 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning on Stochastic Neural Networks
Jun 09, 2025Federated learning is a machine learning paradigm that leverages edge computing on client devices to optimize models while maintaining user privacy by ensuring that local data remains on the device. However, since all data is collected by clients, federated learning is susceptible to latent noise in local datasets. Factors such as limited measurement capabilities or human errors may introduce inaccuracies in client data. To address this challenge, we propose the use of a stochastic neural network as the local model within the federated learning framework. Stochastic neural networks not only facilitate the estimation of the true underlying states of the data but also enable the quantification of latent noise. We refer to our federated learning approach, which incorporates stochastic neural networks as local models, as Federated stochastic neural networks. We will present numerical experiments demonstrating the performance and effectiveness of our method, particularly in handling non-independent and identically distributed data.
MGARD: A multigrid framework for high-performance, error-controlled data compression and refactoring
Jan 11, 2024We describe MGARD, a software providing MultiGrid Adaptive Reduction for floating-point scientific data on structured and unstructured grids. With exceptional data compression capability and precise error control, MGARD addresses a wide range of requirements, including storage reduction, high-performance I/O, and in-situ data analysis. It features a unified application programming interface (API) that seamlessly operates across diverse computing architectures. MGARD has been optimized with highly-tuned GPU kernels and efficient memory and device management mechanisms, ensuring scalable and rapid operations.
* 20 pages, 8 figures
Streaming Compression of Scientific Data via weak-SINDy
Aug 29, 2023In this paper a streaming weak-SINDy algorithm is developed specifically for compressing streaming scientific data. The production of scientific data, either via simulation or experiments, is undergoing an stage of exponential growth, which makes data compression important and often necessary for storing and utilizing large scientific data sets. As opposed to classical ``offline" compression algorithms that perform compression on a readily available data set, streaming compression algorithms compress data ``online" while the data generated from simulation or experiments is still flowing through the system. This feature makes streaming compression algorithms well-suited for scientific data compression, where storing the full data set offline is often infeasible. This work proposes a new streaming compression algorithm, streaming weak-SINDy, which takes advantage of the underlying data characteristics during compression. The streaming weak-SINDy algorithm constructs feature matrices and target vectors in the online stage via a streaming integration method in a memory efficient manner. The feature matrices and target vectors are then used in the offline stage to build a model through a regression process that aims to recover equations that govern the evolution of the data. For compressing high-dimensional streaming data, we adopt a streaming proper orthogonal decomposition (POD) process to reduce the data dimension and then use the streaming weak-SINDy algorithm to compress the temporal data of the POD expansion. We propose modifications to the streaming weak-SINDy algorithm to accommodate the dynamically updated POD basis. By combining the built model from the streaming weak-SINDy algorithm and a small amount of data samples, the full data flow could be reconstructed accurately at a low memory cost, as shown in the numerical tests.
Convergence Analysis for Training Stochastic Neural Networks via Stochastic Gradient Descent
Dec 17, 2022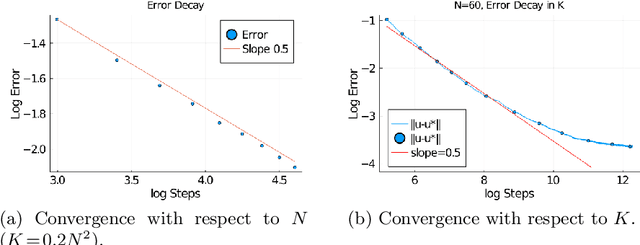



In this paper, we carry out numerical analysis to prove convergence of a novel sample-wise back-propagation method for training a class of stochastic neural networks (SNNs). The structure of the SNN is formulated as discretization of a stochastic differential equation (SDE). A stochastic optimal control framework is introduced to model the training procedure, and a sample-wise approximation scheme for the adjoint backward SDE is applied to improve the efficiency of the stochastic optimal control solver, which is equivalent to the back-propagation for training the SNN. The convergence analysis is derived with and without convexity assumption for optimization of the SNN parameters. Especially, our analysis indicates that the number of SNN training steps should be proportional to the square of the number of layers in the convex optimization case. Numerical experiments are carried out to validate the analysis results, and the performance of the sample-wise back-propagation method for training SNNs is examined by benchmark machine learning examples.
