 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearch, Applications and Prospects of Event-Based Pedestrian Detection: A Survey
Jul 05, 2024



Event-based cameras, inspired by the biological retina, have evolved into cutting-edge sensors distinguished by their minimal power requirements, negligible latency, superior temporal resolution, and expansive dynamic range. At present, cameras used for pedestrian detection are mainly frame-based imaging sensors, which have suffered from lethargic response times and hefty data redundancy. In contrast, event-based cameras address these limitations by eschewing extraneous data transmissions and obviating motion blur in high-speed imaging scenarios. On pedestrian detection via event-based cameras, this paper offers an exhaustive review of research and applications particularly in the autonomous driving context. Through methodically scrutinizing relevant literature, the paper outlines the foundational principles, developmental trajectory, and the comparative merits and demerits of eventbased detection relative to traditional frame-based methodologies. This review conducts thorough analyses of various event stream inputs and their corresponding network models to evaluate their applicability across diverse operational environments. It also delves into pivotal elements such as crucial datasets and data acquisition techniques essential for advancing this technology, as well as advanced algorithms for processing event stream data. Culminating with a synthesis of the extant landscape, the review accentuates the unique advantages and persistent challenges inherent in event-based pedestrian detection, offering a prognostic view on potential future developments in this fast-progressing field.
A Weakly-Supervised Depth Estimation Network Using Attention Mechanism
Jul 10, 2021
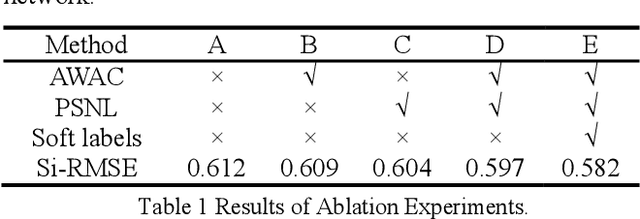
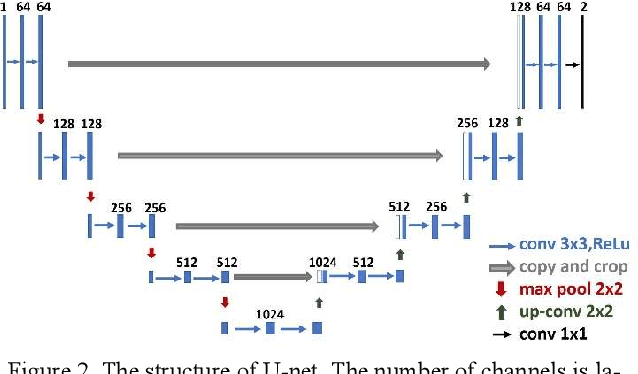
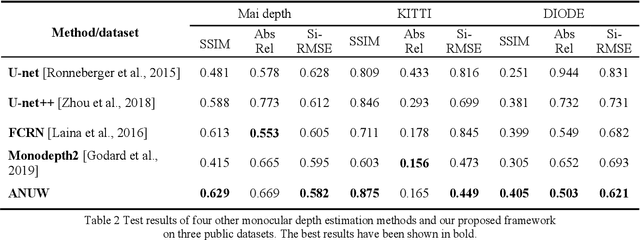
Monocular depth estimation (MDE) is a fundamental task in many applications such as scene understanding and reconstruction. However, most of the existing methods rely on accurately labeled datasets. A weakly-supervised framework based on attention nested U-net (ANU) named as ANUW is introduced in this paper for cases with wrong labels. The ANUW is trained end-to-end to convert an input single RGB image into a depth image. It consists of a dense residual network structure, an adaptive weight channel attention (AWCA) module, a patch second non-local (PSNL) module and a soft label generation method. The dense residual network is the main body of the network to encode and decode the input. The AWCA module can adaptively adjust the channel weights to extract important features. The PSNL module implements the spatial attention mechanism through a second-order non-local method. The proposed soft label generation method uses the prior knowledge of the dataset to produce soft labels to replace false ones. The proposed ANUW is trained on a defective monocular depth dataset and the trained model is tested on three public datasets, and the results demonstrate the superiority of ANUW in comparison with the state-of-the-art MDE methods.