 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Speech, Emotion, and Motion: a VLM-based Multimodal Edge-deployable Framework for Humanoid Robots
Feb 07, 2026Effective human-robot interaction requires emotionally rich multimodal expressions, yet most humanoid robots lack coordinated speech, facial expressions, and gestures. Meanwhile, real-world deployment demands on-device solutions that can operate autonomously without continuous cloud connectivity. To bridging \underline{\textit{S}}peech, \underline{\textit{E}}motion, and \underline{\textit{M}}otion, we present \textit{SeM$^2$}, a Vision Language Model-based framework that orchestrates emotionally coherent multimodal interactions through three key components: a multimodal perception module capturing user contextual cues, a Chain-of-Thought reasoning for response planning, and a novel Semantic-Sequence Aligning Mechanism (SSAM) that ensures precise temporal coordination between verbal content and physical expressions. We implement both cloud-based and \underline{\textit{e}}dge-deployed versions (\textit{SeM$^2_e$}), with the latter knowledge distilled to operate efficiently on edge hardware while maintaining 95\% of the relative performance. Comprehensive evaluations demonstrate that our approach significantly outperforms unimodal baselines in naturalness, emotional clarity, and modal coherence, advancing socially expressive humanoid robotics for diverse real-world environments.
When Attention Betrays: Erasing Backdoor Attacks in Robotic Policies by Reconstructing Visual Tokens
Feb 03, 2026Downstream fine-tuning of vision-language-action (VLA) models enhances robotics, yet exposes the pipeline to backdoor risks. Attackers can pretrain VLAs on poisoned data to implant backdoors that remain stealthy but can trigger harmful behavior during inference. However, existing defenses either lack mechanistic insight into multimodal backdoors or impose prohibitive computational costs via full-model retraining. To this end, we uncover a deep-layer attention grabbing mechanism: backdoors redirect late-stage attention and form compact embedding clusters near the clean manifold. Leveraging this insight, we introduce Bera, a test-time backdoor erasure framework that detects tokens with anomalous attention via latent-space localization, masks suspicious regions using deep-layer cues, and reconstructs a trigger-free image to break the trigger-unsafe-action mapping while restoring correct behavior. Unlike prior defenses, Bera requires neither retraining of VLAs nor any changes to the training pipeline. Extensive experiments across multiple embodied platforms and tasks show that Bera effectively maintains nominal performance, significantly reduces attack success rates, and consistently restores benign behavior from backdoored outputs, thereby offering a robust and practical defense mechanism for securing robotic systems.
Generalizable Geometric Prior and Recurrent Spiking Feature Learning for Humanoid Robot Manipulation
Jan 13, 2026Humanoid robot manipulation is a crucial research area for executing diverse human-level tasks, involving high-level semantic reasoning and low-level action generation. However, precise scene understanding and sample-efficient learning from human demonstrations remain critical challenges, severely hindering the applicability and generalizability of existing frameworks. This paper presents a novel RGMP-S, Recurrent Geometric-prior Multimodal Policy with Spiking features, facilitating both high-level skill reasoning and data-efficient motion synthesis. To ground high-level reasoning in physical reality, we leverage lightweight 2D geometric inductive biases to enable precise 3D scene understanding within the vision-language model. Specifically, we construct a Long-horizon Geometric Prior Skill Selector that effectively aligns the semantic instructions with spatial constraints, ultimately achieving robust generalization in unseen environments. For the data efficiency issue in robotic action generation, we introduce a Recursive Adaptive Spiking Network. We parameterize robot-object interactions via recursive spiking for spatiotemporal consistency, fully distilling long-horizon dynamic features while mitigating the overfitting issue in sparse demonstration scenarios. Extensive experiments are conducted across the Maniskill simulation benchmark and three heterogeneous real-world robotic systems, encompassing a custom-developed humanoid, a desktop manipulator, and a commercial robotic platform. Empirical results substantiate the superiority of our method over state-of-the-art baselines and validate the efficacy of the proposed modules in diverse generalization scenarios. To facilitate reproducibility, the source code and video demonstrations are publicly available at https://github.com/xtli12/RGMP-S.git.
