 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKV-CoRE: Benchmarking Data-Dependent Low-Rank Compressibility of KV-Caches in LLMs
Feb 05, 2026Large language models rely on kv-caches to avoid redundant computation during autoregressive decoding, but as context length grows, reading and writing the cache can quickly saturate GPU memory bandwidth. Recent work has explored KV-cache compression, yet most approaches neglect the data-dependent nature of kv-caches and their variation across layers. We introduce KV-CoRE KV-cache Compressibility by Rank Evaluation), an SVD-based method for quantifying the data-dependent low-rank compressibility of kv-caches. KV-CoRE computes the optimal low-rank approximation under the Frobenius norm and, being gradient-free and incremental, enables efficient dataset-level, layer-wise evaluation. Using this method, we analyze multiple models and datasets spanning five English domains and sixteen languages, uncovering systematic patterns that link compressibility to model architecture, training data, and language coverage. As part of this analysis, we employ the Normalized Effective Rank as a metric of compressibility and show that it correlates strongly with performance degradation under compression. Our study establishes a principled evaluation framework and the first large-scale benchmark of kv-cache compressibility in LLMs, offering insights for dynamic, data-aware compression and data-centric model development.
Accelerate Speculative Decoding with Sparse Computation in Verification
Dec 26, 2025Speculative decoding accelerates autoregressive language model inference by verifying multiple draft tokens in parallel. However, the verification stage often becomes the dominant computational bottleneck, especially for long-context inputs and mixture-of-experts (MoE) models. Existing sparsification methods are designed primarily for standard token-by-token autoregressive decoding to remove substantial computational redundancy in LLMs. This work systematically adopts different sparse methods on the verification stage of the speculative decoding and identifies structured redundancy across multiple dimensions. Based on these observations, we propose a sparse verification framework that jointly sparsifies attention, FFN, and MoE components during the verification stage to reduce the dominant computation cost. The framework further incorporates an inter-draft token and inter-layer retrieval reuse strategy to further reduce redundant computation without introducing additional training. Extensive experiments across summarization, question answering, and mathematical reasoning datasets demonstrate that the proposed methods achieve favorable efficiency-accuracy trade-offs, while maintaining stable acceptance length.
Ev-Trust: A Strategy Equilibrium Trust Mechanism for Evolutionary Games in LLM-Based Multi-Agent Services
Dec 18, 2025The rapid evolution of the Web toward an agent-centric paradigm, driven by large language models (LLMs), has enabled autonomous agents to reason, plan, and interact in complex decentralized environments. However, the openness and heterogeneity of LLM-based multi-agent systems also amplify the risks of deception, fraud, and misinformation, posing severe challenges to trust establishment and system robustness. To address this issue, we propose Ev-Trust, a strategy-equilibrium trust mechanism grounded in evolutionary game theory. This mechanism integrates direct trust, indirect trust, and expected revenue into a dynamic feedback structure that guides agents' behavioral evolution toward equilibria. Within a decentralized "Request-Response-Payment-Evaluation" service framework, Ev-Trust enables agents to adaptively adjust strategies, naturally excluding malicious participants while reinforcing high-quality collaboration. Furthermore, our theoretical derivation based on replicator dynamics equations proves the existence and stability of local evolutionary equilibria. Experimental results indicate that our approach effectively reflects agent trustworthiness in LLM-driven open service interaction scenarios, reduces malicious strategies, and increases collective revenue. We hope Ev-Trust can provide a new perspective on trust modeling for the agentic service web in group evolutionary game scenarios.
