 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence
Sep 03, 2025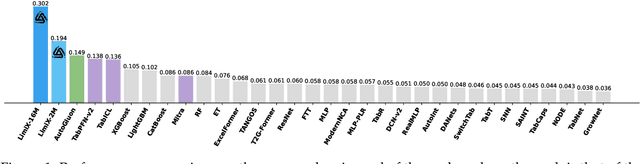
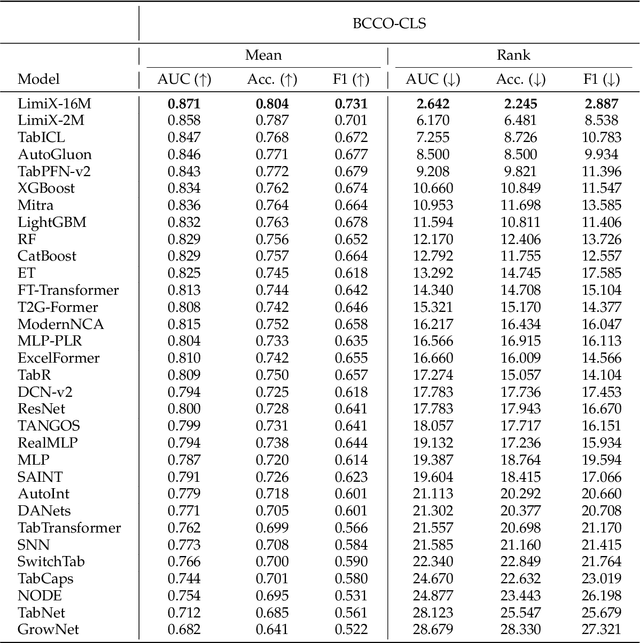
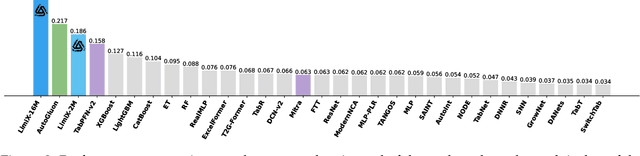
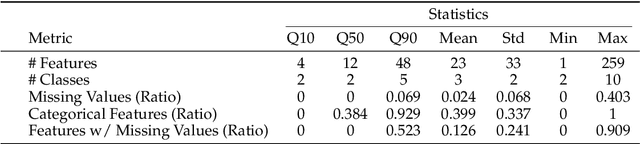
We argue that progress toward general intelligence requires complementary foundation models grounded in language, the physical world, and structured data. This report presents LimiX, the first installment of our large structured-data models (LDMs). LimiX treats structured data as a joint distribution over variables and missingness, thus capable of addressing a wide range of tabular tasks through query-based conditional prediction via a single model. LimiX is pretrained using masked joint-distribution modeling with an episodic, context-conditional objective, where the model predicts for query subsets conditioned on dataset-specific contexts, supporting rapid, training-free adaptation at inference. We evaluate LimiX across 10 large structured-data benchmarks with broad regimes of sample size, feature dimensionality, class number, categorical-to-numerical feature ratio, missingness, and sample-to-feature ratios. With a single model and a unified interface, LimiX consistently surpasses strong baselines including gradient-boosting trees, deep tabular networks, recent tabular foundation models, and automated ensembles, as shown in Figure 1 and Figure 2. The superiority holds across a wide range of tasks, such as classification, regression, missing value imputation, and data generation, often by substantial margins, while avoiding task-specific architectures or bespoke training per task. All LimiX models are publicly accessible under Apache 2.0.
