 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechno-economic optimization of a heat-pipe microreactor, part I: theory and cost optimization
Dec 17, 2025Microreactors, particularly heat-pipe microreactors (HPMRs), are compact, transportable, self-regulated power systems well-suited for access-challenged remote areas where costly fossil fuels dominate. However, they suffer from diseconomies of scale, and their financial viability remains unconvincing. One step in addressing this shortcoming is to design these reactors with comprehensive economic and physics analyses informing early-stage design iteration. In this work, we present a novel unifying geometric design optimization approach that accounts for techno-economic considerations. We start by generating random samples to train surrogate models, including Gaussian processes (GPs) and multi-layer perceptrons (MLPs). We then deploy these surrogates within a reinforcement learning (RL)-based optimization framework to optimize the levelized cost of electricity (LCOE), all the while imposing constraints on the fuel lifetime, shutdown margin (SDM), peak heat flux, and rod-integrated peaking factor. We study two cases: one in which the axial reflector cost is very high, and one in which it is inexpensive. We found that the operation and maintenance and capital costs are the primary contributors to the overall LCOE particularly the cost of the axial reflectors (for the first case) and the control drum materials. The optimizer cleverly changes the design parameters so as to minimize one of them while still satisfying the constraints, ultimately reducing the LCOE by more than 57% in both instances. A comprehensive integration of fuel and HP performance with multi-objective optimization is currently being pursued to fully understand the interaction between constraints and cost performance.
Surpassing legacy approaches and human intelligence with hybrid single- and multi-objective Reinforcement Learning-based optimization and interpretable AI to enable the economic operation of the US nuclear fleet
Feb 16, 2024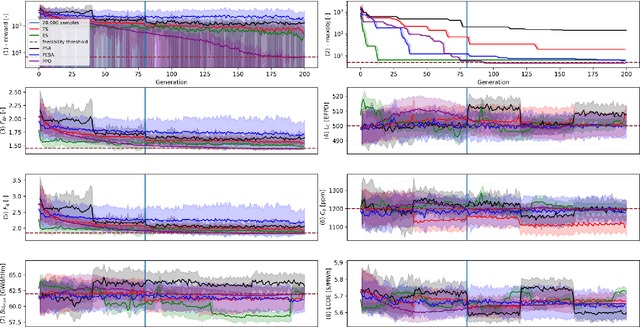



The nuclear sector represents the primary source of carbon-free energy in the United States. Nevertheless, existing nuclear power plants face the threat of early shutdowns due to their inability to compete economically against alternatives such as gas power plants. Optimizing the fuel cycle cost through the optimization of core loading patterns is one approach to addressing this lack of competitiveness. However, this optimization task involves multiple objectives and constraints, resulting in a vast number of candidate solutions that cannot be explicitly solved. While stochastic optimization (SO) methodologies are utilized by various nuclear utilities and vendors for fuel cycle reload design, manual design remains the preferred approach. To advance the state-of-the-art in core reload patterns, we have developed methods based on Deep Reinforcement Learning. Previous research has laid the groundwork for this approach and demonstrated its ability to discover high-quality patterns within a reasonable timeframe. However, there is a need for comparison against legacy methods to demonstrate its utility in a single-objective setting. While RL methods have shown superiority in multi-objective settings, they have not yet been applied to address the competitiveness issue effectively. In this paper, we rigorously compare our RL-based approach against the most commonly used SO-based methods, namely Genetic Algorithm (GA), Simulated Annealing (SA), and Tabu Search (TS). Subsequently, we introduce a new hybrid paradigm to devise innovative designs, resulting in economic gains ranging from 2.8 to 3.3 million dollars per year per plant. This development leverages interpretable AI, enabling improved algorithmic efficiency by making black-box optimizations interpretable. Future work will focus on scaling this method to address a broader range of core designs.
Pareto Envelope Augmented with Reinforcement Learning: Multi-objective reinforcement learning-based approach for Large-Scale Constrained Pressurized Water Reactor optimization
Dec 19, 2023



A novel method, the Pareto Envelope Augmented with Reinforcement Learning (PEARL), has been developed to address the challenges posed by multi-objective problems, particularly in the field of engineering where the evaluation of candidate solutions can be time-consuming. PEARL distinguishes itself from traditional policy-based multi-objective Reinforcement Learning methods by learning a single policy, eliminating the need for multiple neural networks to independently solve simpler sub-problems. Several versions inspired from deep learning and evolutionary techniques have been crafted, catering to both unconstrained and constrained problem domains. Curriculum Learning is harnessed to effectively manage constraints in these versions. PEARL's performance is first evaluated on classical multi-objective benchmarks. Additionally, it is tested on two practical PWR core Loading Pattern optimization problems to showcase its real-world applicability. The first problem involves optimizing the Cycle length and the rod-integrated peaking factor as the primary objectives, while the second problem incorporates the mean average enrichment as an additional objective. Furthermore, PEARL addresses three types of constraints related to boron concentration, peak pin burnup, and peak pin power. The results are systematically compared against a conventional approach, the Non-dominated Sorting Genetic Algorithm. Notably, PEARL, specifically the PEARL-NdS variant, efficiently uncovers a Pareto front without necessitating additional efforts from the algorithm designer, as opposed to a single optimization with scaled objectives. It also outperforms the classical approach across multiple performance metrics, including the Hyper-volume.
Assessment of Reinforcement Learning Algorithms for Nuclear Power Plant Fuel Optimization
May 09, 2023



