 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCipherPrune: Efficient and Scalable Private Transformer Inference
Feb 24, 2025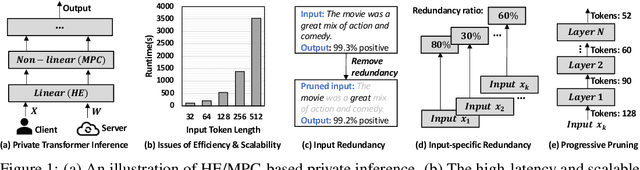
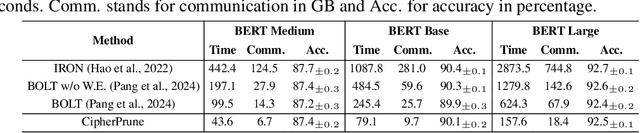
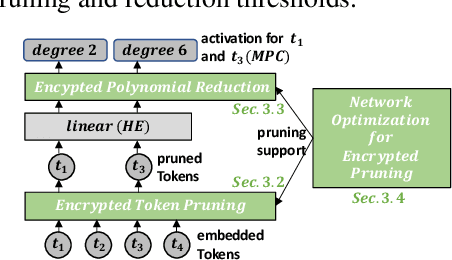
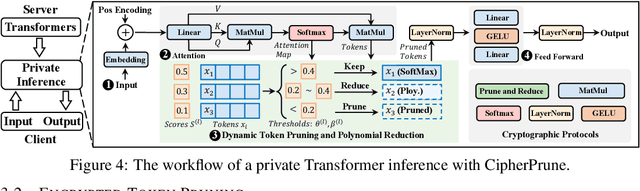
Private Transformer inference using cryptographic protocols offers promising solutions for privacy-preserving machine learning; however, it still faces significant runtime overhead (efficiency issues) and challenges in handling long-token inputs (scalability issues). We observe that the Transformer's operational complexity scales quadratically with the number of input tokens, making it essential to reduce the input token length. Notably, each token varies in importance, and many inputs contain redundant tokens. Additionally, prior private inference methods that rely on high-degree polynomial approximations for non-linear activations are computationally expensive. Therefore, reducing the polynomial degree for less important tokens can significantly accelerate private inference. Building on these observations, we propose \textit{CipherPrune}, an efficient and scalable private inference framework that includes a secure encrypted token pruning protocol, a polynomial reduction protocol, and corresponding Transformer network optimizations. At the protocol level, encrypted token pruning adaptively removes unimportant tokens from encrypted inputs in a progressive, layer-wise manner. Additionally, encrypted polynomial reduction assigns lower-degree polynomials to less important tokens after pruning, enhancing efficiency without decryption. At the network level, we introduce protocol-aware network optimization via a gradient-based search to maximize pruning thresholds and polynomial reduction conditions while maintaining the desired accuracy. Our experiments demonstrate that CipherPrune reduces the execution overhead of private Transformer inference by approximately $6.1\times$ for 128-token inputs and $10.6\times$ for 512-token inputs, compared to previous methods, with only a marginal drop in accuracy. The code is publicly available at https://github.com/UCF-Lou-Lab-PET/cipher-prune-inference.
CryptoTrain: Fast Secure Training on Encrypted Datase
Sep 25, 2024



Secure training, while protecting the confidentiality of both data and model weights, typically incurs significant training overhead. Traditional Fully Homomorphic Encryption (FHE)-based non-inter-active training models are heavily burdened by computationally demanding bootstrapping. To develop an efficient secure training system, we established a foundational framework, CryptoTrain-B, utilizing a hybrid cryptographic protocol that merges FHE with Oblivious Transfer (OT) for handling linear and non-linear operations, respectively. This integration eliminates the need for costly bootstrapping. Although CryptoTrain-B sets a new baseline in performance, reducing its training overhead remains essential. We found that ciphertext-ciphertext multiplication (CCMul) is a critical bottleneck in operations involving encrypted inputs and models. Our solution, the CCMul-Precompute technique, involves precomputing CCMul offline and resorting to the less resource-intensive ciphertext-plaintext multiplication (CPMul) during private training. Furthermore, conventional polynomial convolution in FHE systems tends to encode irrelevant and redundant values into polynomial slots, necessitating additional polynomials and ciphertexts for input representation and leading to extra multiplications. Addressing this, we introduce correlated polynomial convolution, which encodes only related input values into polynomials, thus drastically reducing the number of computations and overheads. By integrating CCMul-Precompute and correlated polynomial convolution into CryptoTrain-B, we facilitate a rapid and efficient secure training framework, CryptoTrain. Extensive experiments demonstrate that CryptoTrain achieves a ~5.3X training time reduction compared to prior methods.
CR-UTP: Certified Robustness against Universal Text Perturbations
Jun 04, 2024



It is imperative to ensure the stability of every prediction made by a language model; that is, a language's prediction should remain consistent despite minor input variations, like word substitutions. In this paper, we investigate the problem of certifying a language model's robustness against Universal Text Perturbations (UTPs), which have been widely used in universal adversarial attacks and backdoor attacks. Existing certified robustness based on random smoothing has shown considerable promise in certifying the input-specific text perturbations (ISTPs), operating under the assumption that any random alteration of a sample's clean or adversarial words would negate the impact of sample-wise perturbations. However, with UTPs, masking only the adversarial words can eliminate the attack. A naive method is to simply increase the masking ratio and the likelihood of masking attack tokens, but it leads to a significant reduction in both certified accuracy and the certified radius due to input corruption by extensive masking. To solve this challenge, we introduce a novel approach, the superior prompt search method, designed to identify a superior prompt that maintains higher certified accuracy under extensive masking. Additionally, we theoretically motivate why ensembles are a particularly suitable choice as base prompts for random smoothing. The method is denoted by superior prompt ensembling technique. We also empirically confirm this technique, obtaining state-of-the-art results in multiple settings. These methodologies, for the first time, enable high certified accuracy against both UTPs and ISTPs. The source code of CR-UTP is available at https://github.com/UCFML-Research/CR-UTP.