KGOT: Unified Knowledge Graph and Optimal Transport Pseudo-Labeling for Molecule-Protein Interaction Prediction
Dec 10, 2025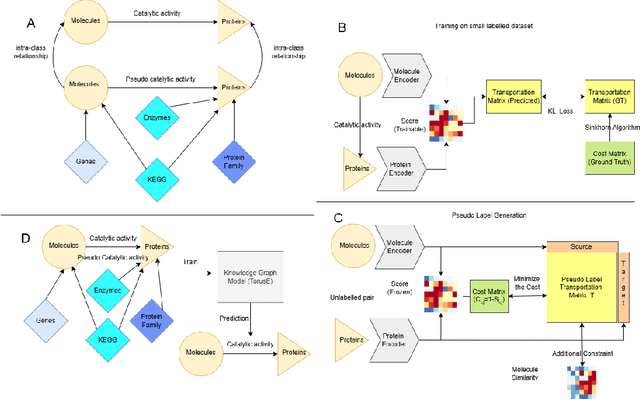
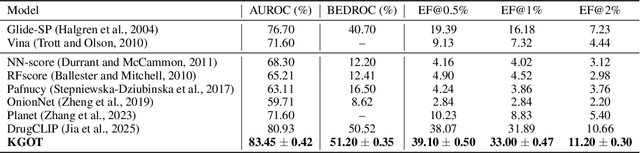
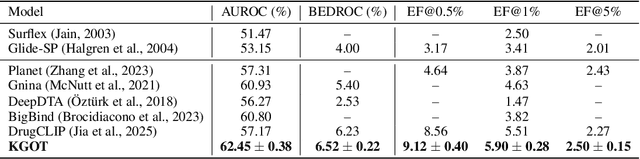
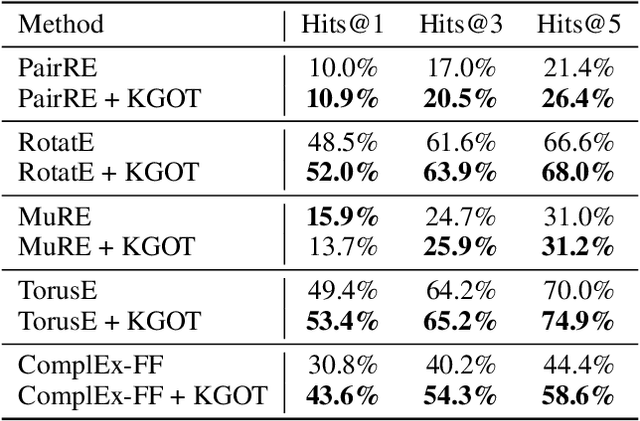
Predicting molecule-protein interactions (MPIs) is a fundamental task in computational biology, with crucial applications in drug discovery and molecular function annotation. However, existing MPI models face two major challenges. First, the scarcity of labeled molecule-protein pairs significantly limits model performance, as available datasets capture only a small fraction of biological relevant interactions. Second, most methods rely solely on molecular and protein features, ignoring broader biological context such as genes, metabolic pathways, and functional annotations that could provide essential complementary information. To address these limitations, our framework first aggregates diverse biological datasets, including molecular, protein, genes and pathway-level interactions, and then develop an optimal transport-based approach to generate high-quality pseudo-labels for unlabeled molecule-protein pairs, leveraging the underlying distribution of known interactions to guide label assignment. By treating pseudo-labeling as a mechanism for bridging disparate biological modalities, our approach enables the effective use of heterogeneous data to enhance MPI prediction. We evaluate our framework on multiple MPI datasets including virtual screening tasks and protein retrieval tasks, demonstrating substantial improvements over state-of-the-art methods in prediction accuracies and zero shot ability across unseen interactions. Beyond MPI prediction, our approach provides a new paradigm for leveraging diverse biological data sources to tackle problems traditionally constrained by single- or bi-modal learning, paving the way for future advances in computational biology and drug discovery.
MaskPrune: Mask-based LLM Pruning for Layer-wise Uniform Structures
Feb 19, 2025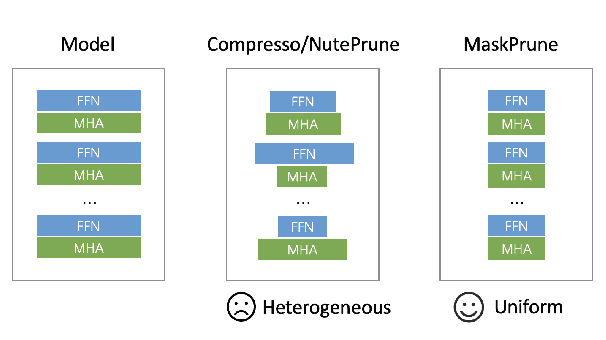
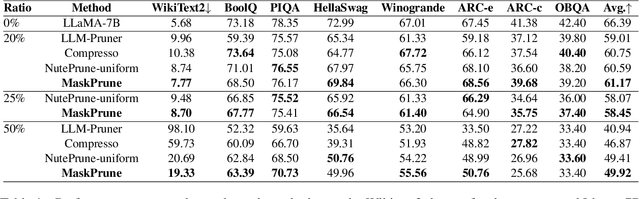
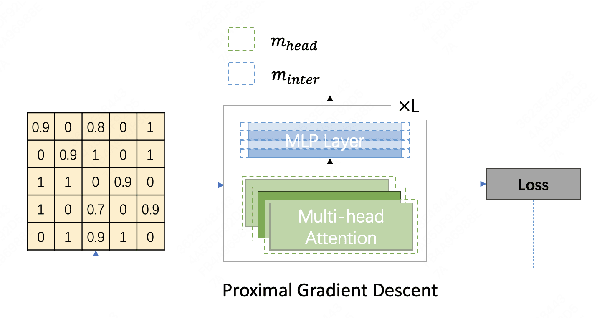

The remarkable performance of large language models (LLMs) in various language tasks has attracted considerable attention. However, the ever-increasing size of these models presents growing challenges for deployment and inference. Structured pruning, an effective model compression technique, is gaining increasing attention due to its ability to enhance inference efficiency. Nevertheless, most previous optimization-based structured pruning methods sacrifice the uniform structure across layers for greater flexibility to maintain performance. The heterogeneous structure hinders the effective utilization of off-the-shelf inference acceleration techniques and impedes efficient configuration for continued training. To address this issue, we propose a novel masking learning paradigm based on minimax optimization to obtain the uniform pruned structure by optimizing the masks under sparsity regularization. Extensive experimental results demonstrate that our method can maintain high performance while ensuring the uniformity of the pruned model structure, thereby outperforming existing SOTA methods.
