 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Pseudo-Reversible Normalizing Flow for Surrogate Modeling in Quantifying Uncertainty Propagation
Mar 31, 2024We introduce a conditional pseudo-reversible normalizing flow for constructing surrogate models of a physical model polluted by additive noise to efficiently quantify forward and inverse uncertainty propagation. Existing surrogate modeling approaches usually focus on approximating the deterministic component of physical model. However, this strategy necessitates knowledge of noise and resorts to auxiliary sampling methods for quantifying inverse uncertainty propagation. In this work, we develop the conditional pseudo-reversible normalizing flow model to directly learn and efficiently generate samples from the conditional probability density functions. The training process utilizes dataset consisting of input-output pairs without requiring prior knowledge about the noise and the function. Our model, once trained, can generate samples from any conditional probability density functions whose high probability regions are covered by the training set. Moreover, the pseudo-reversibility feature allows for the use of fully-connected neural network architectures, which simplifies the implementation and enables theoretical analysis. We provide a rigorous convergence analysis of the conditional pseudo-reversible normalizing flow model, showing its ability to converge to the target conditional probability density function using the Kullback-Leibler divergence. To demonstrate the effectiveness of our method, we apply it to several benchmark tests and a real-world geologic carbon storage problem.
Diffusion-Model-Assisted Supervised Learning of Generative Models for Density Estimation
Oct 22, 2023



We present a supervised learning framework of training generative models for density estimation. Generative models, including generative adversarial networks, normalizing flows, variational auto-encoders, are usually considered as unsupervised learning models, because labeled data are usually unavailable for training. Despite the success of the generative models, there are several issues with the unsupervised training, e.g., requirement of reversible architectures, vanishing gradients, and training instability. To enable supervised learning in generative models, we utilize the score-based diffusion model to generate labeled data. Unlike existing diffusion models that train neural networks to learn the score function, we develop a training-free score estimation method. This approach uses mini-batch-based Monte Carlo estimators to directly approximate the score function at any spatial-temporal location in solving an ordinary differential equation (ODE), corresponding to the reverse-time stochastic differential equation (SDE). This approach can offer both high accuracy and substantial time savings in neural network training. Once the labeled data are generated, we can train a simple fully connected neural network to learn the generative model in the supervised manner. Compared with existing normalizing flow models, our method does not require to use reversible neural networks and avoids the computation of the Jacobian matrix. Compared with existing diffusion models, our method does not need to solve the reverse-time SDE to generate new samples. As a result, the sampling efficiency is significantly improved. We demonstrate the performance of our method by applying it to a set of 2D datasets as well as real data from the UCI repository.
Convergence Analysis for Training Stochastic Neural Networks via Stochastic Gradient Descent
Dec 17, 2022In this paper, we carry out numerical analysis to prove convergence of a novel sample-wise back-propagation method for training a class of stochastic neural networks (SNNs). The structure of the SNN is formulated as discretization of a stochastic differential equation (SDE). A stochastic optimal control framework is introduced to model the training procedure, and a sample-wise approximation scheme for the adjoint backward SDE is applied to improve the efficiency of the stochastic optimal control solver, which is equivalent to the back-propagation for training the SNN. The convergence analysis is derived with and without convexity assumption for optimization of the SNN parameters. Especially, our analysis indicates that the number of SNN training steps should be proportional to the square of the number of layers in the convex optimization case. Numerical experiments are carried out to validate the analysis results, and the performance of the sample-wise back-propagation method for training SNNs is examined by benchmark machine learning examples.
Uncertainty Quantification in Deep Learning through Stochastic Maximum Principle
Nov 28, 2020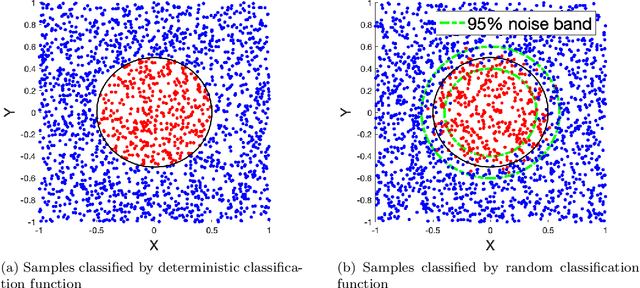
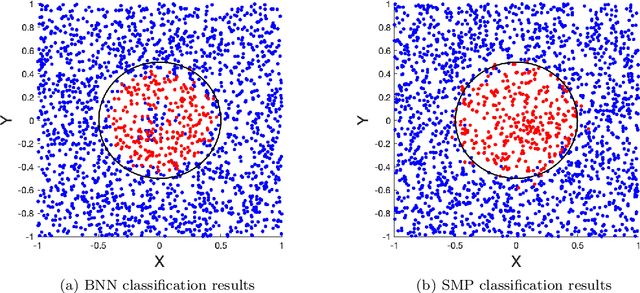
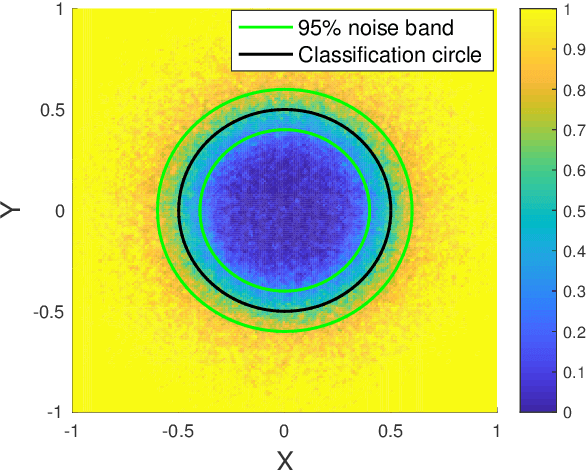
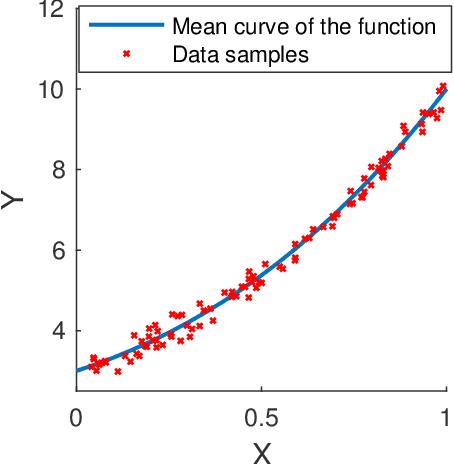
We develop a probabilistic machine learning method, which formulates a class of stochastic neural networks by a stochastic optimal control problem. An efficient stochastic gradient descent algorithm is introduced under the stochastic maximum principle framework. Convergence analysis for stochastic gradient descent optimization and numerical experiments for applications of stochastic neural networks are carried out to validate our methodology in both theory and performance.