 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Generalizable Manipulation Skills on Soft-body Tasks via Guided Self-attention Behavior Cloning Policy
Oct 08, 2024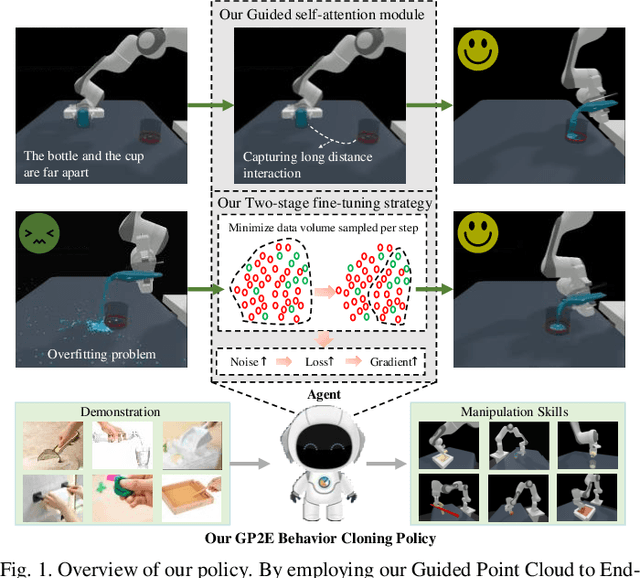
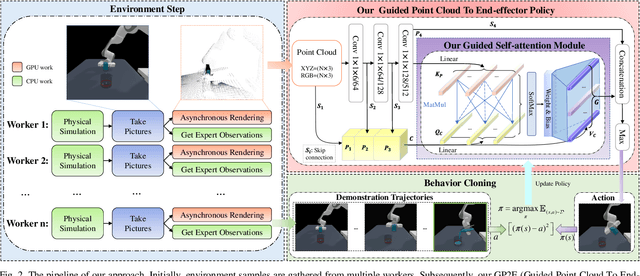

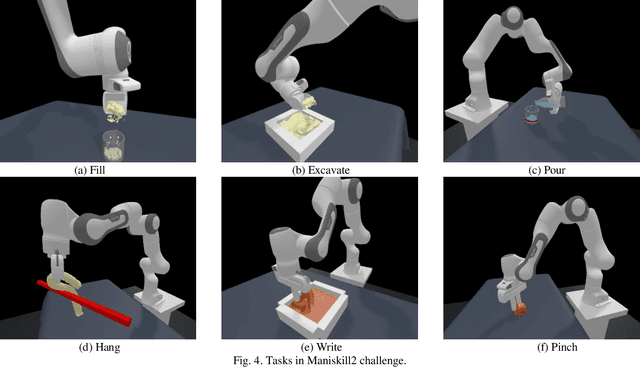
Embodied AI represents a paradigm in AI research where artificial agents are situated within and interact with physical or virtual environments. Despite the recent progress in Embodied AI, it is still very challenging to learn the generalizable manipulation skills that can handle large deformation and topological changes on soft-body objects, such as clay, water, and soil. In this work, we proposed an effective policy, namely GP2E behavior cloning policy, which can guide the agent to learn the generalizable manipulation skills from soft-body tasks, including pouring, filling, hanging, excavating, pinching, and writing. Concretely, we build our policy from three insights:(1) Extracting intricate semantic features from point cloud data and seamlessly integrating them into the robot's end-effector frame; (2) Capturing long-distance interactions in long-horizon tasks through the incorporation of our guided self-attention module; (3) Mitigating overfitting concerns and facilitating model convergence to higher accuracy levels via the introduction of our two-stage fine-tuning strategy. Through extensive experiments, we demonstrate the effectiveness of our approach by achieving the 1st prize in the soft-body track of the ManiSkill2 Challenge at the CVPR 2023 4th Embodied AI workshop. Our findings highlight the potential of our method to improve the generalization abilities of Embodied AI models and pave the way for their practical applications in real-world scenarios.
3D Hand Reconstruction via Aggregating Intra and Inter Graphs Guided by Prior Knowledge for Hand-Object Interaction Scenario
Mar 04, 2024Recently, 3D hand reconstruction has gained more attention in human-computer cooperation, especially for hand-object interaction scenario. However, it still remains huge challenge due to severe hand-occlusion caused by interaction, which contain the balance of accuracy and physical plausibility, highly nonlinear mapping of model parameters and occlusion feature enhancement. To overcome these issues, we propose a 3D hand reconstruction network combining the benefits of model-based and model-free approaches to balance accuracy and physical plausibility for hand-object interaction scenario. Firstly, we present a novel MANO pose parameters regression module from 2D joints directly, which avoids the process of highly nonlinear mapping from abstract image feature and no longer depends on accurate 3D joints. Moreover, we further propose a vertex-joint mutual graph-attention model guided by MANO to jointly refine hand meshes and joints, which model the dependencies of vertex-vertex and joint-joint and capture the correlation of vertex-joint for aggregating intra-graph and inter-graph node features respectively. The experimental results demonstrate that our method achieves a competitive performance on recently benchmark datasets HO3DV2 and Dex-YCB, and outperforms all only model-base approaches and model-free approaches.
