 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESPERANTO: Evaluating Synthesized Phrases to Enhance Robustness in AI Detection for Text Origination
Sep 22, 2024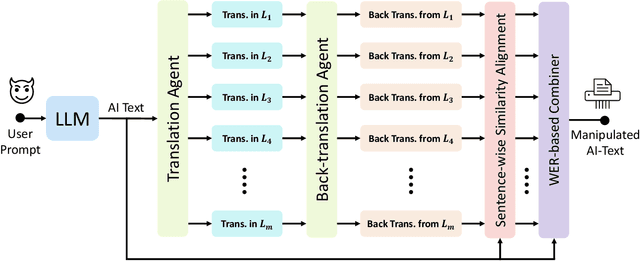
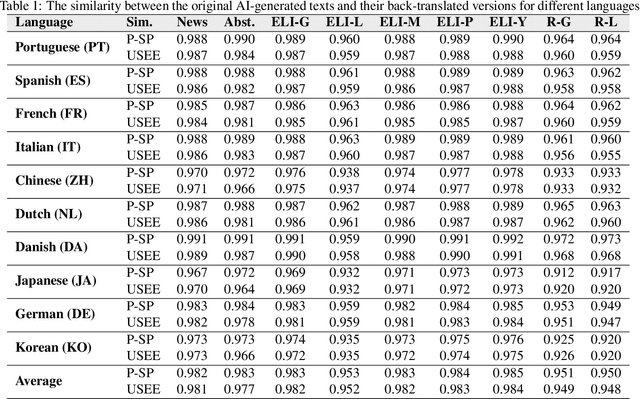

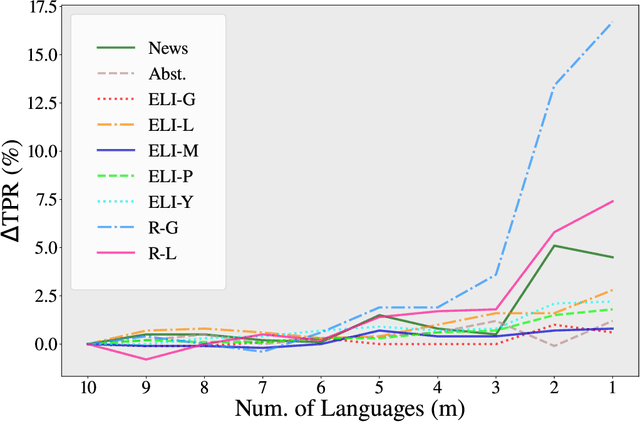
While large language models (LLMs) exhibit significant utility across various domains, they simultaneously are susceptible to exploitation for unethical purposes, including academic misconduct and dissemination of misinformation. Consequently, AI-generated text detection systems have emerged as a countermeasure. However, these detection mechanisms demonstrate vulnerability to evasion techniques and lack robustness against textual manipulations. This paper introduces back-translation as a novel technique for evading detection, underscoring the need to enhance the robustness of current detection systems. The proposed method involves translating AI-generated text through multiple languages before back-translating to English. We present a model that combines these back-translated texts to produce a manipulated version of the original AI-generated text. Our findings demonstrate that the manipulated text retains the original semantics while significantly reducing the true positive rate (TPR) of existing detection methods. We evaluate this technique on nine AI detectors, including six open-source and three proprietary systems, revealing their susceptibility to back-translation manipulation. In response to the identified shortcomings of existing AI text detectors, we present a countermeasure to improve the robustness against this form of manipulation. Our results indicate that the TPR of the proposed method declines by only 1.85% after back-translation manipulation. Furthermore, we build a large dataset of 720k texts using eight different LLMs. Our dataset contains both human-authored and LLM-generated texts in various domains and writing styles to assess the performance of our method and existing detectors. This dataset is publicly shared for the benefit of the research community.
While GitHub Copilot Excels at Coding, Does It Ensure Responsible Output?
Aug 20, 2024The rapid development of large language models (LLMs) has significantly advanced code completion capabilities, giving rise to a new generation of LLM-based Code Completion Tools (LCCTs). Unlike general-purpose LLMs, these tools possess unique workflows, integrating multiple information sources as input and prioritizing code suggestions over natural language interaction, which introduces distinct security challenges. Additionally, LCCTs often rely on proprietary code datasets for training, raising concerns about the potential exposure of sensitive data. This paper exploits these distinct characteristics of LCCTs to develop targeted attack methodologies on two critical security risks: jailbreaking and training data extraction attacks. Our experimental results expose significant vulnerabilities within LCCTs, including a 99.4% success rate in jailbreaking attacks on GitHub Copilot and a 46.3% success rate on Amazon Q. Furthermore, We successfully extracted sensitive user data from GitHub Copilot, including 54 real email addresses and 314 physical addresses associated with GitHub usernames. Our study also demonstrates that these code-based attack methods are effective against general-purpose LLMs, such as the GPT series, highlighting a broader security misalignment in the handling of code by modern LLMs. These findings underscore critical security challenges associated with LCCTs and suggest essential directions for strengthening their security frameworks. The example code and attack samples from our research are provided at https://github.com/Sensente/Security-Attacks-on-LCCTs.
Research, Applications and Prospects of Event-Based Pedestrian Detection: A Survey
Jul 05, 2024