A Kernel Learning Method for Backward SDE Filter
Jan 25, 2022In this paper, we develop a kernel learning backward SDE filter method to estimate the state of a stochastic dynamical system based on its partial noisy observations. A system of forward backward stochastic differential equations is used to propagate the state of the target dynamical model, and Bayesian inference is applied to incorporate the observational information. To characterize the dynamical model in the entire state space, we introduce a kernel learning method to learn a continuous global approximation for the conditional probability density function of the target state by using discrete approximated density values as training data. Numerical experiments demonstrate that the kernel learning backward SDE is highly effective and highly efficient.
Uncertainty Quantification in Deep Learning through Stochastic Maximum Principle
Nov 28, 2020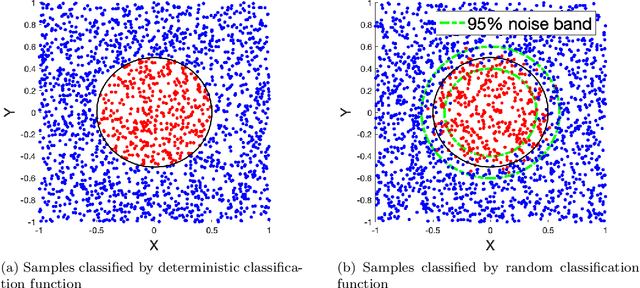
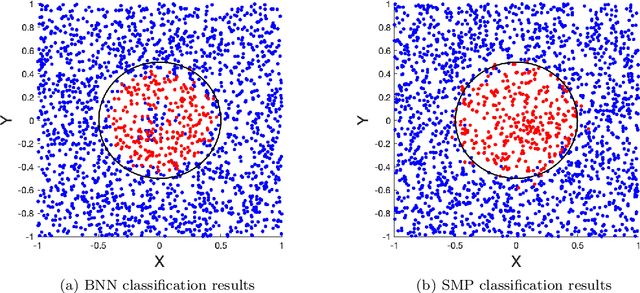
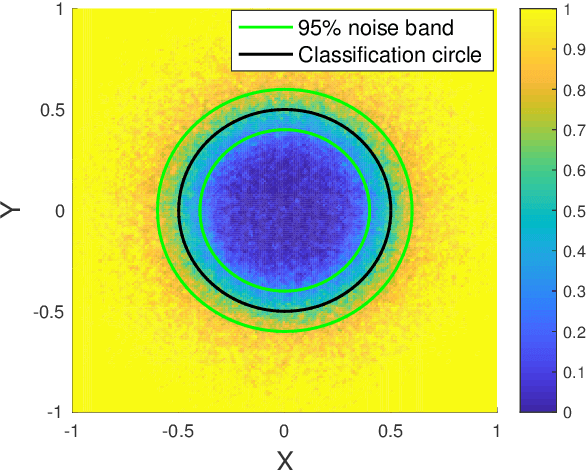
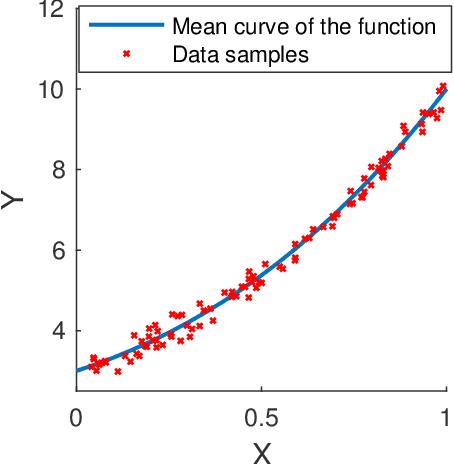
We develop a probabilistic machine learning method, which formulates a class of stochastic neural networks by a stochastic optimal control problem. An efficient stochastic gradient descent algorithm is introduced under the stochastic maximum principle framework. Convergence analysis for stochastic gradient descent optimization and numerical experiments for applications of stochastic neural networks are carried out to validate our methodology in both theory and performance.