The nuclear fuel loading pattern optimization problem has been studied since the dawn of the commercial nuclear energy industry. It is characterized by multiple objectives and constraints, with a very high number of candidate patterns, which makes it impossible to solve explicitly. Stochastic optimization methodologies are used by different nuclear utilities and vendors to perform fuel cycle reload design. Nevertheless, hand-designed solutions continue to be the prevalent method in the industry. To improve the state-of-the-art core reload patterns, we aim to create a method as scalable as possible, that agrees with the designer's goal of performance and safety. To help in this task Deep Reinforcement Learning (RL), in particular, Proximal Policy Optimization is leveraged. RL has recently experienced a strong impetus from its successes applied to games. This paper lays out the foundation of this method and proposes to study the behavior of several hyper-parameters that influence the RL algorithm via a multi-measure approach helped with statistical tests. The algorithm is highly dependent on multiple factors such as the shape of the objective function derived for the core design that behaves as a fudge factor that affects the stability of the learning. But also an exploration/exploitation trade-off that manifests through different parameters such as the number of loading patterns seen by the agents per episode, the number of samples collected before a policy update, and an entropy factor that increases the randomness of the policy trained. Experimental results also demonstrate the effectiveness of the method in finding high-quality solutions from scratch within a reasonable amount of time. Future work must include applying the algorithms to wide range of applications and comparing them to state-of-the-art implementation of stochastic optimization methods.
H2-Golden-Retriever: Methodology and Tool for an Evidence-Based Hydrogen Research Grantsmanship
Nov 16, 2022Hydrogen is poised to play a major role in decarbonizing the economy. The need to discover, develop, and understand low-cost, high-performance, durable materials that can help maximize the cost of electrolysis as well as the need for an intelligent tool to make evidence-based Hydrogen research funding decisions relatively easier warranted this study.In this work, we developed H2 Golden Retriever (H2GR) system for Hydrogen knowledge discovery and representation using Natural Language Processing (NLP), Knowledge Graph and Decision Intelligence. This system represents a novel methodology encapsulating state-of-the-art technique for evidence-based research grantmanship. Relevant Hydrogen papers were scraped and indexed from the web and preprocessing was done using noise and stop-words removal, language and spell check, stemming and lemmatization. The NLP tasks included Named Entity Recognition using Stanford and Spacy NER, topic modeling using Latent Dirichlet Allocation and TF-IDF. The Knowledge Graph module was used for the generation of meaningful entities and their relationships, trends and patterns in relevant H2 papers, thanks to an ontology of the hydrogen production domain. The Decision Intelligence component provides stakeholders with a simulation environment for cost and quantity dependencies. PageRank algorithm was used to rank papers of interest. Random searches were made on the proposed H2GR and the results included a list of papers ranked by relevancy score, entities, graphs of relationships between the entities, ontology of H2 production and Causal Decision Diagrams showing component interactivity. Qualitative assessment was done by the experts and H2GR is deemed to function to a satisfactory level.
NEORL: NeuroEvolution Optimization with Reinforcement Learning
Dec 01, 2021

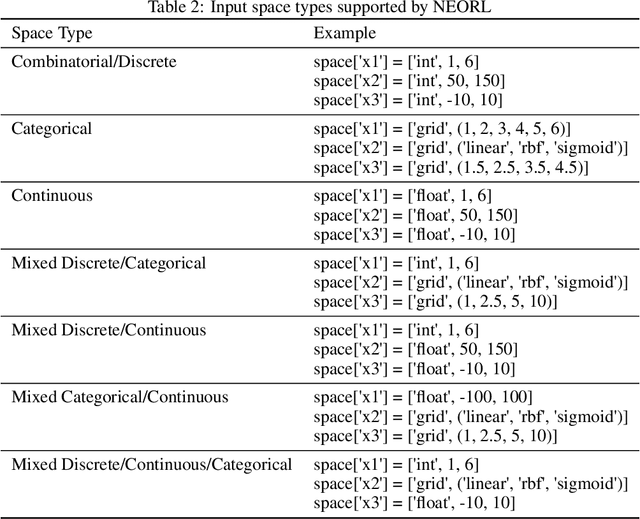

We present an open-source Python framework for NeuroEvolution Optimization with Reinforcement Learning (NEORL) developed at the Massachusetts Institute of Technology. NEORL offers a global optimization interface of state-of-the-art algorithms in the field of evolutionary computation, neural networks through reinforcement learning, and hybrid neuroevolution algorithms. NEORL features diverse set of algorithms, user-friendly interface, parallel computing support, automatic hyperparameter tuning, detailed documentation, and demonstration of applications in mathematical and real-world engineering optimization. NEORL encompasses various optimization problems from combinatorial, continuous, mixed discrete/continuous, to high-dimensional, expensive, and constrained engineering optimization. NEORL is tested in variety of engineering applications relevant to low carbon energy research in addressing solutions to climate change. The examples include nuclear reactor control and fuel cell power production. The results demonstrate NEORL competitiveness against other algorithms and optimization frameworks in the literature, and a potential tool to solve large-scale optimization problems. More examples and benchmarking of NEORL can be found here: https://neorl.readthedocs.io/en/latest/index.html