 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
Video4DGen: Enhancing Video and 4D Generation through Mutual Optimization
Apr 05, 2025The advancement of 4D (i.e., sequential 3D) generation opens up new possibilities for lifelike experiences in various applications, where users can explore dynamic objects or characters from any viewpoint. Meanwhile, video generative models are receiving particular attention given their ability to produce realistic and imaginative frames. These models are also observed to exhibit strong 3D consistency, indicating the potential to act as world simulators. In this work, we present Video4DGen, a novel framework that excels in generating 4D representations from single or multiple generated videos as well as generating 4D-guided videos. This framework is pivotal for creating high-fidelity virtual contents that maintain both spatial and temporal coherence. The 4D outputs generated by Video4DGen are represented using our proposed Dynamic Gaussian Surfels (DGS), which optimizes time-varying warping functions to transform Gaussian surfels (surface elements) from a static state to a dynamically warped state. We design warped-state geometric regularization and refinements on Gaussian surfels, to preserve the structural integrity and fine-grained appearance details. To perform 4D generation from multiple videos and capture representation across spatial, temporal, and pose dimensions, we design multi-video alignment, root pose optimization, and pose-guided frame sampling strategies. The leveraging of continuous warping fields also enables a precise depiction of pose, motion, and deformation over per-video frames. Further, to improve the overall fidelity from the observation of all camera poses, Video4DGen performs novel-view video generation guided by the 4D content, with the proposed confidence-filtered DGS to enhance the quality of generated sequences. With the ability of 4D and video generation, Video4DGen offers a powerful tool for applications in virtual reality, animation, and beyond.
DIFFER: Disentangling Identity Features via Semantic Cues for Clothes-Changing Person Re-ID
Mar 28, 2025



Clothes-changing person re-identification (CC-ReID) aims to recognize individuals under different clothing scenarios. Current CC-ReID approaches either concentrate on modeling body shape using additional modalities including silhouette, pose, and body mesh, potentially causing the model to overlook other critical biometric traits such as gender, age, and style, or they incorporate supervision through additional labels that the model tries to disregard or emphasize, such as clothing or personal attributes. However, these annotations are discrete in nature and do not capture comprehensive descriptions. In this work, we propose DIFFER: Disentangle Identity Features From Entangled Representations, a novel adversarial learning method that leverages textual descriptions to disentangle identity features. Recognizing that image features inherently mix inseparable information, DIFFER introduces NBDetach, a mechanism designed for feature disentanglement by leveraging the separable nature of text descriptions as supervision. It partitions the feature space into distinct subspaces and, through gradient reversal layers, effectively separates identity-related features from non-biometric features. We evaluate DIFFER on 4 different benchmark datasets (LTCC, PRCC, CelebreID-Light, and CCVID) to demonstrate its effectiveness and provide state-of-the-art performance across all the benchmarks. DIFFER consistently outperforms the baseline method, with improvements in top-1 accuracy of 3.6% on LTCC, 3.4% on PRCC, 2.5% on CelebReID-Light, and 1% on CCVID. Our code can be found here.
Will the Inclusion of Generated Data Amplify Bias Across Generations in Future Image Classification Models?
Oct 14, 2024As the demand for high-quality training data escalates, researchers have increasingly turned to generative models to create synthetic data, addressing data scarcity and enabling continuous model improvement. However, reliance on self-generated data introduces a critical question: Will this practice amplify bias in future models? While most research has focused on overall performance, the impact on model bias, particularly subgroup bias, remains underexplored. In this work, we investigate the effects of the generated data on image classification tasks, with a specific focus on bias. We develop a practical simulation environment that integrates a self-consuming loop, where the generative model and classification model are trained synergistically. Hundreds of experiments are conducted on Colorized MNIST, CIFAR-20/100, and Hard ImageNet datasets to reveal changes in fairness metrics across generations. In addition, we provide a conjecture to explain the bias dynamics when training models on continuously augmented datasets across generations. Our findings contribute to the ongoing debate on the implications of synthetic data for fairness in real-world applications.