Event-based cameras, inspired by the biological retina, have evolved into cutting-edge sensors distinguished by their minimal power requirements, negligible latency, superior temporal resolution, and expansive dynamic range. At present, cameras used for pedestrian detection are mainly frame-based imaging sensors, which have suffered from lethargic response times and hefty data redundancy. In contrast, event-based cameras address these limitations by eschewing extraneous data transmissions and obviating motion blur in high-speed imaging scenarios. On pedestrian detection via event-based cameras, this paper offers an exhaustive review of research and applications particularly in the autonomous driving context. Through methodically scrutinizing relevant literature, the paper outlines the foundational principles, developmental trajectory, and the comparative merits and demerits of eventbased detection relative to traditional frame-based methodologies. This review conducts thorough analyses of various event stream inputs and their corresponding network models to evaluate their applicability across diverse operational environments. It also delves into pivotal elements such as crucial datasets and data acquisition techniques essential for advancing this technology, as well as advanced algorithms for processing event stream data. Culminating with a synthesis of the extant landscape, the review accentuates the unique advantages and persistent challenges inherent in event-based pedestrian detection, offering a prognostic view on potential future developments in this fast-progressing field.
QAQ: Quality Adaptive Quantization for LLM KV Cache
Mar 07, 2024



The emergence of LLMs has ignited a fresh surge of breakthroughs in NLP applications, particularly in domains such as question-answering systems and text generation. As the need for longer context grows, a significant bottleneck in model deployment emerges due to the linear expansion of the Key-Value (KV) cache with the context length. Existing methods primarily rely on various hypotheses, such as sorting the KV cache based on attention scores for replacement or eviction, to compress the KV cache and improve model throughput. However, heuristics used by these strategies may wrongly evict essential KV cache, which can significantly degrade model performance. In this paper, we propose QAQ, a Quality Adaptive Quantization scheme for the KV cache. We theoretically demonstrate that key cache and value cache exhibit distinct sensitivities to quantization, leading to the formulation of separate quantization strategies for their non-uniform quantization. Through the integration of dedicated outlier handling, as well as an improved attention-aware approach, QAQ achieves up to 10x the compression ratio of the KV cache size with a neglectable impact on model performance. QAQ significantly reduces the practical hurdles of deploying LLMs, opening up new possibilities for longer-context applications. The code is available at github.com/ClubieDong/KVCacheQuantization.
Central Similarity Multi-View Hashing for Multimedia Retrieval
Aug 26, 2023



Hash representation learning of multi-view heterogeneous data is the key to improving the accuracy of multimedia retrieval. However, existing methods utilize local similarity and fall short of deeply fusing the multi-view features, resulting in poor retrieval accuracy. Current methods only use local similarity to train their model. These methods ignore global similarity. Furthermore, most recent works fuse the multi-view features via a weighted sum or concatenation. We contend that these fusion methods are insufficient for capturing the interaction between various views. We present a novel Central Similarity Multi-View Hashing (CSMVH) method to address the mentioned problems. Central similarity learning is used for solving the local similarity problem, which can utilize the global similarity between the hash center and samples. We present copious empirical data demonstrating the superiority of gate-based fusion over conventional approaches. On the MS COCO and NUS-WIDE, the proposed CSMVH performs better than the state-of-the-art methods by a large margin (up to 11.41% mean Average Precision (mAP) improvement).
Learning Autonomous Ultrasound via Latent Task Representation and Robotic Skills Adaptation
Jul 25, 2023As medical ultrasound is becoming a prevailing examination approach nowadays, robotic ultrasound systems can facilitate the scanning process and prevent professional sonographers from repetitive and tedious work. Despite the recent progress, it is still a challenge to enable robots to autonomously accomplish the ultrasound examination, which is largely due to the lack of a proper task representation method, and also an adaptation approach to generalize learned skills across different patients. To solve these problems, we propose the latent task representation and the robotic skills adaptation for autonomous ultrasound in this paper. During the offline stage, the multimodal ultrasound skills are merged and encapsulated into a low-dimensional probability model through a fully self-supervised framework, which takes clinically demonstrated ultrasound images, probe orientations, and contact forces into account. During the online stage, the probability model will select and evaluate the optimal prediction. For unstable singularities, the adaptive optimizer fine-tunes them to near and stable predictions in high-confidence regions. Experimental results show that the proposed approach can generate complex ultrasound strategies for diverse populations and achieve significantly better quantitative results than our previous method.
W2KPE: Keyphrase Extraction with Word-Word Relation
Mar 22, 2023

