 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexFlow: A Unified Approach for Dexterous Hand Pose Retargeting and Interaction
May 02, 2025Despite advances in hand-object interaction modeling, generating realistic dexterous manipulation data for robotic hands remains a challenge. Retargeting methods often suffer from low accuracy and fail to account for hand-object interactions, leading to artifacts like interpenetration. Generative methods, lacking human hand priors, produce limited and unnatural poses. We propose a data transformation pipeline that combines human hand and object data from multiple sources for high-precision retargeting. Our approach uses a differential loss constraint to ensure temporal consistency and generates contact maps to refine hand-object interactions. Experiments show our method significantly improves pose accuracy, naturalness, and diversity, providing a robust solution for hand-object interaction modeling.
CryptoTrain: Fast Secure Training on Encrypted Datase
Sep 25, 2024



Secure training, while protecting the confidentiality of both data and model weights, typically incurs significant training overhead. Traditional Fully Homomorphic Encryption (FHE)-based non-inter-active training models are heavily burdened by computationally demanding bootstrapping. To develop an efficient secure training system, we established a foundational framework, CryptoTrain-B, utilizing a hybrid cryptographic protocol that merges FHE with Oblivious Transfer (OT) for handling linear and non-linear operations, respectively. This integration eliminates the need for costly bootstrapping. Although CryptoTrain-B sets a new baseline in performance, reducing its training overhead remains essential. We found that ciphertext-ciphertext multiplication (CCMul) is a critical bottleneck in operations involving encrypted inputs and models. Our solution, the CCMul-Precompute technique, involves precomputing CCMul offline and resorting to the less resource-intensive ciphertext-plaintext multiplication (CPMul) during private training. Furthermore, conventional polynomial convolution in FHE systems tends to encode irrelevant and redundant values into polynomial slots, necessitating additional polynomials and ciphertexts for input representation and leading to extra multiplications. Addressing this, we introduce correlated polynomial convolution, which encodes only related input values into polynomials, thus drastically reducing the number of computations and overheads. By integrating CCMul-Precompute and correlated polynomial convolution into CryptoTrain-B, we facilitate a rapid and efficient secure training framework, CryptoTrain. Extensive experiments demonstrate that CryptoTrain achieves a ~5.3X training time reduction compared to prior methods.
Privacy Loss in Apple's Implementation of Differential Privacy on MacOS 10.12
Sep 11, 2017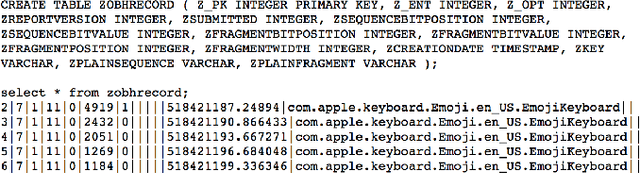
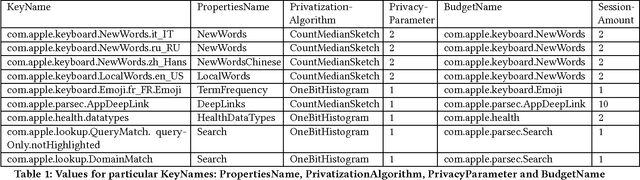
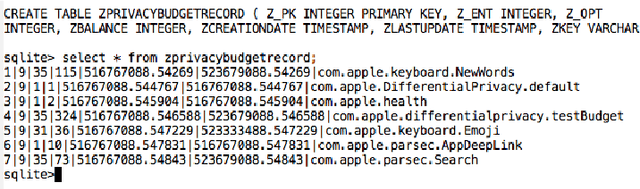
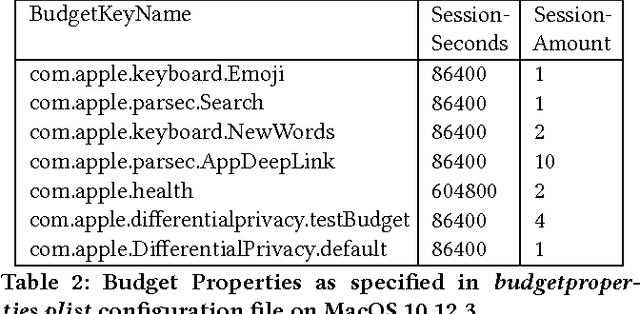
In June 2016, Apple announced that it will deploy differential privacy for some user data collection in order to ensure privacy of user data, even from Apple. The details of Apple's approach remained sparse. Although several patents have since appeared hinting at the algorithms that may be used to achieve differential privacy, they did not include a precise explanation of the approach taken to privacy parameter choice. Such choice and the overall approach to privacy budget use and management are key questions for understanding the privacy protections provided by any deployment of differential privacy. In this work, through a combination of experiments, static and dynamic code analysis of macOS Sierra (Version 10.12) implementation, we shed light on the choices Apple made for privacy budget management. We discover and describe Apple's set-up for differentially private data processing, including the overall data pipeline, the parameters used for differentially private perturbation of each piece of data, and the frequency with which such data is sent to Apple's servers. We find that although Apple's deployment ensures that the (differential) privacy loss per each datum submitted to its servers is $1$ or $2$, the overall privacy loss permitted by the system is significantly higher, as high as $16$ per day for the four initially announced applications of Emojis, New words, Deeplinks and Lookup Hints. Furthermore, Apple renews the privacy budget available every day, which leads to a possible privacy loss of 16 times the number of days since user opt-in to differentially private data collection for those four applications. We advocate that in order to claim the full benefits of differentially private data collection, Apple must give full transparency of its implementation, enable user choice in areas related to privacy loss, and set meaningful defaults on the privacy loss permitted.