OppLoD: the Opponency based Looming Detector, Model Extension of Looming Sensitivity from LGMD to LPLC2
Feb 10, 2023



Looming detection plays an important role in insect collision prevention systems. As a vital capability evolutionary survival, it has been extensively studied in neuroscience and is attracting increasing research interest in robotics due to its close relationship with collision detection and navigation. Visual cues such as angular size, angular velocity, and expansion have been widely studied for looming detection by means of optic flow or elementary neural computing research. However, a critical visual motion cue has been long neglected because it is so easy to be confused with expansion, that is radial-opponent-motion (ROM). Recent research on the discovery of LPLC2, a ROM-sensitive neuron in Drosophila, has revealed its ultra-selectivity because it only responds to stimuli with focal, outward movement. This characteristic of ROM-sensitivity is consistent with the demand for collision detection because it is strongly associated with danger looming that is moving towards the center of the observer. Thus, we hope to extend the well-studied neural model of the lobula giant movement detector (LGMD) with ROM-sensibility in order to enhance robustness and accuracy at the same time. In this paper, we investigate the potential to extend an image velocity-based looming detector, the lobula giant movement detector (LGMD), with ROM-sensibility. To achieve this, we propose the mathematical definition of ROM and its main property, the radial motion opponency (RMO). Then, a synaptic neuropile that analogizes the synaptic processing of LPLC2 is proposed in the form of lateral inhibition and attention. Thus, our proposed model is the first to perform both image velocity selectivity and ROM sensitivity. Systematic experiments are conducted to exhibit the huge potential of the proposed bio-inspired looming detector.
A Weakly-Supervised Depth Estimation Network Using Attention Mechanism
Jul 10, 2021
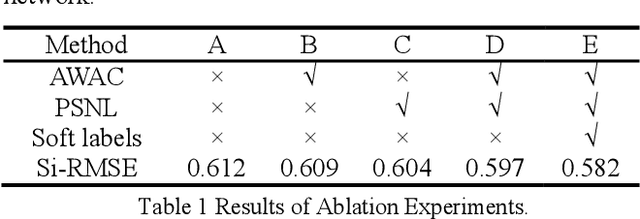
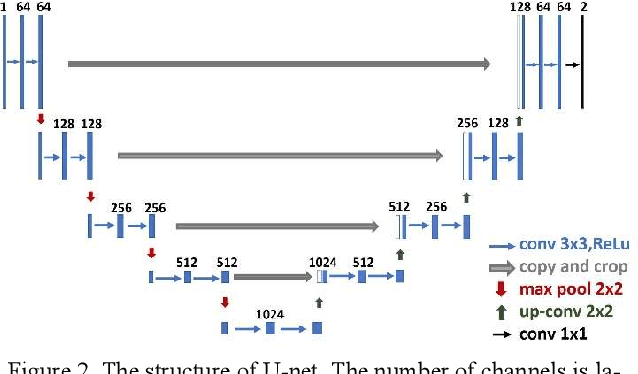
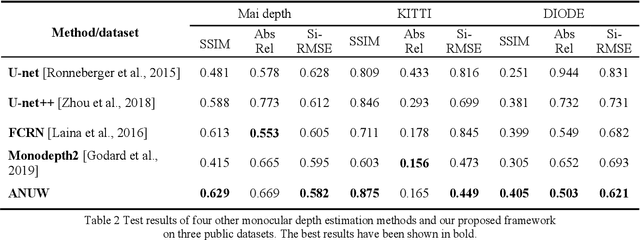
Monocular depth estimation (MDE) is a fundamental task in many applications such as scene understanding and reconstruction. However, most of the existing methods rely on accurately labeled datasets. A weakly-supervised framework based on attention nested U-net (ANU) named as ANUW is introduced in this paper for cases with wrong labels. The ANUW is trained end-to-end to convert an input single RGB image into a depth image. It consists of a dense residual network structure, an adaptive weight channel attention (AWCA) module, a patch second non-local (PSNL) module and a soft label generation method. The dense residual network is the main body of the network to encode and decode the input. The AWCA module can adaptively adjust the channel weights to extract important features. The PSNL module implements the spatial attention mechanism through a second-order non-local method. The proposed soft label generation method uses the prior knowledge of the dataset to produce soft labels to replace false ones. The proposed ANUW is trained on a defective monocular depth dataset and the trained model is tested on three public datasets, and the results demonstrate the superiority of ANUW in comparison with the state-of-the-art MDE methods.