 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Human-level Intelligence via Human-like Whole-Body Manipulation
Jul 23, 2025Building general-purpose intelligent robots has long been a fundamental goal of robotics. A promising approach is to mirror the evolutionary trajectory of humans: learning through continuous interaction with the environment, with early progress driven by the imitation of human behaviors. Achieving this goal presents three core challenges: (1) designing safe robotic hardware with human-level physical capabilities; (2) developing an intuitive and scalable whole-body teleoperation interface for data collection; and (3) creating algorithms capable of learning whole-body visuomotor policies from human demonstrations. To address these challenges in a unified framework, we propose Astribot Suite, a robot learning suite for whole-body manipulation aimed at general daily tasks across diverse environments. We demonstrate the effectiveness of our system on a wide range of activities that require whole-body coordination, extensive reachability, human-level dexterity, and agility. Our results show that Astribot's cohesive integration of embodiment, teleoperation interface, and learning pipeline marks a significant step towards real-world, general-purpose whole-body robotic manipulation, laying the groundwork for the next generation of intelligent robots.
Learning Autonomous Ultrasound via Latent Task Representation and Robotic Skills Adaptation
Jul 25, 2023As medical ultrasound is becoming a prevailing examination approach nowadays, robotic ultrasound systems can facilitate the scanning process and prevent professional sonographers from repetitive and tedious work. Despite the recent progress, it is still a challenge to enable robots to autonomously accomplish the ultrasound examination, which is largely due to the lack of a proper task representation method, and also an adaptation approach to generalize learned skills across different patients. To solve these problems, we propose the latent task representation and the robotic skills adaptation for autonomous ultrasound in this paper. During the offline stage, the multimodal ultrasound skills are merged and encapsulated into a low-dimensional probability model through a fully self-supervised framework, which takes clinically demonstrated ultrasound images, probe orientations, and contact forces into account. During the online stage, the probability model will select and evaluate the optimal prediction. For unstable singularities, the adaptive optimizer fine-tunes them to near and stable predictions in high-confidence regions. Experimental results show that the proposed approach can generate complex ultrasound strategies for diverse populations and achieve significantly better quantitative results than our previous method.
