 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Weakly-Supervised Depth Estimation Network Using Attention Mechanism
Paper and Code
Jul 10, 2021
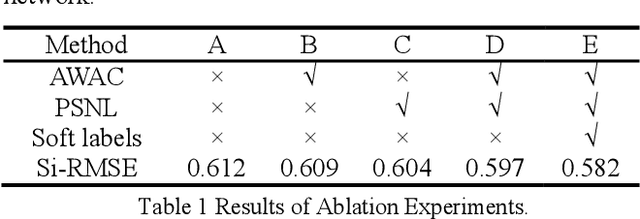
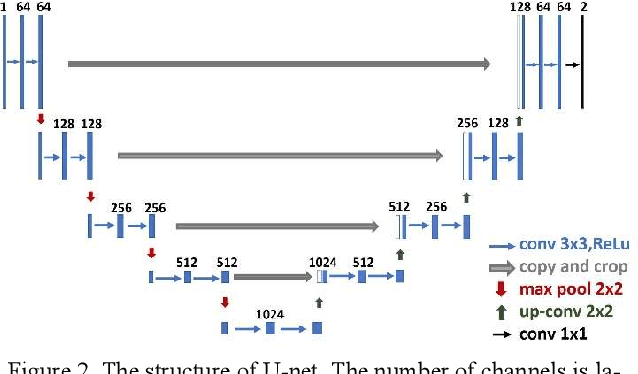
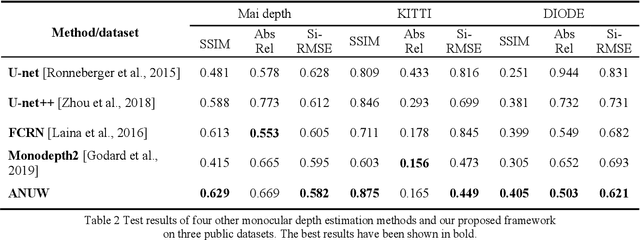
Monocular depth estimation (MDE) is a fundamental task in many applications such as scene understanding and reconstruction. However, most of the existing methods rely on accurately labeled datasets. A weakly-supervised framework based on attention nested U-net (ANU) named as ANUW is introduced in this paper for cases with wrong labels. The ANUW is trained end-to-end to convert an input single RGB image into a depth image. It consists of a dense residual network structure, an adaptive weight channel attention (AWCA) module, a patch second non-local (PSNL) module and a soft label generation method. The dense residual network is the main body of the network to encode and decode the input. The AWCA module can adaptively adjust the channel weights to extract important features. The PSNL module implements the spatial attention mechanism through a second-order non-local method. The proposed soft label generation method uses the prior knowledge of the dataset to produce soft labels to replace false ones. The proposed ANUW is trained on a defective monocular depth dataset and the trained model is tested on three public datasets, and the results demonstrate the superiority of ANUW in comparison with the state-of-the-art MDE methods.