QAQ: Quality Adaptive Quantization for LLM KV Cache
Mar 07, 2024



The emergence of LLMs has ignited a fresh surge of breakthroughs in NLP applications, particularly in domains such as question-answering systems and text generation. As the need for longer context grows, a significant bottleneck in model deployment emerges due to the linear expansion of the Key-Value (KV) cache with the context length. Existing methods primarily rely on various hypotheses, such as sorting the KV cache based on attention scores for replacement or eviction, to compress the KV cache and improve model throughput. However, heuristics used by these strategies may wrongly evict essential KV cache, which can significantly degrade model performance. In this paper, we propose QAQ, a Quality Adaptive Quantization scheme for the KV cache. We theoretically demonstrate that key cache and value cache exhibit distinct sensitivities to quantization, leading to the formulation of separate quantization strategies for their non-uniform quantization. Through the integration of dedicated outlier handling, as well as an improved attention-aware approach, QAQ achieves up to 10x the compression ratio of the KV cache size with a neglectable impact on model performance. QAQ significantly reduces the practical hurdles of deploying LLMs, opening up new possibilities for longer-context applications. The code is available at github.com/ClubieDong/KVCacheQuantization.
Learning Unnormalized Statistical Models via Compositional Optimization
Jun 13, 2023

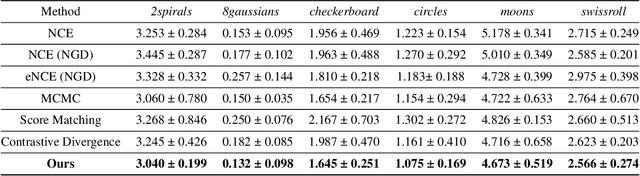

Learning unnormalized statistical models (e.g., energy-based models) is computationally challenging due to the complexity of handling the partition function. To eschew this complexity, noise-contrastive estimation~(NCE) has been proposed by formulating the objective as the logistic loss of the real data and the artificial noise. However, as found in previous works, NCE may perform poorly in many tasks due to its flat loss landscape and slow convergence. In this paper, we study it a direct approach for optimizing the negative log-likelihood of unnormalized models from the perspective of compositional optimization. To tackle the partition function, a noise distribution is introduced such that the log partition function can be written as a compositional function whose inner function can be estimated with stochastic samples. Hence, the objective can be optimized by stochastic compositional optimization algorithms. Despite being a simple method, we demonstrate that it is more favorable than NCE by (1) establishing a fast convergence rate and quantifying its dependence on the noise distribution through the variance of stochastic estimators; (2) developing better results for one-dimensional Gaussian mean estimation by showing our objective has a much favorable loss landscape and hence our method enjoys faster convergence; (3) demonstrating better performance on multiple applications, including density estimation, out-of-distribution detection, and real image generation.
Prompt Tuning based Adapter for Vision-Language Model Adaption
Mar 24, 2023Large pre-trained vision-language (VL) models have shown significant promise in adapting to various downstream tasks. However, fine-tuning the entire network is challenging due to the massive number of model parameters. To address this issue, efficient adaptation methods such as prompt tuning have been proposed. We explore the idea of prompt tuning with multi-task pre-trained initialization and find it can significantly improve model performance. Based on our findings, we introduce a new model, termed Prompt-Adapter, that combines pre-trained prompt tunning with an efficient adaptation network. Our approach beat the state-of-the-art methods in few-shot image classification on the public 11 datasets, especially in settings with limited data instances such as 1 shot, 2 shots, 4 shots, and 8 shots images. Our proposed method demonstrates the promise of combining prompt tuning and parameter-efficient networks for efficient vision-language model adaptation. The code is publicly available at: https://github.com/Jingchensun/prompt_adapter.