Guided Self-attention: Find the Generalized Necessarily Distinct Vectors for Grain Size Grading
Oct 08, 2024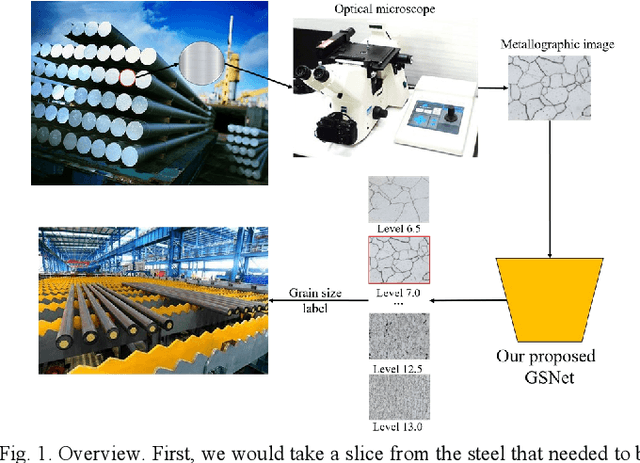

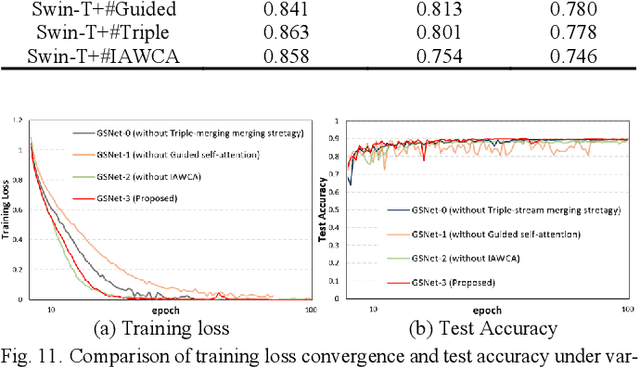

With the development of steel materials, metallographic analysis has become increasingly important. Unfortunately, grain size analysis is a manual process that requires experts to evaluate metallographic photographs, which is unreliable and time-consuming. To resolve this problem, we propose a novel classifi-cation method based on deep learning, namely GSNets, a family of hybrid models which can effectively introduce guided self-attention for classifying grain size. Concretely, we build our models from three insights:(1) Introducing our novel guided self-attention module can assist the model in finding the generalized necessarily distinct vectors capable of retaining intricate rela-tional connections and rich local feature information; (2) By improving the pixel-wise linear independence of the feature map, the highly condensed semantic representation will be captured by the model; (3) Our novel triple-stream merging module can significantly improve the generalization capability and efficiency of the model. Experiments show that our GSNet yields a classifi-cation accuracy of 90.1%, surpassing the state-of-the-art Swin Transformer V2 by 1.9% on the steel grain size dataset, which comprises 3,599 images with 14 grain size levels. Furthermore, we intuitively believe our approach is applicable to broader ap-plications like object detection and semantic segmentation.
Learning the Generalizable Manipulation Skills on Soft-body Tasks via Guided Self-attention Behavior Cloning Policy
Oct 08, 2024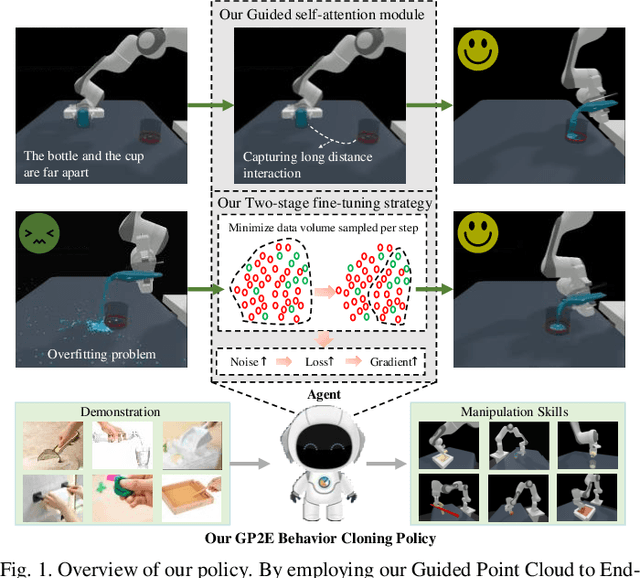
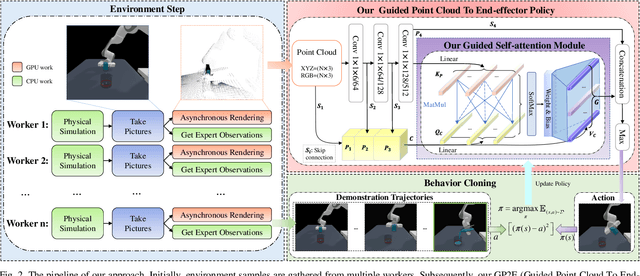

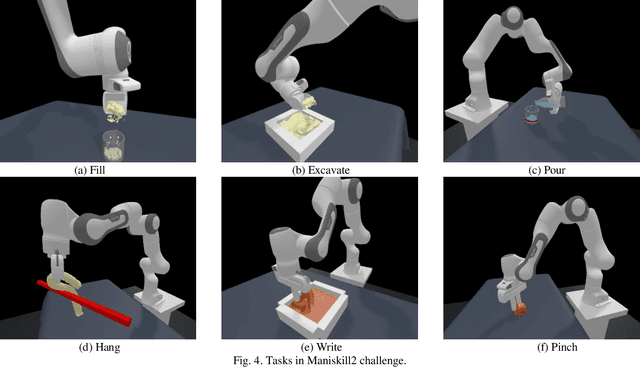
Embodied AI represents a paradigm in AI research where artificial agents are situated within and interact with physical or virtual environments. Despite the recent progress in Embodied AI, it is still very challenging to learn the generalizable manipulation skills that can handle large deformation and topological changes on soft-body objects, such as clay, water, and soil. In this work, we proposed an effective policy, namely GP2E behavior cloning policy, which can guide the agent to learn the generalizable manipulation skills from soft-body tasks, including pouring, filling, hanging, excavating, pinching, and writing. Concretely, we build our policy from three insights:(1) Extracting intricate semantic features from point cloud data and seamlessly integrating them into the robot's end-effector frame; (2) Capturing long-distance interactions in long-horizon tasks through the incorporation of our guided self-attention module; (3) Mitigating overfitting concerns and facilitating model convergence to higher accuracy levels via the introduction of our two-stage fine-tuning strategy. Through extensive experiments, we demonstrate the effectiveness of our approach by achieving the 1st prize in the soft-body track of the ManiSkill2 Challenge at the CVPR 2023 4th Embodied AI workshop. Our findings highlight the potential of our method to improve the generalization abilities of Embodied AI models and pave the way for their practical applications in real-world scenarios.