Biomedical Visual Instruction Tuning with Clinician Preference Alignment
Jun 19, 2024



Recent advancements in multimodal foundation models have showcased impressive capabilities in understanding and reasoning with visual and textual information. Adapting these foundation models trained for general usage to specialized domains like biomedicine requires large-scale domain-specific instruction datasets. While existing works have explored curating such datasets automatically, the resultant datasets are not explicitly aligned with domain expertise. In this work, we propose a data-centric framework, Biomedical Visual Instruction Tuning with Clinician Preference Alignment (BioMed-VITAL), that incorporates clinician preferences into both stages of generating and selecting instruction data for tuning biomedical multimodal foundation models. First, during the generation stage, we prompt the GPT-4V generator with a diverse set of clinician-selected demonstrations for preference-aligned data candidate generation. Then, during the selection phase, we train a separate selection model, which explicitly distills clinician and policy-guided model preferences into a rating function to select high-quality data for medical instruction tuning. Results show that the model tuned with the instruction-following data from our method demonstrates a significant improvement in open visual chat (18.5% relatively) and medical VQA (win rate up to 81.73%). Our instruction-following data and models are available at BioMed-VITAL.github.io.
CR-UTP: Certified Robustness against Universal Text Perturbations
Jun 04, 2024



It is imperative to ensure the stability of every prediction made by a language model; that is, a language's prediction should remain consistent despite minor input variations, like word substitutions. In this paper, we investigate the problem of certifying a language model's robustness against Universal Text Perturbations (UTPs), which have been widely used in universal adversarial attacks and backdoor attacks. Existing certified robustness based on random smoothing has shown considerable promise in certifying the input-specific text perturbations (ISTPs), operating under the assumption that any random alteration of a sample's clean or adversarial words would negate the impact of sample-wise perturbations. However, with UTPs, masking only the adversarial words can eliminate the attack. A naive method is to simply increase the masking ratio and the likelihood of masking attack tokens, but it leads to a significant reduction in both certified accuracy and the certified radius due to input corruption by extensive masking. To solve this challenge, we introduce a novel approach, the superior prompt search method, designed to identify a superior prompt that maintains higher certified accuracy under extensive masking. Additionally, we theoretically motivate why ensembles are a particularly suitable choice as base prompts for random smoothing. The method is denoted by superior prompt ensembling technique. We also empirically confirm this technique, obtaining state-of-the-art results in multiple settings. These methodologies, for the first time, enable high certified accuracy against both UTPs and ISTPs. The source code of CR-UTP is available at https://github.com/UCFML-Research/CR-UTP.
FARPLS: A Feature-Augmented Robot Trajectory Preference Labeling System to Assist Human Labelers' Preference Elicitation
Mar 10, 2024Preference-based learning aims to align robot task objectives with human values. One of the most common methods to infer human preferences is by pairwise comparisons of robot task trajectories. Traditional comparison-based preference labeling systems seldom support labelers to digest and identify critical differences between complex trajectories recorded in videos. Our formative study (N = 12) suggests that individuals may overlook non-salient task features and establish biased preference criteria during their preference elicitation process because of partial observations. In addition, they may experience mental fatigue when given many pairs to compare, causing their label quality to deteriorate. To mitigate these issues, we propose FARPLS, a Feature-Augmented Robot trajectory Preference Labeling System. FARPLS highlights potential outliers in a wide variety of task features that matter to humans and extracts the corresponding video keyframes for easy review and comparison. It also dynamically adjusts the labeling order according to users' familiarities, difficulties of the trajectory pair, and level of disagreements. At the same time, the system monitors labelers' consistency and provides feedback on labeling progress to keep labelers engaged. A between-subjects study (N = 42, 105 pairs of robot pick-and-place trajectories per person) shows that FARPLS can help users establish preference criteria more easily and notice more relevant details in the presented trajectories than the conventional interface. FARPLS also improves labeling consistency and engagement, mitigating challenges in preference elicitation without raising cognitive loads significantly
OSSAR: Towards Open-Set Surgical Activity Recognition in Robot-assisted Surgery
Feb 10, 2024



In the realm of automated robotic surgery and computer-assisted interventions, understanding robotic surgical activities stands paramount. Existing algorithms dedicated to surgical activity recognition predominantly cater to pre-defined closed-set paradigms, ignoring the challenges of real-world open-set scenarios. Such algorithms often falter in the presence of test samples originating from classes unseen during training phases. To tackle this problem, we introduce an innovative Open-Set Surgical Activity Recognition (OSSAR) framework. Our solution leverages the hyperspherical reciprocal point strategy to enhance the distinction between known and unknown classes in the feature space. Additionally, we address the issue of over-confidence in the closed set by refining model calibration, avoiding misclassification of unknown classes as known ones. To support our assertions, we establish an open-set surgical activity benchmark utilizing the public JIGSAWS dataset. Besides, we also collect a novel dataset on endoscopic submucosal dissection for surgical activity tasks. Extensive comparisons and ablation experiments on these datasets demonstrate the significant outperformance of our method over existing state-of-the-art approaches. Our proposed solution can effectively address the challenges of real-world surgical scenarios. Our code is publicly accessible at https://github.com/longbai1006/OSSAR.
