 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBSM loss: A superior way in modeling aleatory uncertainty of fine_grained classification
Jun 09, 2022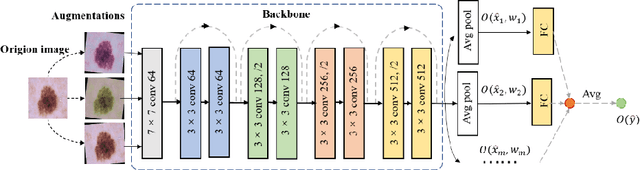
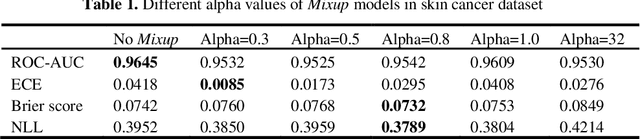
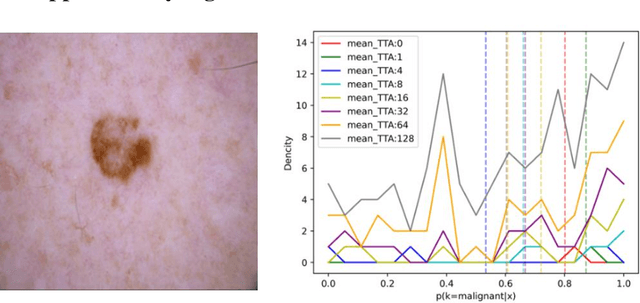
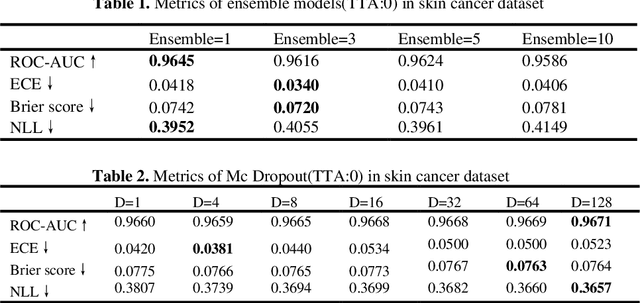
Artificial intelligence(AI)-assisted method had received much attention in the risk field such as disease diagnosis. Different from the classification of disease types, it is a fine-grained task to classify the medical images as benign or malignant. However, most research only focuses on improving the diagnostic accuracy and ignores the evaluation of model reliability, which limits its clinical application. For clinical practice, calibration presents major challenges in the low-data regime extremely for over-parametrized models and inherent noises. In particular, we discovered that modeling data-dependent uncertainty is more conducive to confidence calibrations. Compared with test-time augmentation(TTA), we proposed a modified Bootstrapping loss(BS loss) function with Mixup data augmentation strategy that can better calibrate predictive uncertainty and capture data distribution transformation without additional inference time. Our experiments indicated that BS loss with Mixup(BSM) model can halve the Expected Calibration Error(ECE) compared to standard data augmentation, deep ensemble and MC dropout. The correlation between uncertainty and similarity of in-domain data is up to -0.4428 under the BSM model. Additionally, the BSM model is able to perceive the semantic distance of out-of-domain data, demonstrating high potential in real-world clinical practice.
Residual Recurrent CRNN for End-to-End Optical Music Recognition on Monophonic Scores
Oct 26, 2020



Optical Music Recognition is a field that attempts to extract digital information from images of either the printed music scores or the handwritten music scores. One of the challenges of the Optical Music Recognition task is to transcript the symbols of the camera-captured images into digital music notations. Previous end-to-end model, based on deep learning, was developed as a Convolutional Recurrent Neural Network. However, it does not explore sufficient contextual information from full scales and there is still a large room for improvement. In this paper, we propose an innovative end-to-end framework that combines a block of Residual Recurrent Convolutional Neural Network with a recurrent Encoder-Decoder network to map a sequence of monophonic music symbols corresponding to the notations present in the image. The Residual Recurrent Convolutional block can improve the ability of the model to enrich the context information while the number of parameter will not be increasing. The experiment results were benchmarked against a publicly available dataset called CAMERA-PRIMUS. We evaluate the performances of our model on both the images with ideal conditions and that with non-ideal conditions. The experiments show that our approach surpass the state-of-the-art end-to-end method using Convolutional Recurrent Neural Network.