 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Recurrent CRNN for End-to-End Optical Music Recognition on Monophonic Scores
Oct 26, 2020



Optical Music Recognition is a field that attempts to extract digital information from images of either the printed music scores or the handwritten music scores. One of the challenges of the Optical Music Recognition task is to transcript the symbols of the camera-captured images into digital music notations. Previous end-to-end model, based on deep learning, was developed as a Convolutional Recurrent Neural Network. However, it does not explore sufficient contextual information from full scales and there is still a large room for improvement. In this paper, we propose an innovative end-to-end framework that combines a block of Residual Recurrent Convolutional Neural Network with a recurrent Encoder-Decoder network to map a sequence of monophonic music symbols corresponding to the notations present in the image. The Residual Recurrent Convolutional block can improve the ability of the model to enrich the context information while the number of parameter will not be increasing. The experiment results were benchmarked against a publicly available dataset called CAMERA-PRIMUS. We evaluate the performances of our model on both the images with ideal conditions and that with non-ideal conditions. The experiments show that our approach surpass the state-of-the-art end-to-end method using Convolutional Recurrent Neural Network.
Dual Encoder Fusion U-Net for Cross-manufacturer Chest X-ray Segmentation
Sep 27, 2020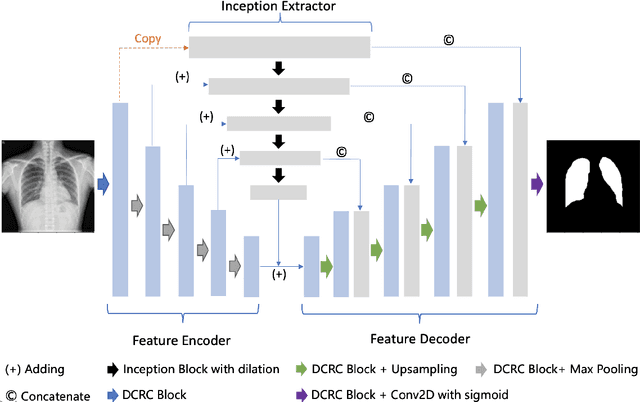
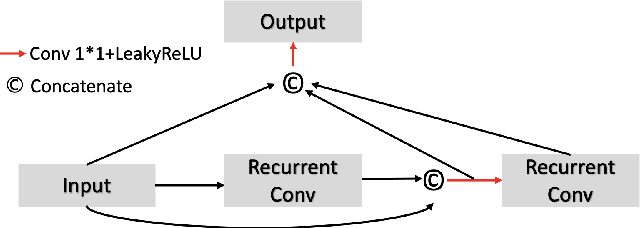
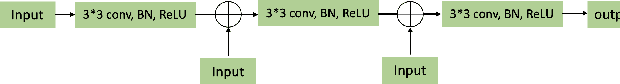
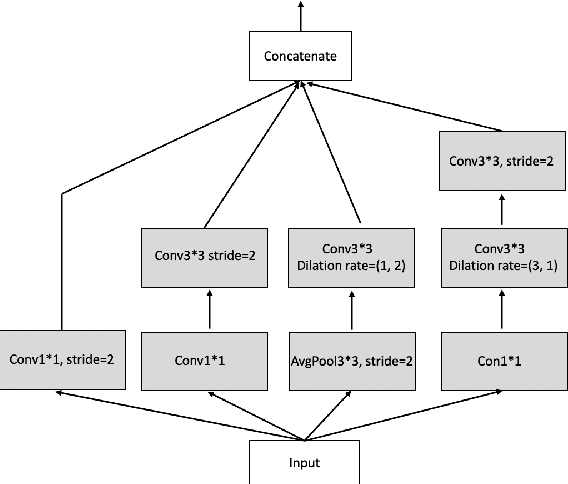
A number of methods based on the deep learning have been applied to medical image segmentation and have achieved state-of-the-art performance. Due to the importance of chest x-ray data in studying COVID-19, there is a demand for state-of-the-art models capable of precisely segmenting soft tissue on the chest x-rays before obtaining mask annotations about this sort of dataset. The dataset for exploring best pre-trained model is from Montgomery and Shenzhen hospital which had opened in 2014. The most famous technique is U-Net which has been used to many medical datasets including the Chest X-ray. However, most variant U-Nets mainly focus on extraction of contextual information and skip connection. There is still a large space for improving extraction of spatial features. In this paper, we propose a dual encoder fusion U-Net framework for Chest X-rays based on Inception Convolutional Neural Network with dilation, Densely Connected Recurrent Convolutional Neural Network, which is named DEFU-Net. The densely connected recurrent path extends the network deeper for facilitating context feature extraction. In order to increase the width of network and enrich representation of features, the inception blocks with dilation have been used. The inception blocks can capture globally and locally spatial information by various receptive fields. At the same time, the two paths are fused by summing features, thus preserving context and the spatial information for decoding part. This multi-learning-scale model is benefiting in Chest X-ray dataset from two different manufacturers (Montgomery and Shenzhen hospital). The DEFU-Net achieves the better performance than basic U-Net, residual U-Net, BCDU-Net, modified R2U-Net and modified attention R2U-Net. This model has proved the feasibility for mixed dataset. The open source code for this proposed framework will be public soon.