RGMP: Recurrent Geometric-prior Multimodal Policy for Generalizable Humanoid Robot Manipulation
Nov 12, 2025Humanoid robots exhibit significant potential in executing diverse human-level skills. However, current research predominantly relies on data-driven approaches that necessitate extensive training datasets to achieve robust multimodal decision-making capabilities and generalizable visuomotor control. These methods raise concerns due to the neglect of geometric reasoning in unseen scenarios and the inefficient modeling of robot-target relationships within the training data, resulting in significant waste of training resources. To address these limitations, we present the Recurrent Geometric-prior Multimodal Policy (RGMP), an end-to-end framework that unifies geometric-semantic skill reasoning with data-efficient visuomotor control. For perception capabilities, we propose the Geometric-prior Skill Selector, which infuses geometric inductive biases into a vision language model, producing adaptive skill sequences for unseen scenes with minimal spatial common sense tuning. To achieve data-efficient robotic motion synthesis, we introduce the Adaptive Recursive Gaussian Network, which parameterizes robot-object interactions as a compact hierarchy of Gaussian processes that recursively encode multi-scale spatial relationships, yielding dexterous, data-efficient motion synthesis even from sparse demonstrations. Evaluated on both our humanoid robot and desktop dual-arm robot, the RGMP framework achieves 87% task success in generalization tests and exhibits 5x greater data efficiency than the state-of-the-art model. This performance underscores its superior cross-domain generalization, enabled by geometric-semantic reasoning and recursive-Gaussion adaptation.
DexFlow: A Unified Approach for Dexterous Hand Pose Retargeting and Interaction
May 02, 2025Despite advances in hand-object interaction modeling, generating realistic dexterous manipulation data for robotic hands remains a challenge. Retargeting methods often suffer from low accuracy and fail to account for hand-object interactions, leading to artifacts like interpenetration. Generative methods, lacking human hand priors, produce limited and unnatural poses. We propose a data transformation pipeline that combines human hand and object data from multiple sources for high-precision retargeting. Our approach uses a differential loss constraint to ensure temporal consistency and generates contact maps to refine hand-object interactions. Experiments show our method significantly improves pose accuracy, naturalness, and diversity, providing a robust solution for hand-object interaction modeling.