A Two-stage Fine-tuning Strategy for Generalizable Manipulation Skill of Embodied AI
Jul 21, 2023The advent of Chat-GPT has led to a surge of interest in Embodied AI. However, many existing Embodied AI models heavily rely on massive interactions with training environments, which may not be practical in real-world situations. To this end, the Maniskill2 has introduced a full-physics simulation benchmark for manipulating various 3D objects. This benchmark enables agents to be trained using diverse datasets of demonstrations and evaluates their ability to generalize to unseen scenarios in testing environments. In this paper, we propose a novel two-stage fine-tuning strategy that aims to further enhance the generalization capability of our model based on the Maniskill2 benchmark. Through extensive experiments, we demonstrate the effectiveness of our approach by achieving the 1st prize in all three tracks of the ManiSkill2 Challenge. Our findings highlight the potential of our method to improve the generalization abilities of Embodied AI models and pave the way for their ractical applications in real-world scenarios. All codes and models of our solution is available at https://github.com/xtli12/GXU-LIPE.git
A Weakly-Supervised Depth Estimation Network Using Attention Mechanism
Jul 10, 2021
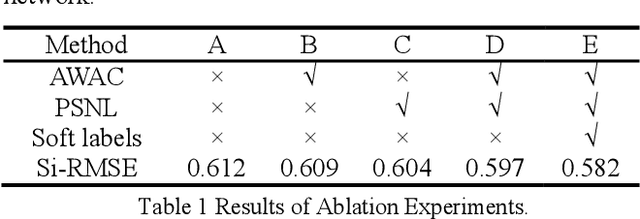
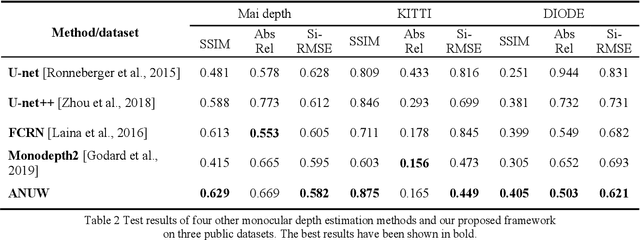
Monocular depth estimation (MDE) is a fundamental task in many applications such as scene understanding and reconstruction. However, most of the existing methods rely on accurately labeled datasets. A weakly-supervised framework based on attention nested U-net (ANU) named as ANUW is introduced in this paper for cases with wrong labels. The ANUW is trained end-to-end to convert an input single RGB image into a depth image. It consists of a dense residual network structure, an adaptive weight channel attention (AWCA) module, a patch second non-local (PSNL) module and a soft label generation method. The dense residual network is the main body of the network to encode and decode the input. The AWCA module can adaptively adjust the channel weights to extract important features. The PSNL module implements the spatial attention mechanism through a second-order non-local method. The proposed soft label generation method uses the prior knowledge of the dataset to produce soft labels to replace false ones. The proposed ANUW is trained on a defective monocular depth dataset and the trained model is tested on three public datasets, and the results demonstrate the superiority of ANUW in comparison with the state-of-the-art MDE methods.