameter sensitivity of individual models.