PoseFusion: Robust Object-in-Hand Pose Estimation with SelectLSTM
Apr 10, 2023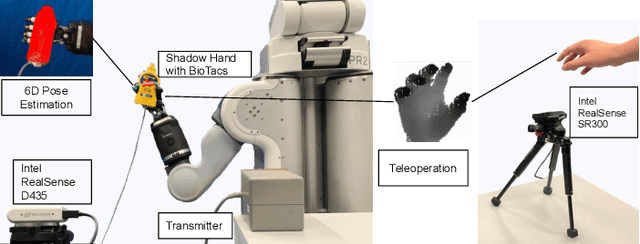
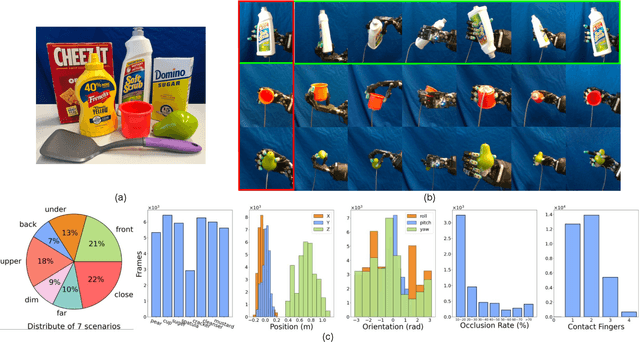

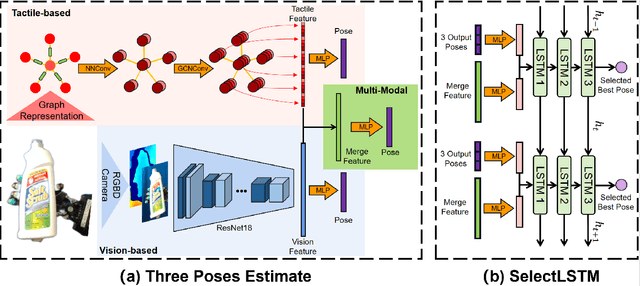
Accurate estimation of the relative pose between an object and a robot hand is critical for many manipulation tasks. However, most of the existing object-in-hand pose datasets use two-finger grippers and also assume that the object remains fixed in the hand without any relative movements, which is not representative of real-world scenarios. To address this issue, a 6D object-in-hand pose dataset is proposed using a teleoperation method with an anthropomorphic Shadow Dexterous hand. Our dataset comprises RGB-D images, proprioception and tactile data, covering diverse grasping poses, finger contact states, and object occlusions. To overcome the significant hand occlusion and limited tactile sensor contact in real-world scenarios, we propose PoseFusion, a hybrid multi-modal fusion approach that integrates the information from visual and tactile perception channels. PoseFusion generates three candidate object poses from three estimators (tactile only, visual only, and visuo-tactile fusion), which are then filtered by a SelectLSTM network to select the optimal pose, avoiding inferior fusion poses resulting from modality collapse. Extensive experiments demonstrate the robustness and advantages of our framework. All data and codes are available on the project website: https://elevenjiang1.github.io/ObjectInHand-Dataset/
Learning Grasp Ability Enhancement through Deep Shape Generation
Jun 19, 2022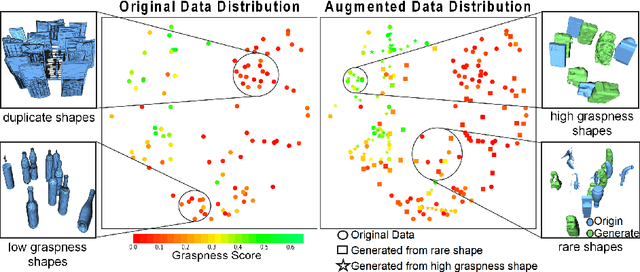
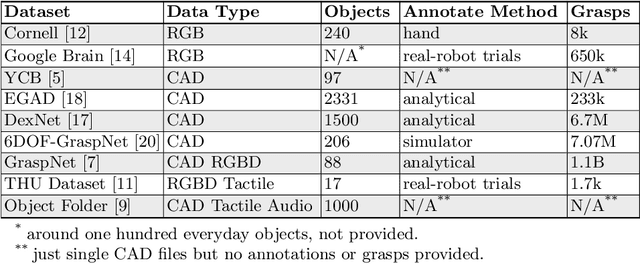
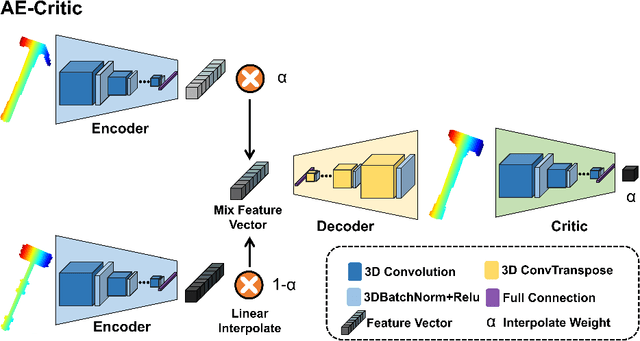
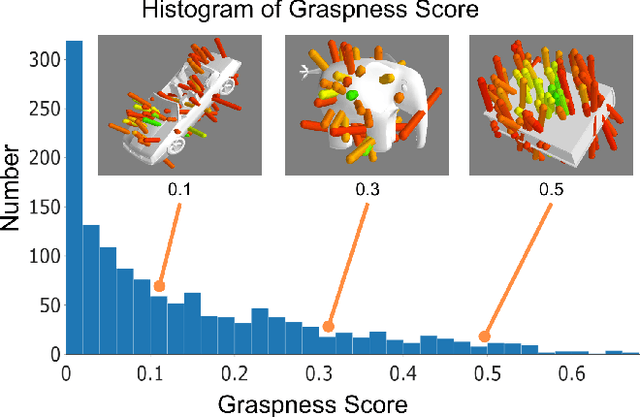
Data-driven especially deep learning-based approaches have become a dominant paradigm for robotic grasp planning during the past decade. However, the performance of these methods is greatly influenced by the quality of the training dataset available. In this paper, we propose a framework to generate object shapes to augment the grasping dataset and thus can improve the grasp ability of a pre-designed deep neural network. First, the object shapes are embedded into a low dimensional feature space using an encoder-decoder structure network. Then, the rarity and graspness scores are computed for each object shape using outlier detection and grasp quality criteria. Finally, new objects are generated in feature space leveraging the original high rarity and graspness score objects' feature. Experimental results show that the grasp ability of a deep-learning-based grasp planning network can be effectively improved with the generated object shapes.