Learning Robust Grasping Strategy Through Tactile Sensing and Adaption Skill
Nov 13, 2024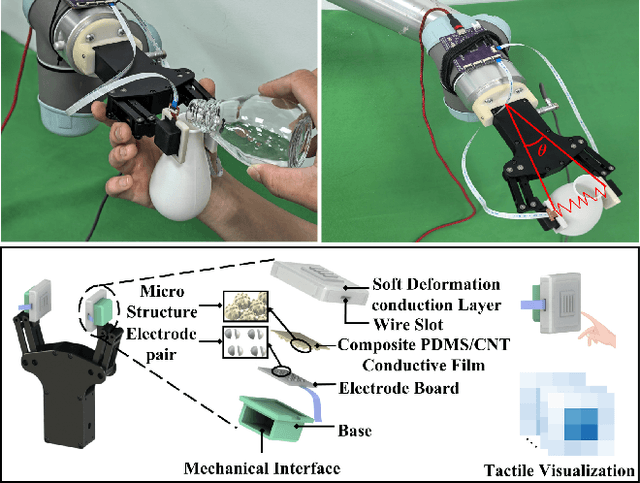
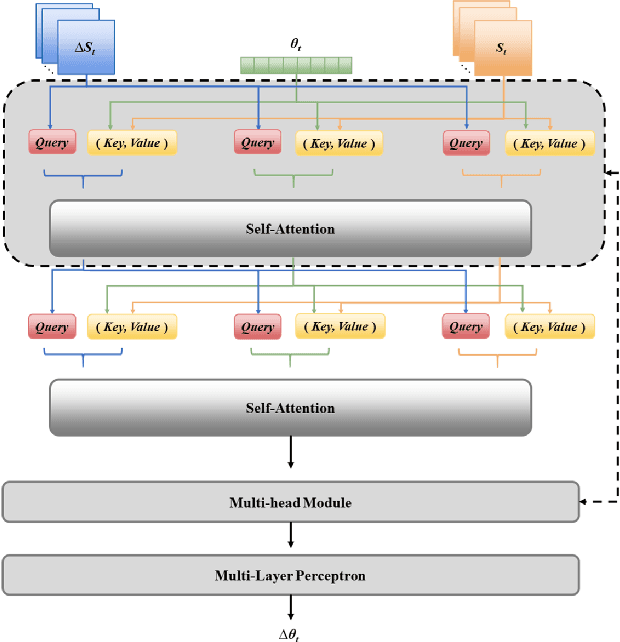
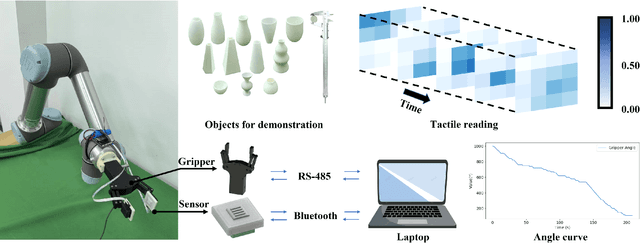
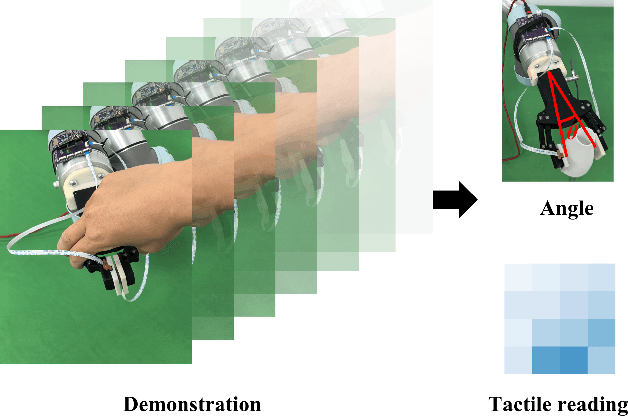
Robust grasping represents an essential task in robotics, necessitating tactile feedback and reactive grasping adjustments for robust grasping of objects. Previous research has extensively combined tactile sensing with grasping, primarily relying on rule-based approaches, frequently neglecting post-grasping difficulties such as external disruptions or inherent uncertainties of the object's physics and geometry. To address these limitations, this paper introduces an human-demonstration-based adaptive grasping policy base on tactile, which aims to achieve robust gripping while resisting disturbances to maintain grasp stability. Our trained model generalizes to daily objects with seven different sizes, shapes, and textures. Experimental results demonstrate that our method performs well in dynamic and force interaction tasks and exhibits excellent generalization ability.
Guided Self-attention: Find the Generalized Necessarily Distinct Vectors for Grain Size Grading
Oct 08, 2024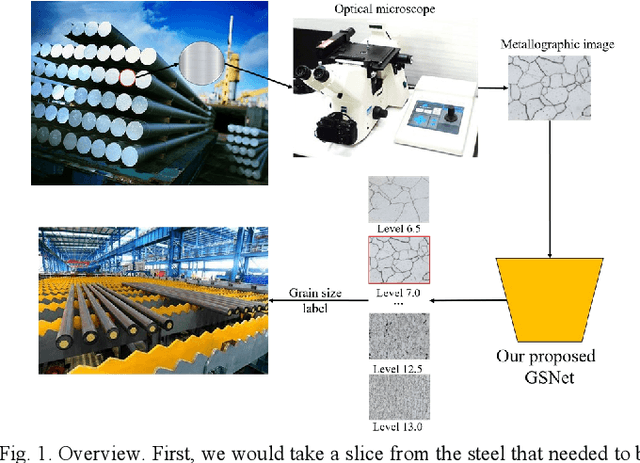

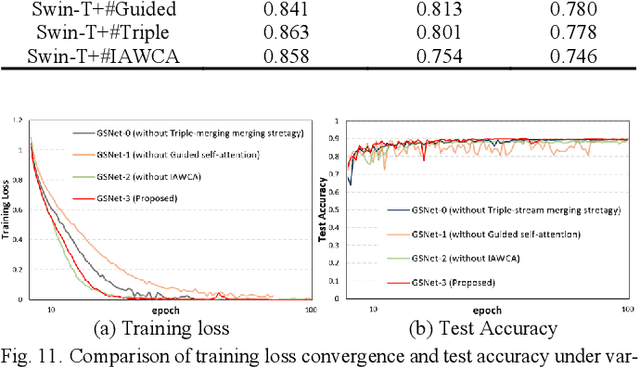

With the development of steel materials, metallographic analysis has become increasingly important. Unfortunately, grain size analysis is a manual process that requires experts to evaluate metallographic photographs, which is unreliable and time-consuming. To resolve this problem, we propose a novel classifi-cation method based on deep learning, namely GSNets, a family of hybrid models which can effectively introduce guided self-attention for classifying grain size. Concretely, we build our models from three insights:(1) Introducing our novel guided self-attention module can assist the model in finding the generalized necessarily distinct vectors capable of retaining intricate rela-tional connections and rich local feature information; (2) By improving the pixel-wise linear independence of the feature map, the highly condensed semantic representation will be captured by the model; (3) Our novel triple-stream merging module can significantly improve the generalization capability and efficiency of the model. Experiments show that our GSNet yields a classifi-cation accuracy of 90.1%, surpassing the state-of-the-art Swin Transformer V2 by 1.9% on the steel grain size dataset, which comprises 3,599 images with 14 grain size levels. Furthermore, we intuitively believe our approach is applicable to broader ap-plications like object detection and semantic segmentation.