MGARD: A multigrid framework for high-performance, error-controlled data compression and refactoring
Jan 11, 2024We describe MGARD, a software providing MultiGrid Adaptive Reduction for floating-point scientific data on structured and unstructured grids. With exceptional data compression capability and precise error control, MGARD addresses a wide range of requirements, including storage reduction, high-performance I/O, and in-situ data analysis. It features a unified application programming interface (API) that seamlessly operates across diverse computing architectures. MGARD has been optimized with highly-tuned GPU kernels and efficient memory and device management mechanisms, ensuring scalable and rapid operations.
* 20 pages, 8 figures
Spatiotemporally adaptive compression for scientific dataset with feature preservation -- a case study on simulation data with extreme climate events analysis
Jan 06, 2024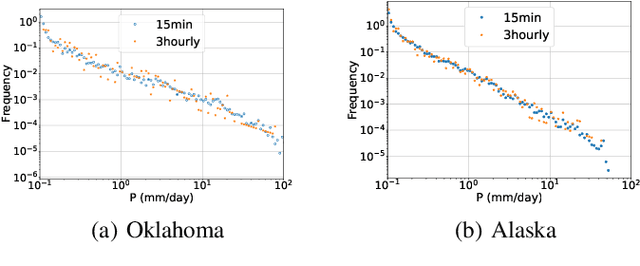
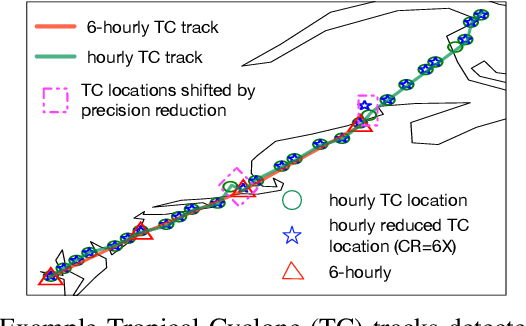
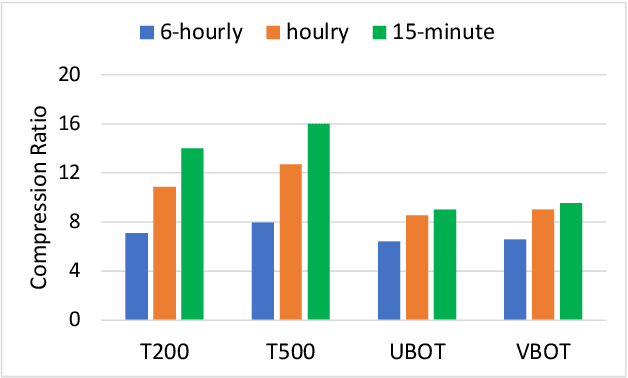
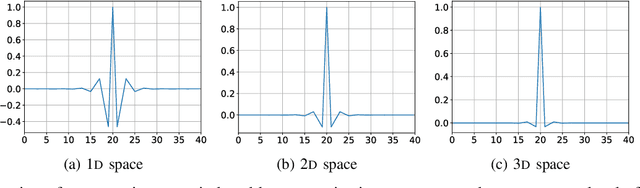
Scientific discoveries are increasingly constrained by limited storage space and I/O capacities. For time-series simulations and experiments, their data often need to be decimated over timesteps to accommodate storage and I/O limitations. In this paper, we propose a technique that addresses storage costs while improving post-analysis accuracy through spatiotemporal adaptive, error-controlled lossy compression. We investigate the trade-off between data precision and temporal output rates, revealing that reducing data precision and increasing timestep frequency lead to more accurate analysis outcomes. Additionally, we integrate spatiotemporal feature detection with data compression and demonstrate that performing adaptive error-bounded compression in higher dimensional space enables greater compression ratios, leveraging the error propagation theory of a transformation-based compressor. To evaluate our approach, we conduct experiments using the well-known E3SM climate simulation code and apply our method to compress variables used for cyclone tracking. Our results show a significant reduction in storage size while enhancing the quality of cyclone tracking analysis, both quantitatively and qualitatively, in comparison to the prevalent timestep decimation approach. Compared to three state-of-the-art lossy compressors lacking feature preservation capabilities, our adaptive compression framework improves perfectly matched cases in TC tracking by 26.4-51.3% at medium compression ratios and by 77.3-571.1% at large compression ratios, with a merely 5-11% computational overhead.
* 10 pages, 13 figures, 2023 IEEE International Conference on e-Science and Grid Computing