This paper describes our submission to ICASSP 2023 MUG Challenge Track 4, Keyphrase Extraction, which aims to extract keyphrases most relevant to the conference theme from conference materials. We model the challenge as a single-class Named Entity Recognition task and developed techniques for better performance on the challenge: For the data preprocessing, we encode the split keyphrases after word segmentation. In addition, we increase the amount of input information that the model can accept at one time by fusing multiple preprocessed sentences into one segment. We replace the loss function with the multi-class focal loss to address the sparseness of keyphrases. Besides, we score each appearance of keyphrases and add an extra output layer to fit the score to rank keyphrases. Exhaustive evaluations are performed to find the best combination of the word segmentation tool, the pre-trained embedding model, and the corresponding hyperparameters. With these proposals, we scored 45.04 on the final test set.
Residual Recurrent CRNN for End-to-End Optical Music Recognition on Monophonic Scores
Oct 26, 2020



Optical Music Recognition is a field that attempts to extract digital information from images of either the printed music scores or the handwritten music scores. One of the challenges of the Optical Music Recognition task is to transcript the symbols of the camera-captured images into digital music notations. Previous end-to-end model, based on deep learning, was developed as a Convolutional Recurrent Neural Network. However, it does not explore sufficient contextual information from full scales and there is still a large room for improvement. In this paper, we propose an innovative end-to-end framework that combines a block of Residual Recurrent Convolutional Neural Network with a recurrent Encoder-Decoder network to map a sequence of monophonic music symbols corresponding to the notations present in the image. The Residual Recurrent Convolutional block can improve the ability of the model to enrich the context information while the number of parameter will not be increasing. The experiment results were benchmarked against a publicly available dataset called CAMERA-PRIMUS. We evaluate the performances of our model on both the images with ideal conditions and that with non-ideal conditions. The experiments show that our approach surpass the state-of-the-art end-to-end method using Convolutional Recurrent Neural Network.
ST-MNIST -- The Spiking Tactile MNIST Neuromorphic Dataset
May 08, 2020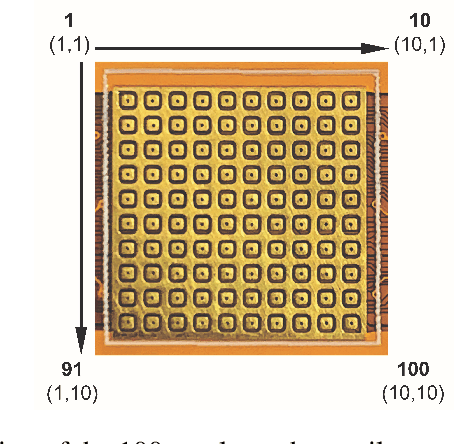
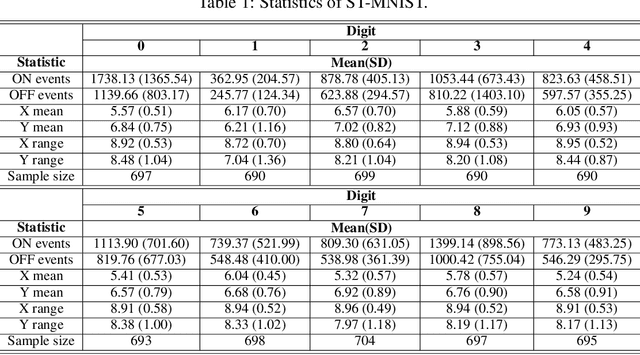
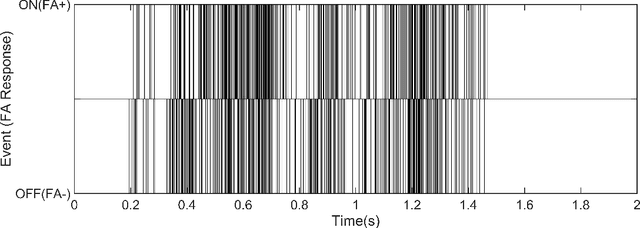
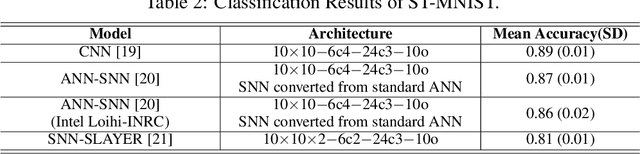
Tactile sensing is an essential modality for smart robots as it enables them to interact flexibly with physical objects in their environment. Recent advancements in electronic skins have led to the development of data-driven machine learning methods that exploit this important sensory modality. However, current datasets used to train such algorithms are limited to standard synchronous tactile sensors. There is a dearth of neuromorphic event-based tactile datasets, principally due to the scarcity of large-scale event-based tactile sensors. Having such datasets is crucial for the development and evaluation of new algorithms that process spatio-temporal event-based data. For example, evaluating spiking neural networks on conventional frame-based datasets is considered sub-optimal. Here, we debut a novel neuromorphic Spiking Tactile MNIST (ST-MNIST) dataset, which comprises handwritten digits obtained by human participants writing on a neuromorphic tactile sensor array. We also describe an initial effort to evaluate our ST-MNIST dataset using existing artificial and spiking neural network models. The classification accuracies provided herein can serve as performance benchmarks for future work. We anticipate that our ST-MNIST dataset will be of interest and useful to the neuromorphic and robotics research communities.