Learning the Generalizable Manipulation Skills on Soft-body Tasks via Guided Self-attention Behavior Cloning Policy
Oct 08, 2024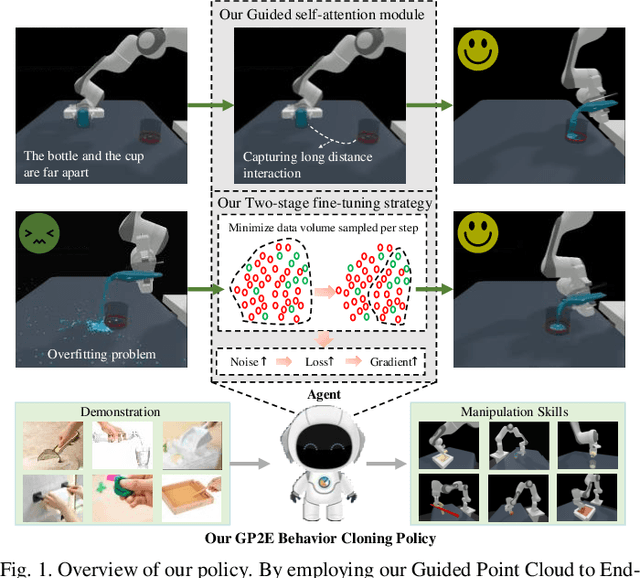
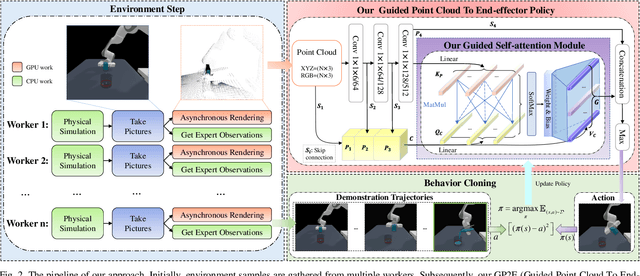

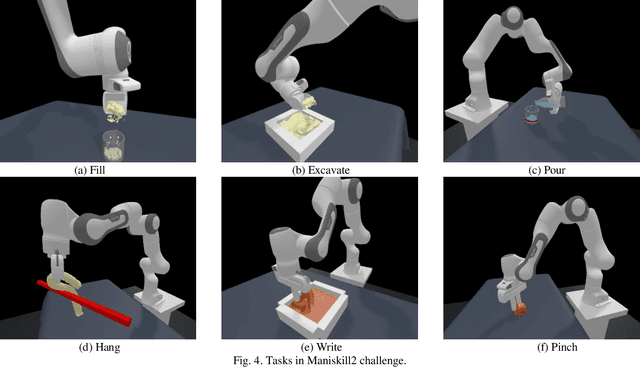
Embodied AI represents a paradigm in AI research where artificial agents are situated within and interact with physical or virtual environments. Despite the recent progress in Embodied AI, it is still very challenging to learn the generalizable manipulation skills that can handle large deformation and topological changes on soft-body objects, such as clay, water, and soil. In this work, we proposed an effective policy, namely GP2E behavior cloning policy, which can guide the agent to learn the generalizable manipulation skills from soft-body tasks, including pouring, filling, hanging, excavating, pinching, and writing. Concretely, we build our policy from three insights:(1) Extracting intricate semantic features from point cloud data and seamlessly integrating them into the robot's end-effector frame; (2) Capturing long-distance interactions in long-horizon tasks through the incorporation of our guided self-attention module; (3) Mitigating overfitting concerns and facilitating model convergence to higher accuracy levels via the introduction of our two-stage fine-tuning strategy. Through extensive experiments, we demonstrate the effectiveness of our approach by achieving the 1st prize in the soft-body track of the ManiSkill2 Challenge at the CVPR 2023 4th Embodied AI workshop. Our findings highlight the potential of our method to improve the generalization abilities of Embodied AI models and pave the way for their practical applications in real-world scenarios.